 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Architectures Without End-to-End Backpropagation: A Brief Survey
Paper and Code
Jan 09, 2021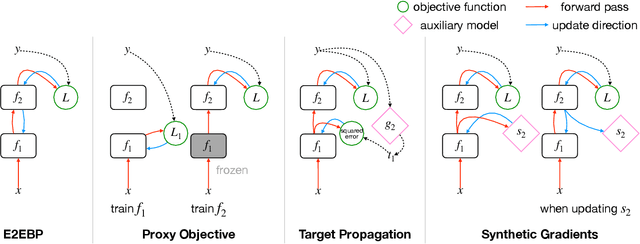

This tutorial paper surveys training alternatives to end-to-end backpropagation (E2EBP) -- the de facto standard for training deep architectures. Modular training refers to strictly local training without both the forward and the backward pass, i.e., dividing a deep architecture into several nonoverlapping modules and training them separately without any end-to-end operation. Between the fully global E2EBP and the strictly local modular training, there are "weakly modular" hybrids performing training without the backward pass only. These alternatives can match or surpass the performance of E2EBP on challenging datasets such as ImageNet, and are gaining increased attention primarily because they offer practical advantages over E2EBP, which will be enumerated herein. In particular, they allow for greater modularity and transparency in deep learning workflows, aligning deep learning with the mainstream computer science engineering that heavily exploits modularization for scalability. Modular training has also revealed novel insights about learning and may have further implications on other important research domains. Specifically, it induces natural and effective solutions to some important practical problems such as data efficiency and transferability estimation.