 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic User Interface Generation for Enhanced Human-Computer Interaction Using Variational Autoencoders
Dec 19, 2024



This study presents a novel approach for intelligent user interaction interface generation and optimization, grounded in the variational autoencoder (VAE) model. With the rapid advancement of intelligent technologies, traditional interface design methods struggle to meet the evolving demands for diversity and personalization, often lacking flexibility in real-time adjustments to enhance the user experience. Human-Computer Interaction (HCI) plays a critical role in addressing these challenges by focusing on creating interfaces that are functional, intuitive, and responsive to user needs. This research leverages the RICO dataset to train the VAE model, enabling the simulation and creation of user interfaces that align with user aesthetics and interaction habits. By integrating real-time user behavior data, the system dynamically refines and optimizes the interface, improving usability and underscoring the importance of HCI in achieving a seamless user experience. Experimental findings indicate that the VAE-based approach significantly enhances the quality and precision of interface generation compared to other methods, including autoencoders (AE), generative adversarial networks (GAN), conditional GANs (cGAN), deep belief networks (DBN), and VAE-GAN. This work contributes valuable insights into HCI, providing robust technical solutions for automated interface generation and enhanced user experience optimization.
PEDRO: Parameter-Efficient Fine-tuning with Prompt DEpenDent Representation MOdification
Sep 26, 2024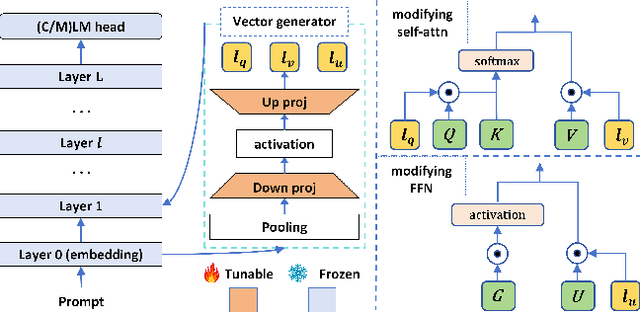
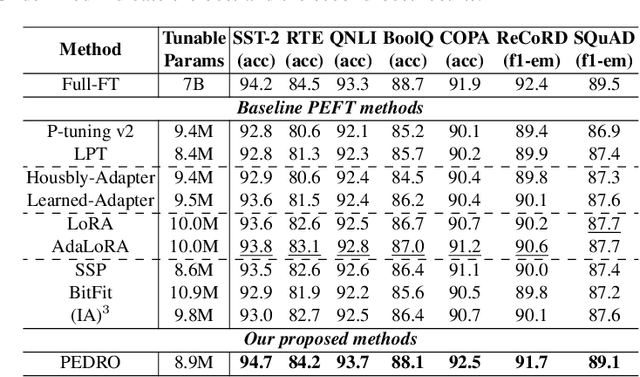


Due to their substantial sizes, large language models (LLMs) are typically deployed within a single-backbone multi-tenant framework. In this setup, a single instance of an LLM backbone must cater to multiple users or tasks through the application of various parameter-efficient fine-tuning (PEFT) models. Despite the availability of numerous effective PEFT techniques such as LoRA, there remains a need for a PEFT approach that achieves both high efficiency during inference and competitive performance on downstream tasks. In this research, we introduce a new and straightforward PEFT methodology named \underline{P}rompt D\underline{E}pen\underline{D}ent \underline{R}epresentation M\underline{O}dification (PEDRO). The proposed method involves integrating a lightweight vector generator into each Transformer layer, which generates vectors contingent upon the input prompts. These vectors then modify the hidden representations created by the LLM through a dot product operation, thereby influencing the semantic output and generated content of the model. Extensive experimentation across a variety of tasks indicates that: (a) PEDRO surpasses recent PEFT benchmarks when using a similar number of tunable parameters. (b) Under the single-backbone multi-tenant deployment model, PEDRO exhibits superior efficiency compared to LoRA, indicating significant industrial potential.