 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
Mar 17, 2026Omni-modal large language models (OLMs) redefine human-machine interaction by natively integrating audio, vision, and text. However, existing OLM benchmarks remain anchored to static, accuracy-centric tasks, leaving a critical gap in assessing social interactivity, the fundamental capacity to navigate dynamic cues in natural dialogues. To this end, we propose SocialOmni, a comprehensive benchmark that operationalizes the evaluation of this conversational interactivity across three core dimensions: (i) speaker separation and identification (who is speaking), (ii) interruption timing control (when to interject), and (iii) natural interruption generation (how to phrase the interruption). SocialOmni features 2,000 perception samples and a quality-controlled diagnostic set of 209 interaction-generation instances with strict temporal and contextual constraints, complemented by controlled audio-visual inconsistency scenarios to test model robustness. We benchmarked 12 leading OLMs, which uncovers significant variance in their social-interaction capabilities across models. Furthermore, our analysis reveals a pronounced decoupling between a model's perceptual accuracy and its ability to generate contextually appropriate interruptions, indicating that understanding-centric metrics alone are insufficient to characterize conversational social competence. More encouragingly, these diagnostics from SocialOmni yield actionable signals for bridging the perception-interaction divide in future OLMs.
Event-Anchored Frame Selection for Effective Long-Video Understanding
Mar 01, 2026Massive frame redundancy and limited context window make efficient frame selection crucial for long-video understanding with large vision-language models (LVLMs). Prevailing approaches, however, adopt a flat sampling paradigm which treats the video as an unstructured collection of frames. In this paper, we introduce Event-Anchored Frame Selection (EFS), a hierarchical, event-aware pipeline. Leveraging self-supervised DINO embeddings, EFS first partitions the video stream into visually homogeneous temporal segments, which serve as proxies for semantic events. Within each event, it then selects the most query-relevant frame as an anchor. These anchors act as structural priors that guide a global refinement stage using an adaptive Maximal Marginal Relevance (MMR) scheme. This pipeline ensures the final keyframe set jointly optimizes for event coverage, query relevance, and visual diversity. As a training-free, plug-and-play module, EFS can be seamlessly integrated into off-the-shelf LVLMs, yielding substantial gains on challenging video understanding benchmarks. Specifically, when applied to LLaVA-Video-7B, EFS improves accuracy by 4.7%, 4.9%, and 8.8% on VideoMME, LongVideoBench, and MLVU, respectively.
Wavelet-based Frame Selection by Detecting Semantic Boundary for Long Video Understanding
Feb 28, 2026Frame selection is crucial due to high frame redundancy and limited context windows when applying Large Vision-Language Models (LVLMs) to long videos. Current methods typically select frames with high relevance to a given query, resulting in a disjointed set of frames that disregard the narrative structure of video. In this paper, we introduce Wavelet-based Frame Selection by Detecting Semantic Boundary (WFS-SB), a training-free framework that presents a new perspective: effective video understanding hinges not only on high relevance but, more importantly, on capturing semantic shifts - pivotal moments of narrative change that are essential to comprehending the holistic storyline of video. However, direct detection of abrupt changes in the query-frame similarity signal is often unreliable due to high-frequency noise arising from model uncertainty and transient visual variations. To address this, we leverage the wavelet transform, which provides an ideal solution through its multi-resolution analysis in both time and frequency domains. By applying this transform, we decompose the noisy signal into multiple scales and extract a clean semantic change signal from the coarsest scale. We identify the local extrema of this signal as semantic boundaries, which segment the video into coherent clips. Building on this, WFS-SB comprises a two-stage strategy: first, adaptively allocating a frame budget to each clip based on a composite importance score; and second, within each clip, employing the Maximal Marginal Relevance approach to select a diverse yet relevant set of frames. Extensive experiments show that WFS-SB significantly boosts LVLM performance, e.g., improving accuracy by 5.5% on VideoMME, 9.5% on MLVU, and 6.2% on LongVideoBench, consistently outperforming state-of-the-art methods.
CrystaL: Spontaneous Emergence of Visual Latents in MLLMs
Feb 24, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance by integrating powerful language backbones with large-scale visual encoders. Among these, latent Chain-of-Thought (CoT) methods enable implicit reasoning in continuous hidden states, facilitating seamless vision-language integration and faster inference. However, existing heuristically predefined supervision signals in latent CoT provide limited guidance for preserving critical visual information in intermediate latent states. To address this limitation, we propose CrystaL (Crystallized Latent Reasoning), a single-stage framework with two paths to process intact and corrupted images, respectively. By explicitly aligning the attention patterns and prediction distributions across the two paths, CrystaL crystallizes latent representations into task-relevant visual semantics, without relying on auxiliary annotations or external modules. Extensive experiments on perception-intensive benchmarks demonstrate that CrystaL consistently outperforms state-of-the-art baselines, achieving substantial gains in fine-grained visual understanding while maintaining robust reasoning capabilities.
