 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTED-VITON: Transformer-Empowered Diffusion Models for Virtual Try-On
Paper and Code
Nov 26, 2024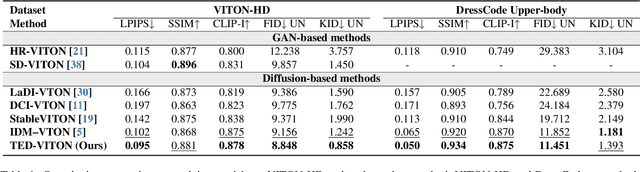
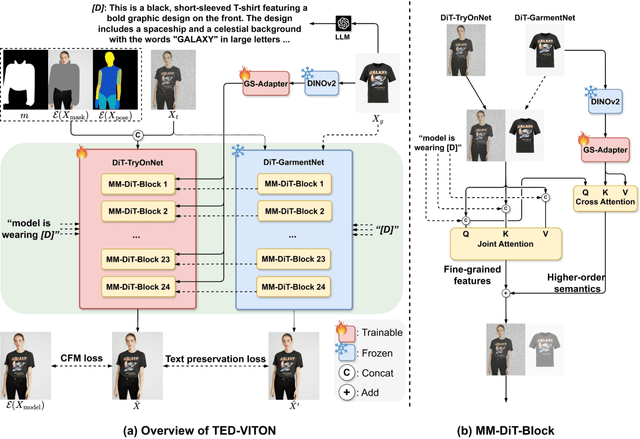


Recent advancements in Virtual Try-On (VTO) have demonstrated exceptional efficacy in generating realistic images and preserving garment details, largely attributed to the robust generative capabilities of text-to-image (T2I) diffusion backbones. However, the T2I models that underpin these methods have become outdated, thereby limiting the potential for further improvement in VTO. Additionally, current methods face notable challenges in accurately rendering text on garments without distortion and preserving fine-grained details, such as textures and material fidelity. The emergence of Diffusion Transformer (DiT) based T2I models has showcased impressive performance and offers a promising opportunity for advancing VTO. Directly applying existing VTO techniques to transformer-based T2I models is ineffective due to substantial architectural differences, which hinder their ability to fully leverage the models' advanced capabilities for improved text generation. To address these challenges and unlock the full potential of DiT-based T2I models for VTO, we propose TED-VITON, a novel framework that integrates a Garment Semantic (GS) Adapter for enhancing garment-specific features, a Text Preservation Loss to ensure accurate and distortion-free text rendering, and a constraint mechanism to generate prompts by optimizing Large Language Model (LLM). These innovations enable state-of-the-art (SOTA) performance in visual quality and text fidelity, establishing a new benchmark for VTO task.