 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
Jan 27, 2026Recent advances in video generation have produced models capable of synthesizing stunning visual content from simple text prompts. However, these models struggle to generate long-form, coherent narratives from high-level concepts like dialogue, revealing a ``semantic gap'' between a creative idea and its cinematic execution. To bridge this gap, we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation. Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script. To enable this, we construct ScriptBench, a new large-scale benchmark with rich multimodal context, annotated via an expert-guided pipeline. The generated script then guides DirectorAgent, which orchestrates state-of-the-art video models using a cross-scene continuous generation strategy to ensure long-horizon coherence. Our comprehensive evaluation, featuring an AI-powered CriticAgent and a new Visual-Script Alignment (VSA) metric, shows our framework significantly improves script faithfulness and temporal fidelity across all tested video models. Furthermore, our analysis uncovers a crucial trade-off in current SOTA models between visual spectacle and strict script adherence, providing valuable insights for the future of automated filmmaking.
BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
Sep 30, 2025The rise of Large Language Models (LLMs) is reshaping multimodel models, with speech synthesis being a prominent application. However, existing approaches often underutilize the linguistic intelligence of these models, typically failing to leverage their powerful instruction-following capabilities. This limitation hinders the model's ability to follow text instructions for controllable Text-to-Speech~(TTS). To address this, we propose a new paradigm inspired by ``operationalism'' that decouples instruction understanding from speech generation. We introduce BatonVoice, a framework where an LLM acts as a ``conductor'', understanding user instructions and generating a textual ``plan'' -- explicit vocal features (e.g., pitch, energy). A separate TTS model, the ``orchestra'', then generates the speech from these features. To realize this component, we develop BatonTTS, a TTS model trained specifically for this task. Our experiments demonstrate that BatonVoice achieves strong performance in controllable and emotional speech synthesis, outperforming strong open- and closed-source baselines. Notably, our approach enables remarkable zero-shot cross-lingual generalization, accurately applying feature control abilities to languages unseen during post-training. This demonstrates that objectifying speech into textual vocal features can more effectively unlock the linguistic intelligence of LLMs.
Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning
Aug 13, 2025Large language models (LLMs) demonstrate remarkable reasoning capabilities in tasks such as algorithmic coding and mathematical problem-solving. Recent methods have improved reasoning through expanded corpus and multistage training combining reinforcement learning and supervised fine-tuning. Although some methods suggest that small but targeted dataset can incentivize reasoning via only distillation, a reasoning scaling laws is still taking shape, increasing computational costs. To address this, we propose a data-efficient distillation framework (DED) that optimizes the Pareto frontier of reasoning distillation. Inspired by the on-policy learning and diverse roll-out strategies of reinforcement learning, the key idea of our approach is threefold: (1) We identify that benchmark scores alone do not determine an effective teacher model. Through comprehensive comparisons of leading reasoning LLMs, we develop a method to select an optimal teacher model. (2) While scaling distillation can enhance reasoning, it often degrades out-of-domain performance. A carefully curated, smaller corpus achieves a balanced trade-off between in-domain and out-of-domain capabilities. (3) Diverse reasoning trajectories encourage the student model to develop robust reasoning skills. We validate our method through evaluations on mathematical reasoning (AIME 2024/2025, MATH-500) and code generation (LiveCodeBench), achieving state-of-the-art results with only 0.8k carefully curated examples, bypassing the need for extensive scaling. Our systematic analysis demonstrates that DED outperforms existing methods by considering factors beyond superficial hardness, token length, or teacher model capability. This work offers a practical and efficient pathway to advanced reasoning while preserving general capabilities.
Structure-Aware Corpus Construction and User-Perception-Aligned Metrics for Large-Language-Model Code Completion
May 19, 2025Code completion technology based on large language model has significantly improved the development efficiency of programmers. However, in practical applications, there remains a gap between current commonly used code completion evaluation metrics and users' actual perception. To address this issue, we propose two evaluation metrics for code completion tasks--LCP and ROUGE-LCP, from the perspective of probabilistic modeling. Furthermore, to tackle the lack of effective structural semantic modeling and cross-module dependency information in LLMs for repository-level code completion scenarios, we propose a data processing method based on a Structure-Preserving and Semantically-Reordered Code Graph (SPSR-Graph). Through theoretical analysis and experimental validation, we demonstrate the superiority of the proposed evaluation metrics in terms of user perception consistency, as well as the effectiveness of the data processing method in enhancing model performance.
