 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Search Agent with One Line of Code
Mar 10, 2026Tool-based Agentic Reinforcement Learning (TARL) has emerged as a promising paradigm for training search agents to interact with external tools for a multi-turn information-seeking process autonomously. However, we identify a critical training instability that leads to catastrophic model collapse: Importance Sampling Distribution Drift(ISDD). In Group Relative Policy Optimization(GRPO), a widely adopted TARL algorithm, ISDD manifests as a precipitous decline in the importance sampling ratios, which nullifies gradient updates and triggers irreversible training failure. To address this, we propose \textbf{S}earch \textbf{A}gent \textbf{P}olicy \textbf{O}ptimization (\textbf{SAPO}), which stabilizes training via a conditional token-level KL constraint. Unlike hard clipping, which ignores distributional divergence, SAPO selectively penalizes the KL divergence between the current and old policies. Crucially, this penalty is applied only to positive tokens with low probabilities where the policy has shifted excessively, thereby preventing distribution drift while preserving gradient flow. Remarkably, SAPO requires only one-line code modification to standard GRPO, ensuring immediate deployability. Extensive experiments across seven QA benchmarks demonstrate that SAPO achieves \textbf{+10.6\% absolute improvement} (+31.5\% relative) over Search-R1, yielding consistent gains across varying model scales (1.5B, 14B) and families (Qwen, LLaMA).
LLaVA-VSD: Large Language-and-Vision Assistant for Visual Spatial Description
Aug 09, 2024



Visual Spatial Description (VSD) aims to generate texts that describe the spatial relationships between objects within images. Traditional visual spatial relationship classification (VSRC) methods typically output the spatial relationship between two objects in an image, often neglecting world knowledge and lacking general language capabilities. In this paper, we propose a Large Language-and-Vision Assistant for Visual Spatial Description, named LLaVA-VSD, which is designed for the classification, description, and open-ended description of visual spatial relationships. Specifically, the model first constructs a VSD instruction-following dataset using given figure-caption pairs for the three tasks. It then employs LoRA to fine-tune a Large Language and Vision Assistant for VSD, which has 13 billion parameters and supports high-resolution images. Finally, a large language model (Qwen-2) is used to refine the generated sentences, enhancing their diversity and accuracy. LLaVA-VSD demonstrates excellent multimodal conversational capabilities and can follow open-ended instructions to assist with inquiries about object relationships in images.
Efficient Multimodal Large Language Models: A Survey
May 17, 2024



In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Generalized Category Discovery in Semantic Segmentation
Nov 20, 2023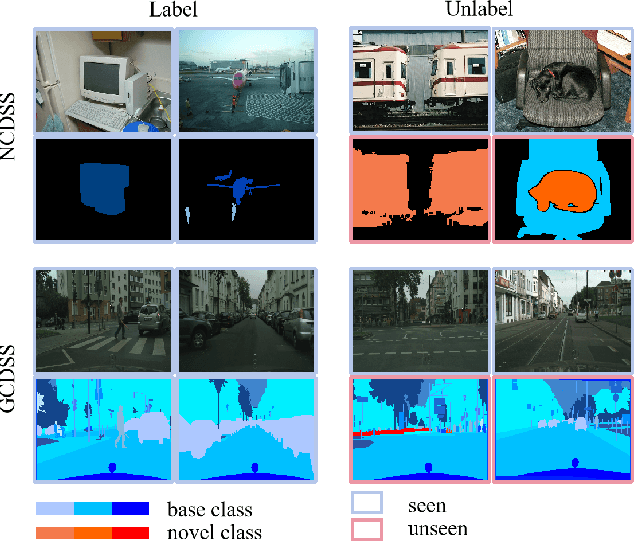
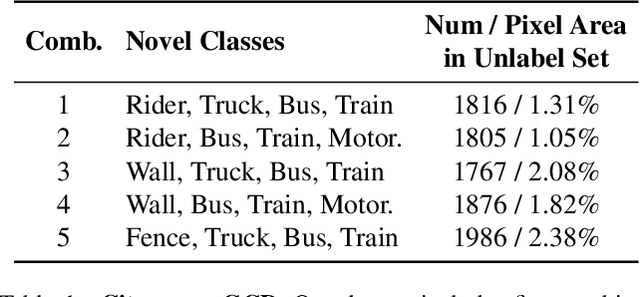
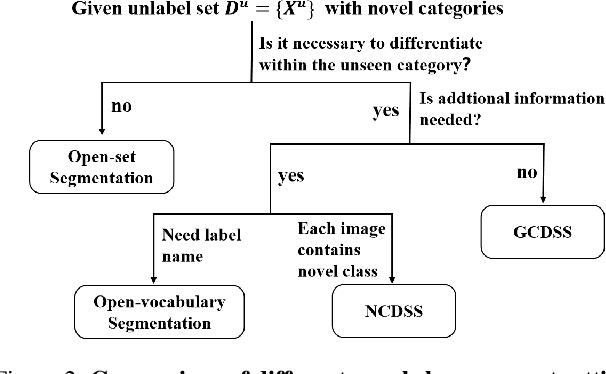

This paper explores a novel setting called Generalized Category Discovery in Semantic Segmentation (GCDSS), aiming to segment unlabeled images given prior knowledge from a labeled set of base classes. The unlabeled images contain pixels of the base class or novel class. In contrast to Novel Category Discovery in Semantic Segmentation (NCDSS), there is no prerequisite for prior knowledge mandating the existence of at least one novel class in each unlabeled image. Besides, we broaden the segmentation scope beyond foreground objects to include the entire image. Existing NCDSS methods rely on the aforementioned priors, making them challenging to truly apply in real-world situations. We propose a straightforward yet effective framework that reinterprets the GCDSS challenge as a task of mask classification. Additionally, we construct a baseline method and introduce the Neighborhood Relations-Guided Mask Clustering Algorithm (NeRG-MaskCA) for mask categorization to address the fragmentation in semantic representation. A benchmark dataset, Cityscapes-GCD, derived from the Cityscapes dataset, is established to evaluate the GCDSS framework. Our method demonstrates the feasibility of the GCDSS problem and the potential for discovering and segmenting novel object classes in unlabeled images. We employ the generated pseudo-labels from our approach as ground truth to supervise the training of other models, thereby enabling them with the ability to segment novel classes. It paves the way for further research in generalized category discovery, broadening the horizons of semantic segmentation and its applications. For details, please visit https://github.com/JethroPeng/GCDSS