 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIV-QA: Privacy-Preserving Question Answering for Cloud Large Language Models
Feb 19, 2025The rapid development of large language models (LLMs) is redefining the landscape of human-computer interaction, and their integration into various user-service applications is becoming increasingly prevalent. However, transmitting user data to cloud-based LLMs presents significant risks of data breaches and unauthorized access to personal identification information. In this paper, we propose a privacy preservation pipeline for protecting privacy and sensitive information during interactions between users and LLMs in practical LLM usage scenarios. We construct SensitiveQA, the first privacy open-ended question-answering dataset. It comprises 57k interactions in Chinese and English, encompassing a diverse range of user-sensitive information within the conversations. Our proposed solution employs a multi-stage strategy aimed at preemptively securing user information while simultaneously preserving the response quality of cloud-based LLMs. Experimental validation underscores our method's efficacy in balancing privacy protection with maintaining robust interaction quality. The code and dataset are available at https://github.com/ligw1998/PRIV-QA.
Diverse and Vivid Sound Generation from Text Descriptions
May 03, 2023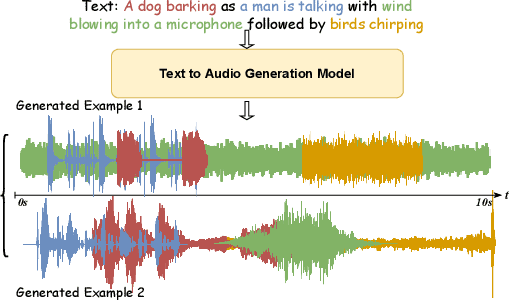
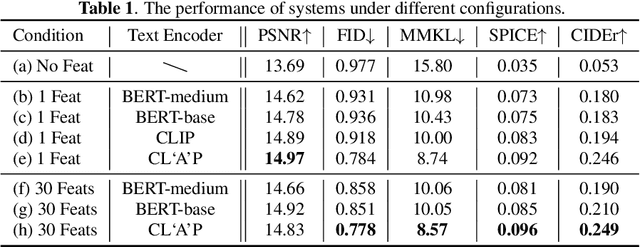
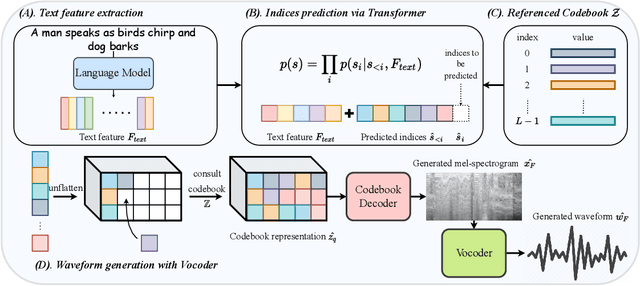

Previous audio generation mainly focuses on specified sound classes such as speech or music, whose form and content are greatly restricted. In this paper, we go beyond specific audio generation by using natural language description as a clue to generate broad sounds. Unlike visual information, a text description is concise by its nature but has rich hidden meanings beneath, which poses a higher possibility and complexity on the audio to be generated. A Variation-Quantized GAN is used to train a codebook learning discrete representations of spectrograms. For a given text description, its pre-trained embedding is fed to a Transformer to sample codebook indices to decode a spectrogram to be further transformed into waveform by a melgan vocoder. The generated waveform has high quality and fidelity while excellently corresponding to the given text. Experiments show that our proposed method is capable of generating natural, vivid audios, achieving superb quantitative and qualitative results.
Enriching Ontology with Temporal Commonsense for Low-Resource Audio Tagging
Oct 03, 2021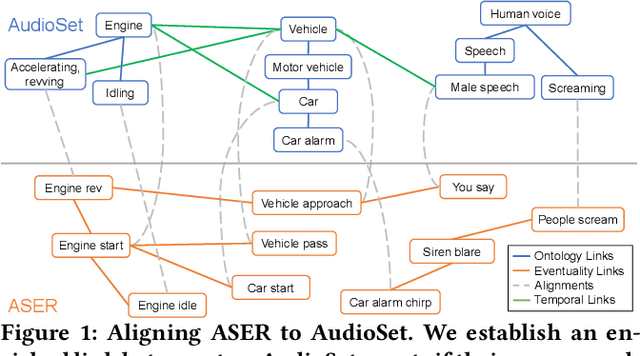
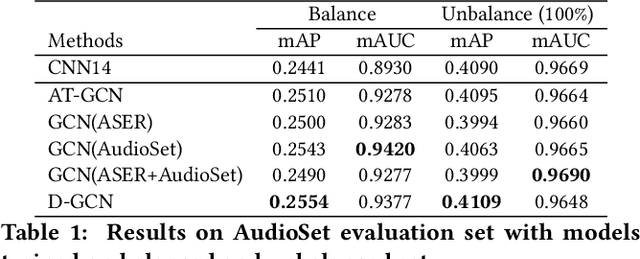
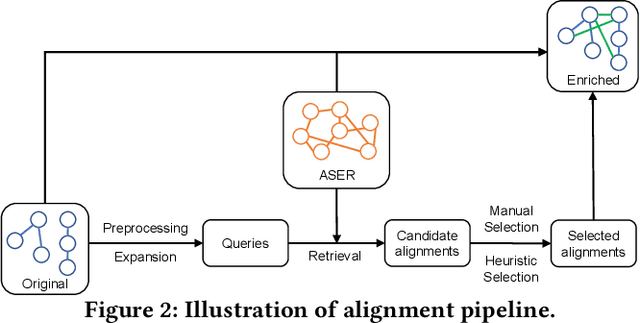
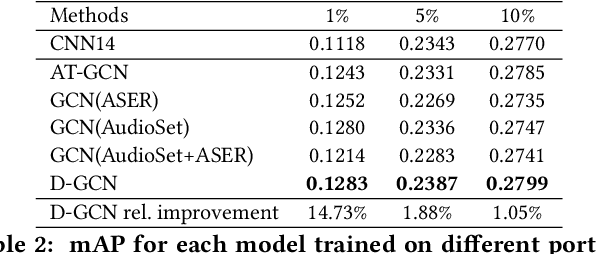
Audio tagging aims at predicting sound events occurred in a recording. Traditional models require enormous laborious annotations, otherwise performance degeneration will be the norm. Therefore, we investigate robust audio tagging models in low-resource scenarios with the enhancement of knowledge graphs. Besides existing ontological knowledge, we further propose a semi-automatic approach that can construct temporal knowledge graphs on diverse domain-specific label sets. Moreover, we leverage a variant of relation-aware graph neural network, D-GCN, to combine the strength of the two knowledge types. Experiments on AudioSet and SONYC urban sound tagging datasets suggest the effectiveness of the introduced temporal knowledge, and the advantage of the combined KGs with D-GCN over single knowledge source.