 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-temporal Supervised Remote Change Detection for Domain Generalization
Apr 19, 2024

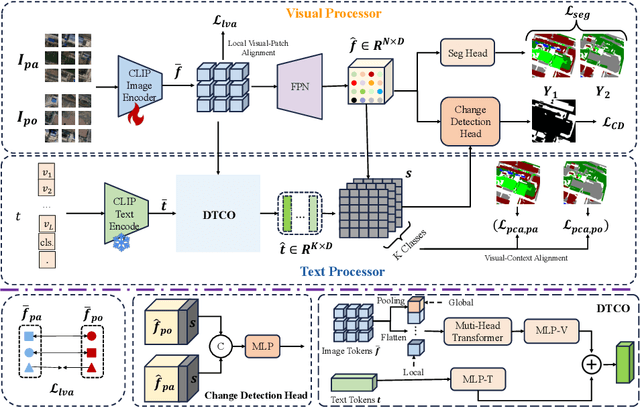

Change detection is widely applied in remote sensing image analysis. Existing methods require training models separately for each dataset, which leads to poor domain generalization. Moreover, these methods rely heavily on large amounts of high-quality pair-labelled data for training, which is expensive and impractical. In this paper, we propose a multimodal contrastive learning (ChangeCLIP) based on visual-language pre-training for change detection domain generalization. Additionally, we propose a dynamic context optimization for prompt learning. Meanwhile, to address the data dependency issue of existing methods, we introduce a single-temporal and controllable AI-generated training strategy (SAIN). This allows us to train the model using a large number of single-temporal images without image pairs in the real world, achieving excellent generalization. Extensive experiments on series of real change detection datasets validate the superiority and strong generalization of ChangeCLIP, outperforming state-of-the-art change detection methods. Code will be available.
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Mar 18, 2024In the field of multi-class anomaly detection, reconstruction-based methods derived from single-class anomaly detection face the well-known challenge of ``learning shortcuts'', wherein the model fails to learn the patterns of normal samples as it should, opting instead for shortcuts such as identity mapping or artificial noise elimination. Consequently, the model becomes unable to reconstruct genuine anomalies as normal instances, resulting in a failure of anomaly detection. To counter this issue, we present a novel unified feature reconstruction-based anomaly detection framework termed RLR (Reconstruct features from a Learnable Reference representation). Unlike previous methods, RLR utilizes learnable reference representations to compel the model to learn normal feature patterns explicitly, thereby prevents the model from succumbing to the ``learning shortcuts'' issue. Additionally, RLR incorporates locality constraints into the learnable reference to facilitate more effective normal pattern capture and utilizes a masked learnable key attention mechanism to enhance robustness. Evaluation of RLR on the 15-category MVTec-AD dataset and the 12-category VisA dataset shows superior performance compared to state-of-the-art methods under the unified setting. The code of RLR will be publicly available.