 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-SIEVE: Exploring Instruction Tuning Large Language Models for Systematic Review Automation
Paper and Code
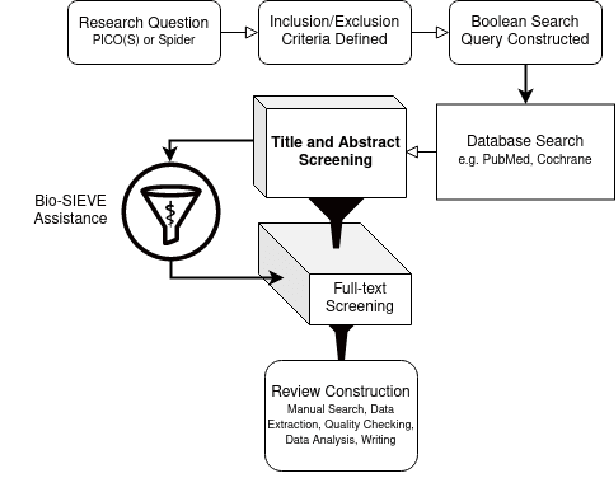
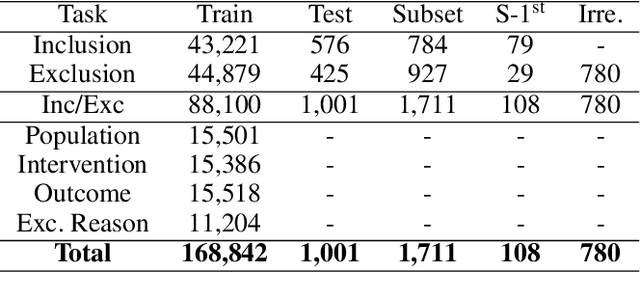
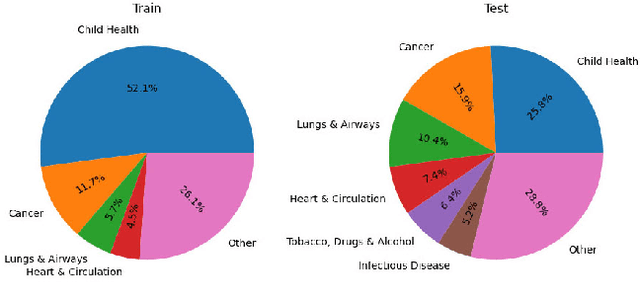
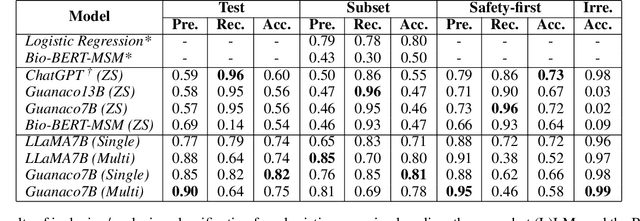
Medical systematic reviews can be very costly and resource intensive. We explore how Large Language Models (LLMs) can support and be trained to perform literature screening when provided with a detailed set of selection criteria. Specifically, we instruction tune LLaMA and Guanaco models to perform abstract screening for medical systematic reviews. Our best model, Bio-SIEVE, outperforms both ChatGPT and trained traditional approaches, and generalises better across medical domains. However, there remains the challenge of adapting the model to safety-first scenarios. We also explore the impact of multi-task training with Bio-SIEVE-Multi, including tasks such as PICO extraction and exclusion reasoning, but find that it is unable to match single-task Bio-SIEVE's performance. We see Bio-SIEVE as an important step towards specialising LLMs for the biomedical systematic review process and explore its future developmental opportunities. We release our models, code and a list of DOIs to reconstruct our dataset for reproducibility.