 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models
Nov 13, 2025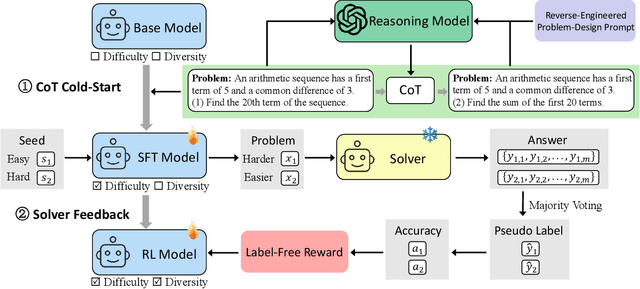
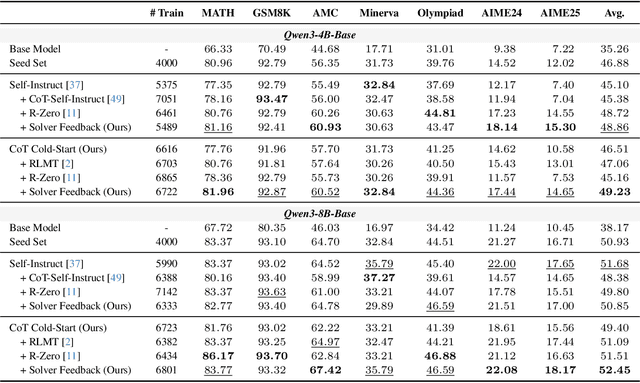

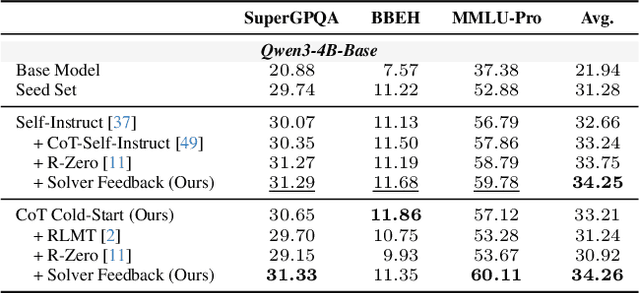
Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data bootstrap problem-design strategies from the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our method achieves an average improvement of 2.5% and generalizes to both language and vision-language models. Moreover, a solver trained on the synthesized data provides improved rewards for continued generator training, enabling co-evolution and yielding a further 0.7% performance gain. Our code will be made publicly available here.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025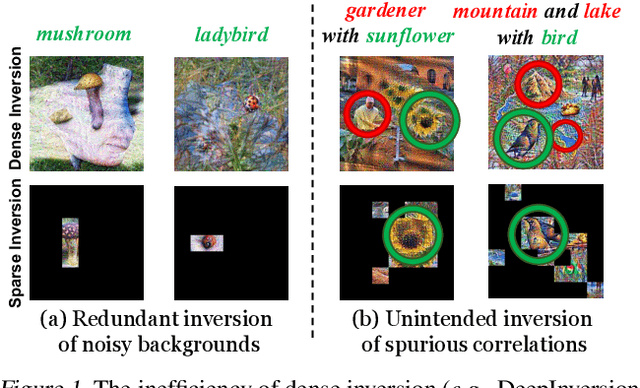
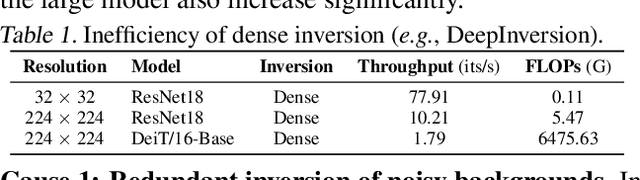
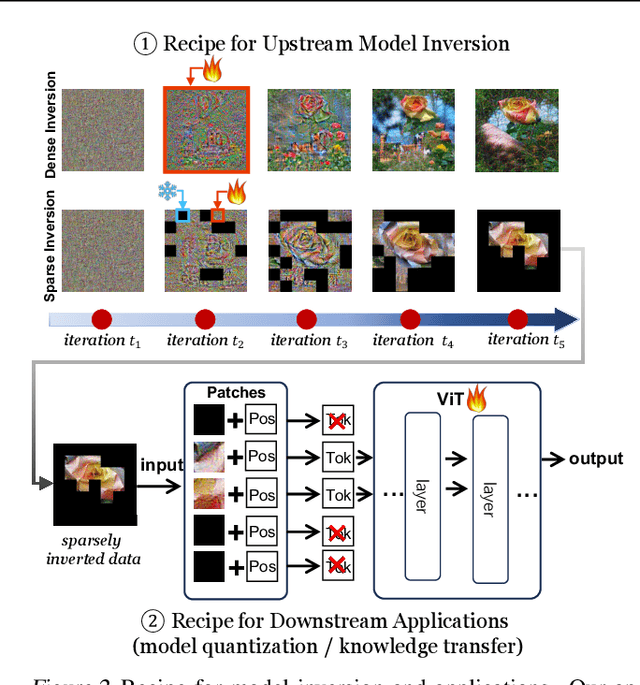
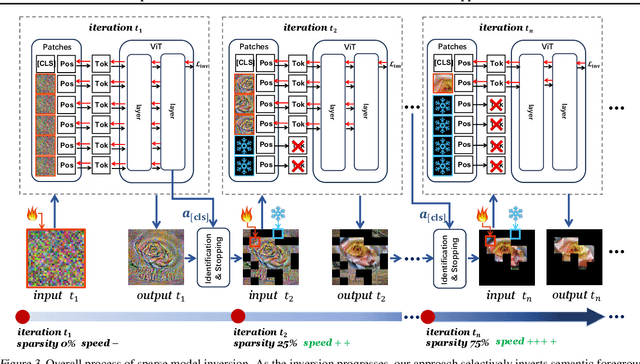
Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.
Adaptive Defense against Harmful Fine-Tuning for Large Language Models via Bayesian Data Scheduler
Oct 31, 2025Harmful fine-tuning poses critical safety risks to fine-tuning-as-a-service for large language models. Existing defense strategies preemptively build robustness via attack simulation but suffer from fundamental limitations: (i) the infeasibility of extending attack simulations beyond bounded threat models due to the inherent difficulty of anticipating unknown attacks, and (ii) limited adaptability to varying attack settings, as simulation fails to capture their variability and complexity. To address these challenges, we propose Bayesian Data Scheduler (BDS), an adaptive tuning-stage defense strategy with no need for attack simulation. BDS formulates harmful fine-tuning defense as a Bayesian inference problem, learning the posterior distribution of each data point's safety attribute, conditioned on the fine-tuning and alignment datasets. The fine-tuning process is then