 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Tree Probability Estimation with Stochastic Optimization and Variance Reduction
Sep 09, 2024Probability estimation of tree topologies is one of the fundamental tasks in phylogenetic inference. The recently proposed subsplit Bayesian networks (SBNs) provide a powerful probabilistic graphical model for tree topology probability estimation by properly leveraging the hierarchical structure of phylogenetic trees. However, the expectation maximization (EM) method currently used for learning SBN parameters does not scale up to large data sets. In this paper, we introduce several computationally efficient methods for training SBNs and show that variance reduction could be the key for better performance. Furthermore, we also introduce the variance reduction technique to improve the optimization of SBN parameters for variational Bayesian phylogenetic inference (VBPI). Extensive synthetic and real data experiments demonstrate that our methods outperform previous baseline methods on the tasks of tree topology probability estimation as well as Bayesian phylogenetic inference using SBNs.
TGNN: A Joint Semi-supervised Framework for Graph-level Classification
Apr 23, 2023This paper studies semi-supervised graph classification, a crucial task with a wide range of applications in social network analysis and bioinformatics. Recent works typically adopt graph neural networks to learn graph-level representations for classification, failing to explicitly leverage features derived from graph topology (e.g., paths). Moreover, when labeled data is scarce, these methods are far from satisfactory due to their insufficient topology exploration of unlabeled data. We address the challenge by proposing a novel semi-supervised framework called Twin Graph Neural Network (TGNN). To explore graph structural information from complementary views, our TGNN has a message passing module and a graph kernel module. To fully utilize unlabeled data, for each module, we calculate the similarity of each unlabeled graph to other labeled graphs in the memory bank and our consistency loss encourages consistency between two similarity distributions in different embedding spaces. The two twin modules collaborate with each other by exchanging instance similarity knowledge to fully explore the structure information of both labeled and unlabeled data. We evaluate our TGNN on various public datasets and show that it achieves strong performance.
ARGO: Modeling Heterogeneity in E-commerce Recommendation
Sep 14, 2021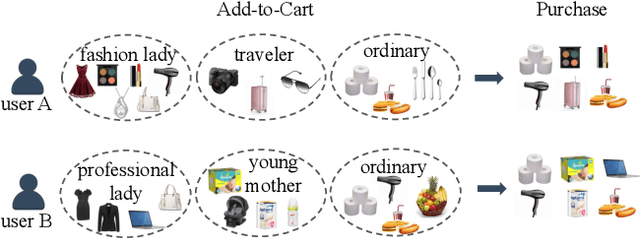
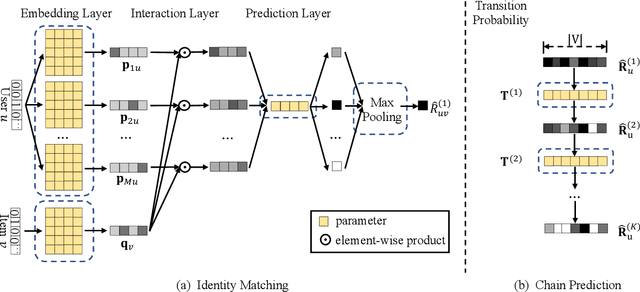
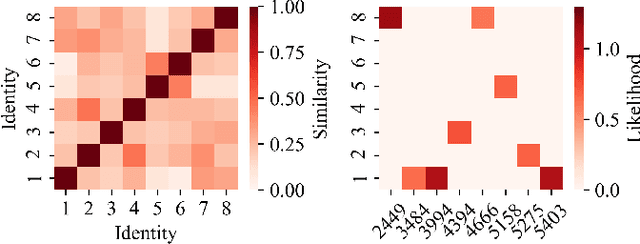
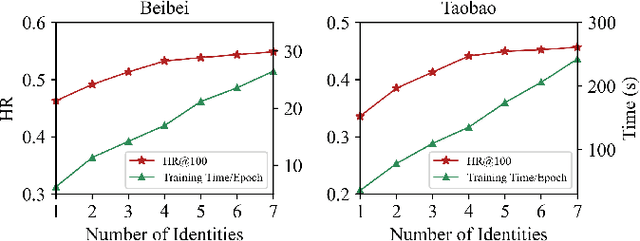