Unleashing MLLMs on the Edge: A Unified Framework for Cross-Modal ReID via Adaptive SVD Distillation
Feb 13, 2026Practical cloud-edge deployment of Cross-Modal Re-identification (CM-ReID) faces challenges due to maintaining a fragmented ecosystem of specialized cloud models for diverse modalities. While Multi-Modal Large Language Models (MLLMs) offer strong unification potential, existing approaches fail to adapt them into a single end-to-end backbone and lack effective knowledge distillation strategies for edge deployment. To address these limitations, we propose MLLMEmbed-ReID, a unified framework based on a powerful cloud-edge architecture. First, we adapt a foundational MLLM into a state-of-the-art cloud model. We leverage instruction-based prompting to guide the MLLM in generating a unified embedding space across RGB, infrared, sketch, and text modalities. This model is then trained efficiently with a hierarchical Low-Rank Adaptation finetuning (LoRA-SFT) strategy, optimized under a holistic cross-modal alignment objective. Second, to deploy its knowledge onto an edge-native student, we introduce a novel distillation strategy motivated by the low-rank property in the teacher's feature space. To prioritize essential information, this method employs a Principal Component Mapping loss, while relational structures are preserved via a Feature Relation loss. Our lightweight edge-based model achieves state-of-the-art performance on multiple visual CM-ReID benchmarks, while its cloud-based counterpart excels across all CM-ReID benchmarks. The MLLMEmbed-ReID framework thus presents a complete and effective solution for deploying unified MLLM-level intelligence on resource-constrained devices. The code and models will be open-sourced soon.
Continuous Semi-Implicit Models
Jun 07, 2025Semi-implicit distributions have shown great promise in variational inference and generative modeling. Hierarchical semi-implicit models, which stack multiple semi-implicit layers, enhance the expressiveness of semi-implicit distributions and can be used to accelerate diffusion models given pretrained score networks. However, their sequential training often suffers from slow convergence. In this paper, we introduce CoSIM, a continuous semi-implicit model that extends hierarchical semi-implicit models into a continuous framework. By incorporating a continuous transition kernel, CoSIM enables efficient, simulation-free training. Furthermore, we show that CoSIM achieves consistency with a carefully designed transition kernel, offering a novel approach for multistep distillation of generative models at the distributional level. Extensive experiments on image generation demonstrate that CoSIM performs on par or better than existing diffusion model acceleration methods, achieving superior performance on FD-DINOv2.
Variational Autoencoding Discrete Diffusion with Enhanced Dimensional Correlations Modeling
May 23, 2025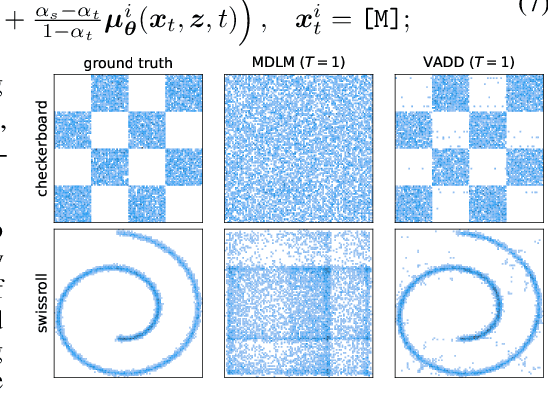
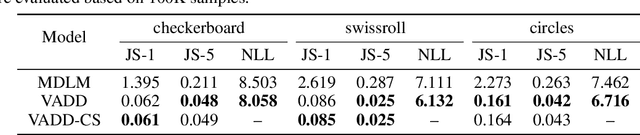
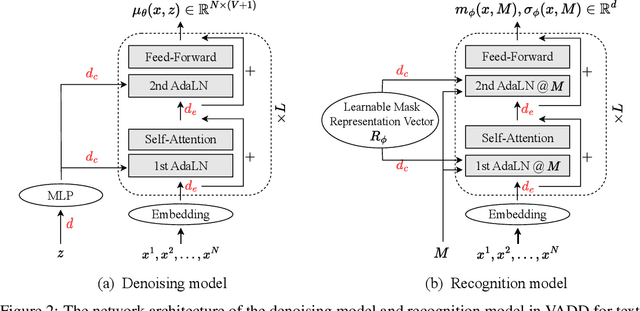

Discrete diffusion models have recently shown great promise for modeling complex discrete data, with masked diffusion models (MDMs) offering a compelling trade-off between quality and generation speed. MDMs denoise by progressively unmasking multiple dimensions from an all-masked input, but their performance can degrade when using few denoising steps due to limited modeling of inter-dimensional dependencies. In this paper, we propose Variational Autoencoding Discrete Diffusion (VADD), a novel framework that enhances discrete diffusion with latent variable modeling to implicitly capture correlations among dimensions. By introducing an auxiliary recognition model, VADD enables stable training via variational lower bounds maximization and amortized inference over the training set. Our approach retains the efficiency of traditional MDMs while significantly improving sample quality, especially when the number of denoising steps is small. Empirical results on 2D toy data, pixel-level image generation, and text generation demonstrate that VADD consistently outperforms MDM baselines.