constrained by weighting data with their safety attributes sampled from the posterior, thus mitigating the influence of harmful data. By leveraging the post hoc nature of Bayesian inference, the posterior is conditioned on the fine-tuning dataset, enabling BDS to tailor its defense to the specific dataset, thereby achieving adaptive defense. Furthermore, we introduce a neural scheduler based on amortized Bayesian learning, enabling efficient transfer to new data without retraining. Comprehensive results across diverse attack and defense settings demonstrate the state-of-the-art performance of our approach. Code is available at https://github.com/Egg-Hu/Bayesian-Data-Scheduler.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025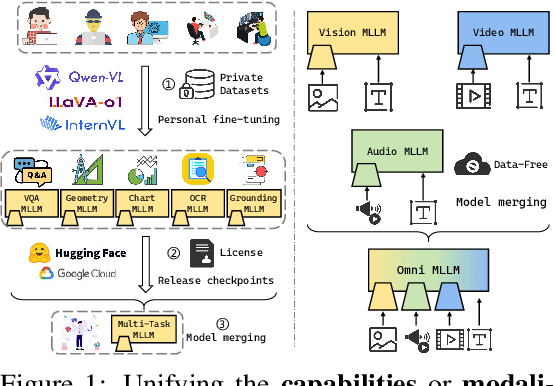

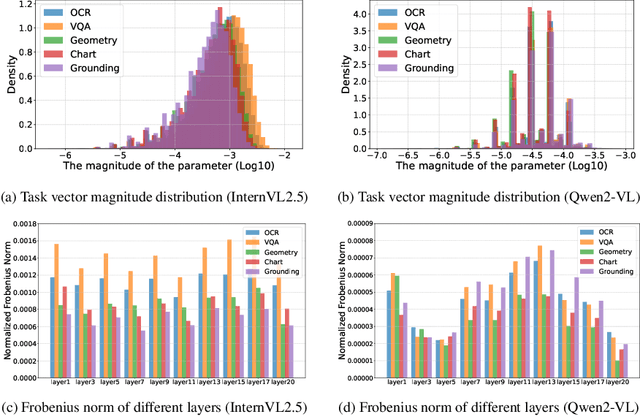
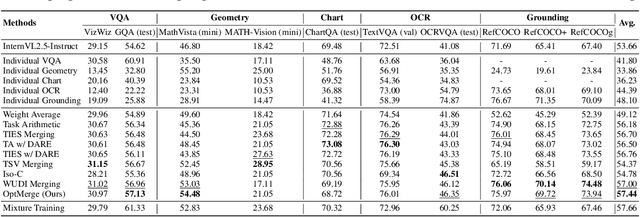
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Whoever Started the Interference Should End It: Guiding Data-Free Model Merging via Task Vectors
Mar 11, 2025



Model merging seeks to integrate task-specific expert models into a unified architecture while preserving multi-task generalization capabilities, yet parameter interference between constituent models frequently induces performance degradation. Although prior work has explored many merging strategies, resolving interference without additional data for retraining or test-time computation remains challenging. In this paper, we theoretically demonstrate that the task vectors of the linear layer constitute an approximate linear subspace for its corresponding input. Therefore, we can minimize interference under the guidance of task vectors. Based on this insight, we propose \textbf{WUDI-Merging} (\textbf{W}hoever started the interference sho\textbf{U}ld en\textbf{D} \textbf{I}t), a simple yet effective model merging method that eliminates interference without any additional data or rescaling coefficients. Comprehensive