Nowadays, E-commerce is increasingly integrated into our daily lives. Meanwhile, shopping process has also changed incrementally from one behavior (purchase) to multiple behaviors (such as view, carting and purchase). Therefore, utilizing interaction data of auxiliary behavior data draws a lot of attention in the E-commerce recommender systems. However, all existing models ignore two kinds of intrinsic heterogeneity which are helpful to capture the difference of user preferences and the difference of item attributes. First (intra-heterogeneity), each user has multiple social identities with otherness, and these different identities can result in quite different interaction preferences. Second (inter-heterogeneity), each item can transfer an item-specific percentage of score from low-level behavior to high-level behavior for the gradual relationship among multiple behaviors. Thus, the lack of consideration of these heterogeneities damages recommendation rank performance. To model the above heterogeneities, we propose a novel method named intra- and inter-heterogeneity recommendation model (ARGO). Specifically, we embed each user into multiple vectors representing the user's identities, and the maximum of identity scores indicates the interaction preference. Besides, we regard the item-specific transition percentage as trainable transition probability between different behaviors. Extensive experiments on two real-world datasets show that ARGO performs much better than the state-of-the-art in multi-behavior scenarios.
Neighborhood Consensus Contrastive Learning for Backward-Compatible Representation
Sep 09, 2021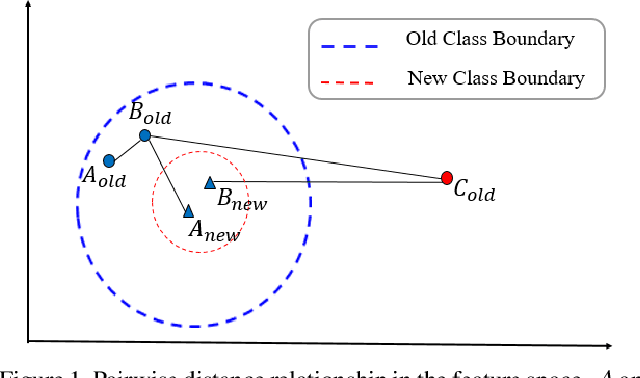
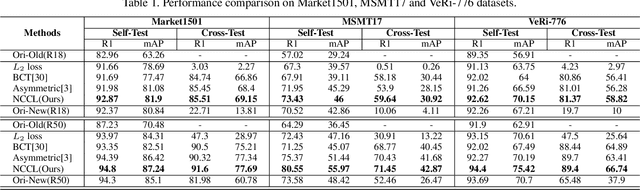
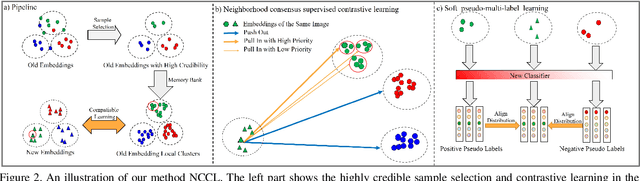
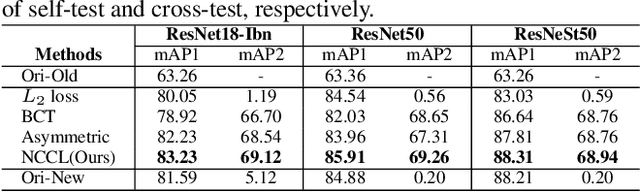
In object re-identification (ReID), the development of deep learning techniques often involves model updates and deployment. It is unbearable to re-embedding and re-index with the system suspended when deploying new models. Therefore, backward-compatible representation is proposed to enable "new" features to be compared with "old" features directly, which means that the database is active when there are both "new" and "old" features in it. Thus we can scroll-refresh the database or even do nothing on the database to update. The existing backward-compatible methods either require a strong overlap between old and new training data or simply conduct constraints at the instance level. Thus they are difficult in handling complicated cluster structures and are limited in eliminating the impact of outliers in old embeddings, resulting in a risk of damaging the discriminative capability of new features. In this work, we propose a Neighborhood Consensus Contrastive Learning (NCCL) method. With no assumptions about the new training data, we estimate the sub-cluster structures of old embeddings. A new embedding is constrained with multiple old embeddings in both embedding space and discrimination space at the sub-class level. The effect of outliers diminished, as the multiple samples serve as "mean teachers". Besides, we also propose a scheme to filter the old embeddings with low credibility, further improving the compatibility robustness. Our method ensures backward compatibility without impairing the accuracy of the new model. And it can even improve the new model's accuracy in most scenarios.
