 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEDRO: Parameter-Efficient Fine-tuning with Prompt DEpenDent Representation MOdification
Paper and Code
Sep 26, 2024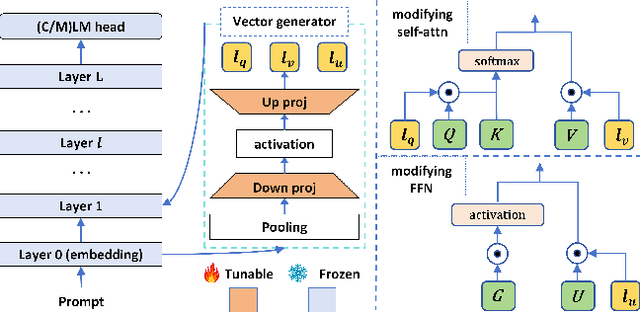
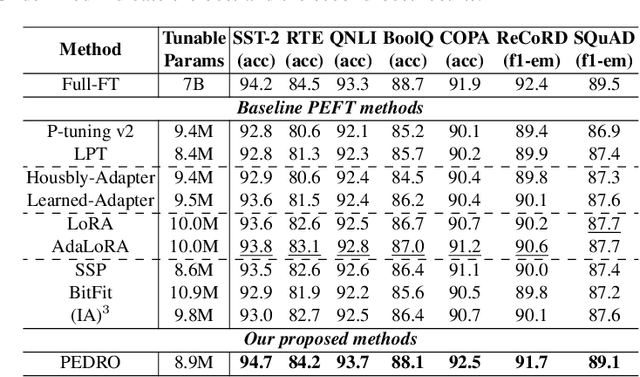


Due to their substantial sizes, large language models (LLMs) are typically deployed within a single-backbone multi-tenant framework. In this setup, a single instance of an LLM backbone must cater to multiple users or tasks through the application of various parameter-efficient fine-tuning (PEFT) models. Despite the availability of numerous effective PEFT techniques such as LoRA, there remains a need for a PEFT approach that achieves both high efficiency during inference and competitive performance on downstream tasks. In this research, we introduce a new and straightforward PEFT methodology named \underline{P}rompt D\underline{E}pen\underline{D}ent \underline{R}epresentation M\underline{O}dification (PEDRO). The proposed method involves integrating a lightweight vector generator into each Transformer layer, which generates vectors contingent upon the input prompts. These vectors then modify the hidden representations created by the LLM through a dot product operation, thereby influencing the semantic output and generated content of the model. Extensive experimentation across a variety of tasks indicates that: (a) PEDRO surpasses recent PEFT benchmarks when using a similar number of tunable parameters. (b) Under the single-backbone multi-tenant deployment model, PEDRO exhibits superior efficiency compared to LoRA, indicating significant industrial potential.