empirical evaluations across vision and language benchmarks demonstrate our method's superiority, achieving state-of-the-art performance in data-free model merging scenarios (average 10.9\% improvement versus baseline methods) while even outperforming mainstream test-time adaptation approaches by 3.3\%, and only very few computing resources are required. The code will be publicly available soon.
Modeling Multi-Task Model Merging as Adaptive Projective Gradient Descent
Jan 02, 2025



Merging multiple expert models offers a promising approach for performing multi-task learning without accessing their original data. Existing methods attempt to alleviate task conflicts by sparsifying task vectors or promoting orthogonality among them. However, they overlook the fundamental requirement of model merging: ensuring the merged model performs comparably to task-specific models on respective tasks. We find these methods inevitably discard task-specific information that, while causing conflicts, is crucial for performance. Based on our findings, we frame model merging as a constrained optimization problem ($\textit{i.e.}$, minimizing the gap between the merged model and individual models, subject to the constraint of retaining shared knowledge) and solve it via adaptive projective gradient descent. Specifically, we align the merged model with individual models by decomposing and reconstituting the loss function, alleviating conflicts through $\textit{data-free}$ optimization of task vectors. To retain shared knowledge, we optimize this objective by projecting gradients within a $\textit{shared subspace}$ spanning all tasks. Moreover, we view merging coefficients as adaptive learning rates and propose a task-aware, training-free strategy. Experiments show that our plug-and-play approach consistently outperforms previous methods, achieving state-of-the-art results across diverse architectures and tasks in both vision and NLP domains.