DuckSegmentation: A segmentation model based on the AnYue Hemp Duck Dataset
Mar 27, 2025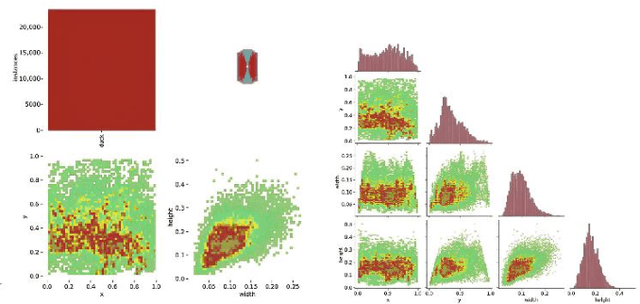

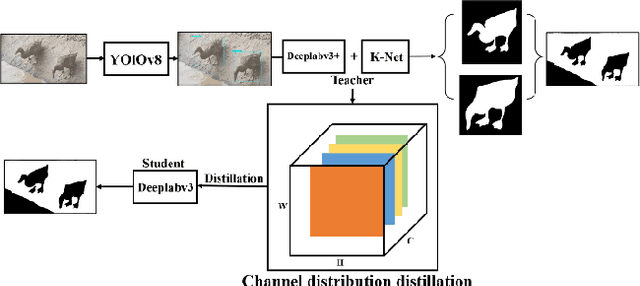

The modernization of smart farming is a way to improve agricultural production efficiency, and improve the agricultural production environment. Although many large models have achieved high accuracy in the task of object recognition and segmentation, they cannot really be put into use in the farming industry due to their own poor interpretability and limitations in computational volume. In this paper, we built AnYue Shelduck Dateset, which contains a total of 1951 Shelduck datasets, and performed target detection and segmentation annotation with the help of professional annotators. Based on AnYue ShelduckDateset, this paper describes DuckProcessing, an efficient and powerful module for duck identification based on real shelduckfarms. First of all, using the YOLOv8 module designed to divide the mahjong between them, Precision reached 98.10%, Recall reached 96.53% and F1 score reached 0.95 on the test set. Again using the DuckSegmentation segmentation model, DuckSegmentation reached 96.43% mIoU. Finally, the excellent DuckSegmentation was used as the teacher model, and through knowledge distillation, Deeplabv3 r50 was used as the student model, and the final student model achieved 94.49% mIoU on the test set. The method provides a new way of thinking in practical sisal duck smart farming.
PhyloVAE: Unsupervised Learning of Phylogenetic Trees via Variational Autoencoders
Feb 07, 2025Learning informative representations of phylogenetic tree structures is essential for analyzing evolutionary relationships. Classical distance-based methods have been widely used to project phylogenetic trees into Euclidean space, but they are often sensitive to the choice of distance metric and may lack sufficient resolution. In this paper, we introduce phylogenetic variational autoencoders (PhyloVAEs), an unsupervised learning framework designed for representation learning and generative modeling of tree topologies. Leveraging an efficient encoding mechanism inspired by autoregressive tree topology generation, we develop a deep latent-variable generative model that facilitates fast, parallelized topology generation. PhyloVAE combines this generative model with a collaborative inference model based on learnable topological features, allowing for high-resolution representations of phylogenetic tree samples. Extensive experiments demonstrate PhyloVAE's robust representation learning capabilities and fast generation of phylogenetic tree topologies.
Provable Sample-Efficient Transfer Learning Conditional Diffusion Models via Representation Learning
Feb 06, 2025


While conditional diffusion models have achieved remarkable success in various applications, they require abundant data to train from scratch, which is often infeasible in practice. To address this issue, transfer learning has emerged as an essential paradigm in small data regimes. Despite its empirical success, the theoretical underpinnings of transfer learning conditional diffusion models remain unexplored. In this paper, we take the first step towards understanding the sample efficiency of transfer learning conditional diffusion models through the lens of representation learning. Inspired by practical training procedures, we assume that there exists a low-dimensional representation of conditions shared across all tasks. Our analysis shows that with a well-learned representation from source tasks, the samplecomplexity of target tasks can be reduced substantially. In addition, we investigate the practical implications of our theoretical results in several real-world applications of conditional diffusion models. Numerical experiments are also conducted to verify our results.