DNA-GCN: Graph convolutional networks for predicting DNA-protein binding
Jun 02, 2021Predicting DNA-protein binding is an important and classic problem in bioinformatics. Convolutional neural networks have outperformed conventional methods in modeling the sequence specificity of DNA-protein binding. However, none of the studies has utilized graph convolutional networks for motif inference. In this work, we propose to use graph convolutional networks for motif inference. We build a sequence k-mer graph for the whole dataset based on k-mer co-occurrence and k-mer sequence relationship and then learn DNA Graph Convolutional Network (DNA-GCN) for the whole dataset. Our DNA-GCN is initialized with a one-hot representation for all nodes, and it then jointly learns the embeddings for both k-mers and sequences, as supervised by the known labels of sequences. We evaluate our model on 50 datasets from ENCODE. DNA-GCN shows its competitive performance compared with the baseline model. Besides, we analyze our model and design several different architectures to help fit different datasets.
* 10 pages, 3 figures
Criterion-based Heterogeneous Collaborative Filtering for Multi-behavior Implicit Recommendation
May 28, 2021

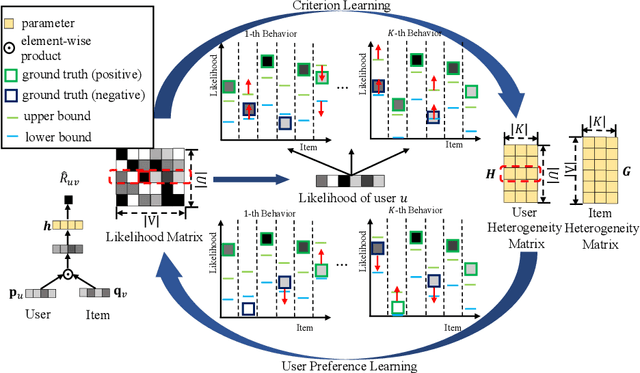

With the increasing scale and diversification of interaction behaviors in E-commerce, more and more researchers pay attention to multi-behavior recommender systems that utilize interaction data of other auxiliary behaviors such as view and cart. To address these challenges in heterogeneous scenarios, non-sampling methods have shown superiority over negative sampling methods. However, two observations are usually ignored in existing state-of-the-art non-sampling methods based on binary regression: (1) users have different preference strengths for different items, so they cannot be measured simply by binary implicit data; (2) the dependency across multiple behaviors varies for different users and items. To tackle the above issue, we propose a novel non-sampling learning framework named \underline{C}riterion-guided \underline{H}eterogeneous \underline{C}ollaborative \underline{F}iltering (CHCF). CHCF introduces both upper and lower bounds to indicate selection criteria, which will guide user preference learning. Besides, CHCF integrates criterion learning and user preference learning into a unified framework, which can be trained jointly for the interaction prediction on target behavior. We further theoretically demonstrate that the optimization of Collaborative Metric Learning can be approximately achieved by CHCF learning framework in a non-sampling form effectively. Extensive experiments on two real-world datasets show that CHCF outperforms the state-of-the-art methods in heterogeneous scenarios.