Applying Feature Underspecified Lexicon Phonological Features in Multilingual Text-to-Speech
Apr 14, 2022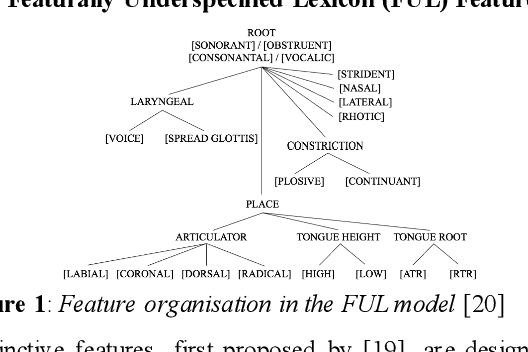
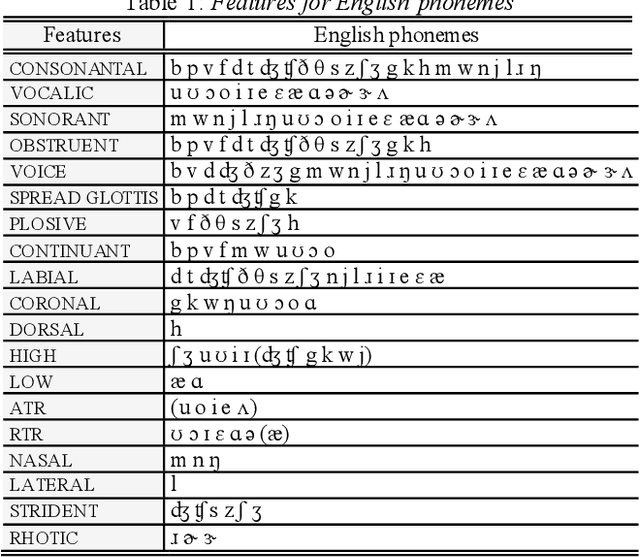

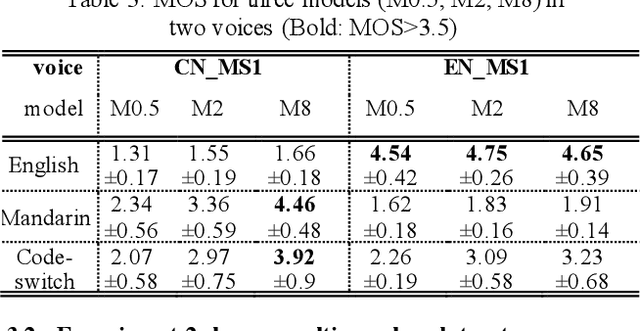
This study investigates whether the phonological features derived from the Featurally Underspecified Lexicon model can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. This mapping was tested for whether it could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results supported that phonological features could be used as a feasible input system for languages in or not in the train data, although further investigation is needed to improve model performance. The results lend support to FUL by presenting successfully synthesised output, and by having the output carrying a source-language accent when synthesising a language not in the training data. The TTS process stimulated human second language acquisition process and thus also confirm FUL's ability to account for acquisition.
Applying Phonological Features in Multilingual Text-To-Speech
Oct 10, 2021
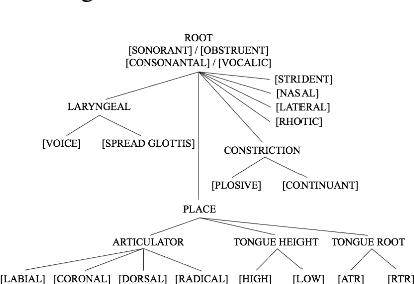

This study investigates whether phonological features can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. We tested whether this mapping could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results proved that phonological features could be used as a feasible input system, although further investigation is needed to improve model performance. The accented output generated by the TTS models also helps with understanding human second language acquisition processes.