Unlocking Tuning-Free Few-Shot Adaptability in Visual Foundation Models by Recycling Pre-Tuned LoRAs
Dec 03, 2024



Large Language Models (LLMs) such as ChatGPT demonstrate strong few-shot adaptability without requiring fine-tuning, positioning them ideal for data-limited and real-time applications. However, this adaptability has not yet been replicated in current Visual Foundation Models (VFMs), which require explicit fine-tuning with sufficient tuning data. Besides, the pretraining-finetuning paradigm has led to the surge of numerous task-specific modular components, such as Low-Rank Adaptation (LoRA). For the first time, we explore the potential of reusing diverse pre-tuned LoRAs without accessing their original training data, to achieve tuning-free few-shot adaptation in VFMs. Our framework, LoRA Recycle, distills a meta-LoRA from diverse pre-tuned LoRAs with a meta-learning objective, using surrogate data generated inversely from pre-tuned LoRAs themselves. The VFM, once equipped with the meta-LoRA, is empowered to solve new few-shot tasks in a single forward pass, akin to the in-context learning of LLMs. Additionally, we incorporate a double-efficient mechanism tailored to our framework, significantly accelerating the meta-training process while maintaining or even improving performance. Extensive experiments across various few-shot classification benchmarks across both in- and cross-domain scenarios demonstrate the superiority of our framework.
Learn To Learn More Precisely
Aug 08, 2024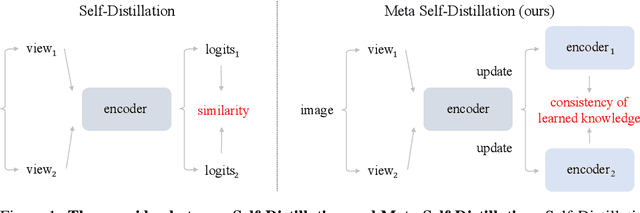
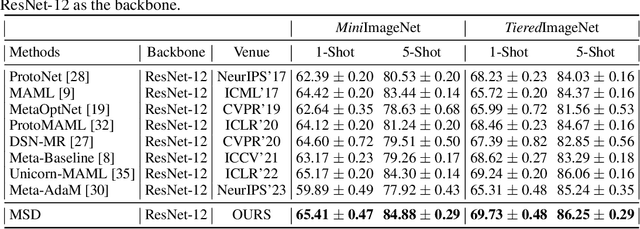
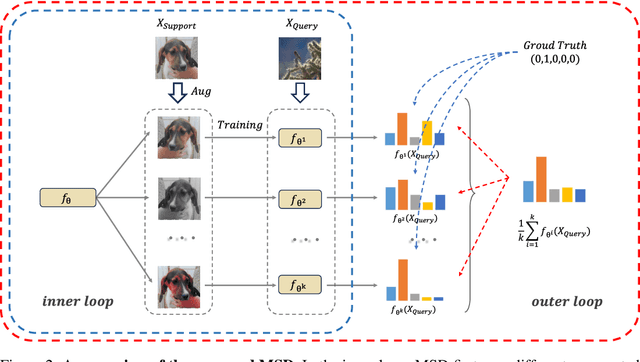
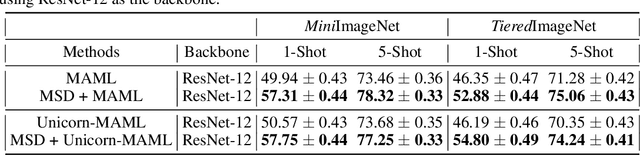
Meta-learning has been extensively applied in the domains of few-shot learning and fast adaptation, achieving remarkable performance. While Meta-learning methods like Model-Agnostic Meta-Learning (MAML) and its variants provide a good set of initial parameters for the model, the model still tends to learn shortcut features, which leads to poor generalization. In this paper, we propose the formal conception of "learn to learn more precisely", which aims to make the model learn precise target knowledge from data and reduce the effect of noisy knowledge, such as background and noise. To achieve this target, we proposed a simple and effective meta-learning framework named Meta Self-Distillation(MSD) to maximize the consistency of learned knowledge, enhancing the models' ability to learn precise target knowledge. In the inner loop, MSD uses different augmented views of the same support data to update the model respectively. Then in the outer loop, MSD utilizes the same query data to optimize the consistency of learned knowledge, enhancing the model's ability to learn more precisely. Our experiment demonstrates that MSD exhibits remarkable performance in few-shot classification tasks in both standard and augmented scenarios, effectively boosting the accuracy and consistency of knowledge learned by the model.