Deep Unsupervised Hashing by Distilled Smooth Guidance
May 13, 2021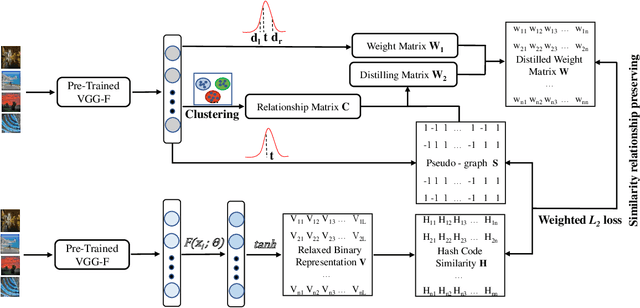
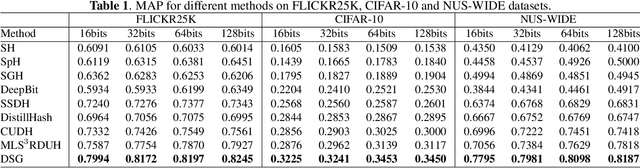

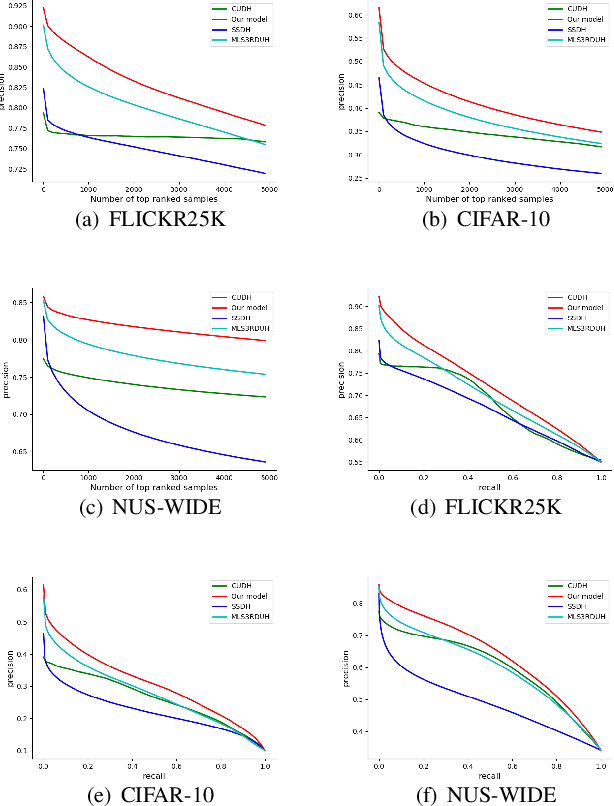
Hashing has been widely used in approximate nearest neighbor search for its storage and computational efficiency. Deep supervised hashing methods are not widely used because of the lack of labeled data, especially when the domain is transferred. Meanwhile, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable similarity signals. To tackle this problem, we propose a novel deep unsupervised hashing method, namely Distilled Smooth Guidance (DSG), which can learn a distilled dataset consisting of similarity signals as well as smooth confidence signals. To be specific, we obtain the similarity confidence weights based on the initial noisy similarity signals learned from local structures and construct a priority loss function for smooth similarity-preserving learning. Besides, global information based on clustering is utilized to distill the image pairs by removing contradictory similarity signals. Extensive experiments on three widely used benchmark datasets show that the proposed DSG consistently outperforms the state-of-the-art search methods.
