 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Evaluation Benchmarks for NLP Models
Paper and Code
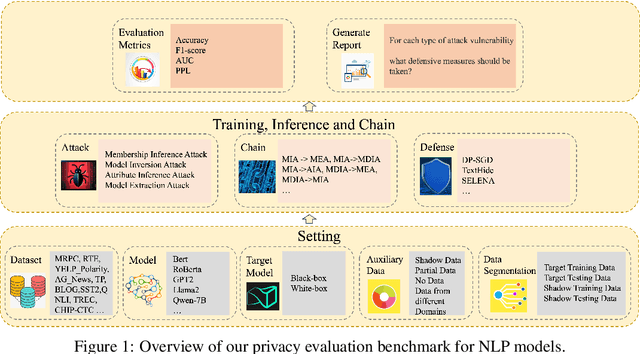
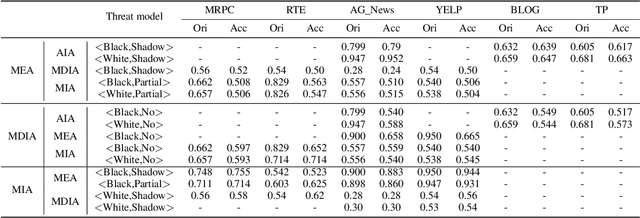
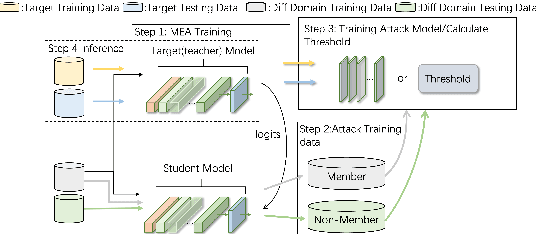
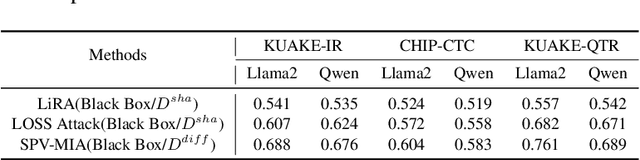
By inducing privacy attacks on NLP models, attackers can obtain sensitive information such as training data and model parameters, etc. Although researchers have studied, in-depth, several kinds of attacks in NLP models, they are non-systematic analyses. It lacks a comprehensive understanding of the impact caused by the attacks. For example, we must consider which scenarios can apply to which attacks, what the common factors are that affect the performance of different attacks, the nature of the relationships between different attacks, and the influence of various datasets and models on the effectiveness of the attacks, etc. Therefore, we need a benchmark to holistically assess the privacy risks faced by NLP models. In this paper, we present a privacy attack and defense evaluation benchmark in the field of NLP, which includes the conventional/small models and large language models (LLMs). This benchmark supports a variety of models, datasets, and protocols, along with standardized modules for comprehensive evaluation of attacks and defense strategies. Based on the above framework, we present a study on the association between auxiliary data from different domains and the strength of privacy attacks. And we provide an improved attack method in this scenario with the help of Knowledge Distillation (KD). Furthermore, we propose a chained framework for privacy attacks. Allowing a practitioner to chain multiple attacks to achieve a higher-level attack objective. Based on this, we provide some defense and enhanced attack strategies. The code for reproducing the results can be found at https://github.com/user2311717757/nlp_doctor.