Task Groupings Regularization: Data-Free Meta-Learning with Heterogeneous Pre-trained Models
May 26, 2024
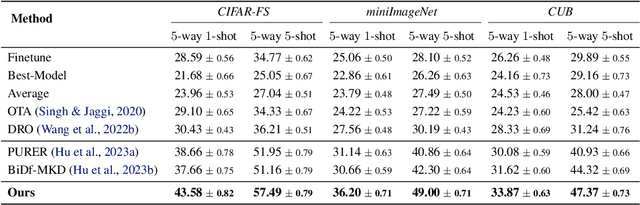

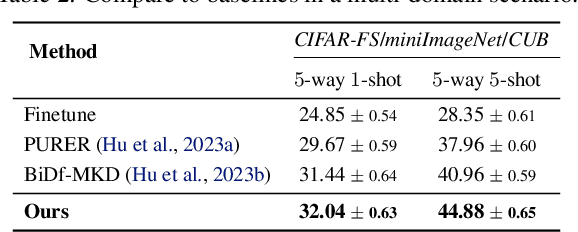
Data-Free Meta-Learning (DFML) aims to derive knowledge from a collection of pre-trained models without accessing their original data, enabling the rapid adaptation to new unseen tasks. Current methods often overlook the heterogeneity among pre-trained models, which leads to performance degradation due to task conflicts. In this paper, we empirically and theoretically identify and analyze the model heterogeneity in DFML. We find that model heterogeneity introduces a heterogeneity-homogeneity trade-off, where homogeneous models reduce task conflicts but also increase the overfitting risk. Balancing this trade-off is crucial for learning shared representations across tasks. Based on our findings, we propose Task Groupings Regularization, a novel approach that benefits from model heterogeneity by grouping and aligning conflicting tasks. Specifically, we embed pre-trained models into a task space to compute dissimilarity, and group heterogeneous models together based on this measure. Then, we introduce implicit gradient regularization within each group to mitigate potential conflicts. By encouraging a gradient direction suitable for all tasks, the meta-model captures shared representations that generalize across tasks. Comprehensive experiments showcase the superiority of our approach in multiple benchmarks, effectively tackling the model heterogeneity in challenging multi-domain and multi-architecture scenarios.
FREE: Faster and Better Data-Free Meta-Learning
May 02, 2024Data-Free Meta-Learning (DFML) aims to extract knowledge from a collection of pre-trained models without requiring the original data, presenting practical benefits in contexts constrained by data privacy concerns. Current DFML methods primarily focus on the data recovery from these pre-trained models. However, they suffer from slow recovery speed and overlook gaps inherent in heterogeneous pre-trained models. In response to these challenges, we introduce the Faster and Better Data-Free Meta-Learning (FREE) framework, which contains: (i) a meta-generator for rapidly recovering training tasks from pre-trained models; and (ii) a meta-learner for generalizing to new unseen tasks. Specifically, within the module Faster Inversion via Meta-Generator, each pre-trained model is perceived as a distinct task. The meta-generator can rapidly adapt to a specific task in just five steps, significantly accelerating the data recovery. Furthermore, we propose Better Generalization via Meta-Learner and introduce an implicit gradient alignment algorithm to optimize the meta-learner. This is achieved as aligned gradient directions alleviate potential conflicts among tasks from heterogeneous pre-trained models. Empirical experiments on multiple benchmarks affirm the superiority of our approach, marking a notable speed-up (20$\times$) and performance enhancement (1.42\% $\sim$ 4.78\%) in comparison to the state-of-the-art.