* 7 pages, 3 figures
Graph Contrastive Clustering
Apr 03, 2021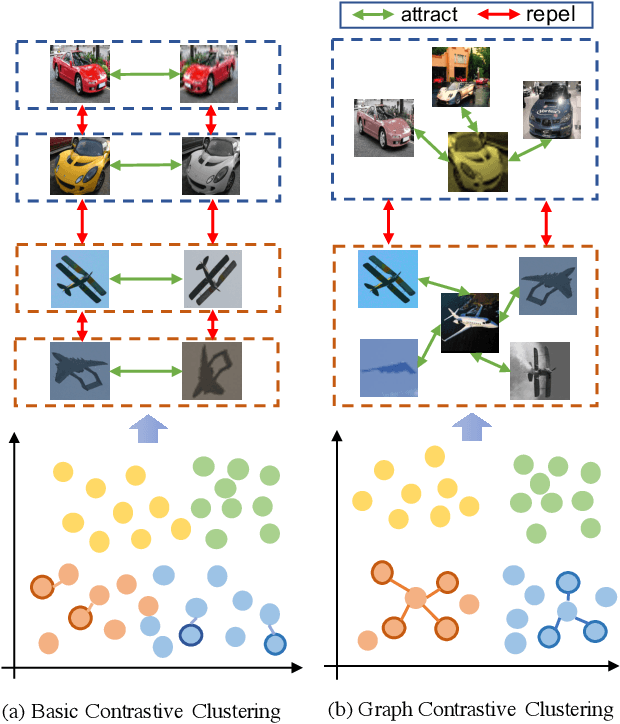
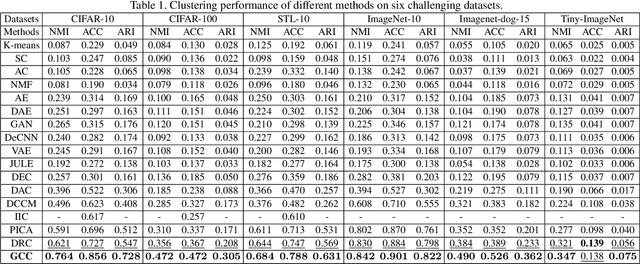
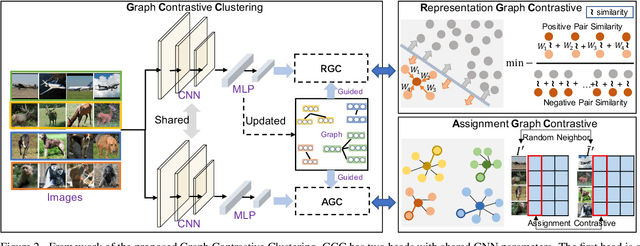
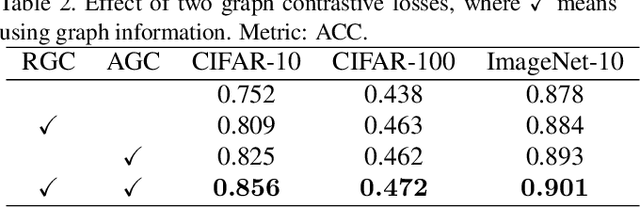
Recently, some contrastive learning methods have been proposed to simultaneously learn representations and clustering assignments, achieving significant improvements. However, these methods do not take the category information and clustering objective into consideration, thus the learned representations are not optimal for clustering and the performance might be limited. Towards this issue, we first propose a novel graph contrastive learning framework, which is then applied to the clustering task and we come up with the Graph Constrastive Clustering~(GCC) method. Different from basic contrastive clustering that only assumes an image and its augmentation should share similar representation and clustering assignments, we lift the instance-level consistency to the cluster-level consistency with the assumption that samples in one cluster and their augmentations should all be similar. Specifically, on the one hand, the graph Laplacian based contrastive loss is proposed to learn more discriminative and clustering-friendly features. On the other hand, a novel graph-based contrastive learning strategy is proposed to learn more compact clustering assignments. Both of them incorporate the latent category information to reduce the intra-cluster variance while increasing the inter-cluster variance. Experiments on six commonly used datasets demonstrate the superiority of our proposed approach over the state-of-the-art methods.
CIMON: Towards High-quality Hash Codes
Nov 05, 2020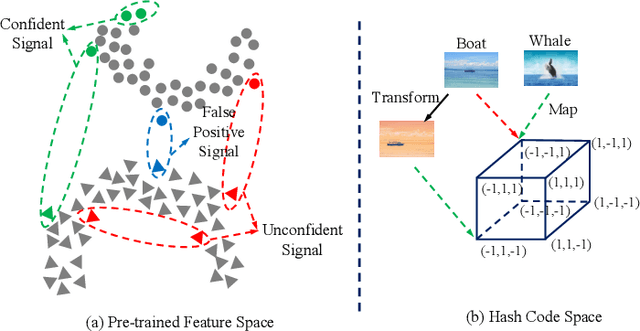
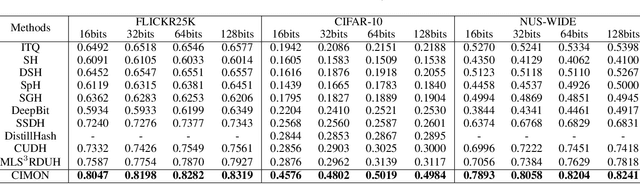
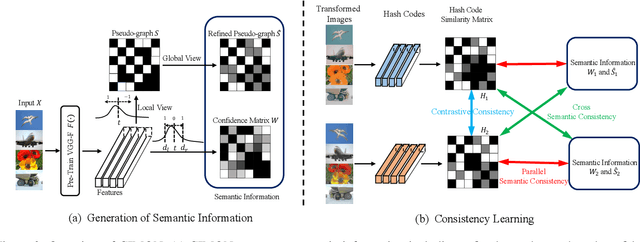
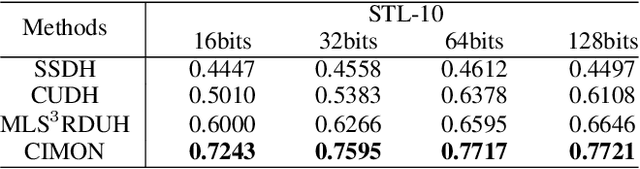
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
A Survey on Deep Hashing Methods
Mar 04, 2020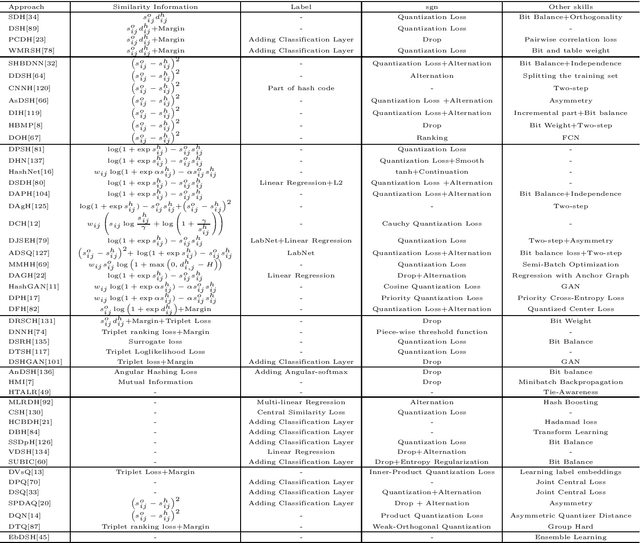
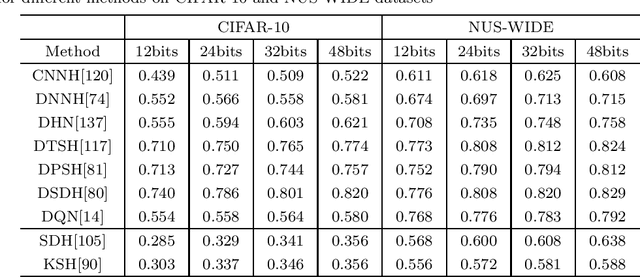
Nearest neighbor search is to find the data points in the database such that the distances from them to the query are the smallest, which is a fundamental problem in various domains, such as computer vision, recommendation systems and machine learning. Hashing is one of the most widely used method for its computational and storage efficiency. With the development of deep learning, deep hashing methods show more advantages than traditional methods. In this paper, we present a comprehensive survey of the deep hashing algorithms. Based on the loss function, we categorize deep supervised hashing methods according to the manners of preserving the similarities into: pairwise similarity preserving, multiwise similarity preserving, implicit similarity preserving, as well as quantization. In addition, we also introduce some other topics such as deep unsupervised hashing and multi-modal deep hashing methods. Meanwhile, we also present some commonly used public datasets and the scheme to measure the performance of deep hashing algorithms. Finally, we discussed some potential research directions in the conclusion.