 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Feature Underspecified Lexicon Phonological Features in Multilingual Text-to-Speech
Paper and Code
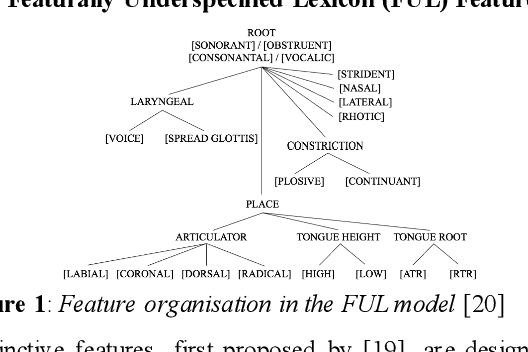
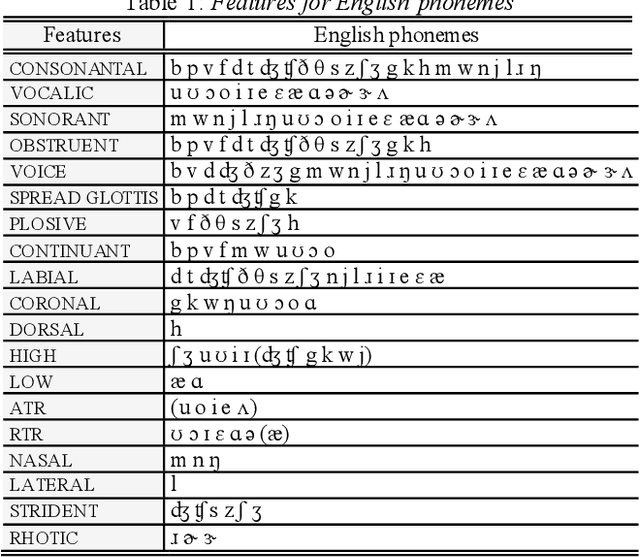

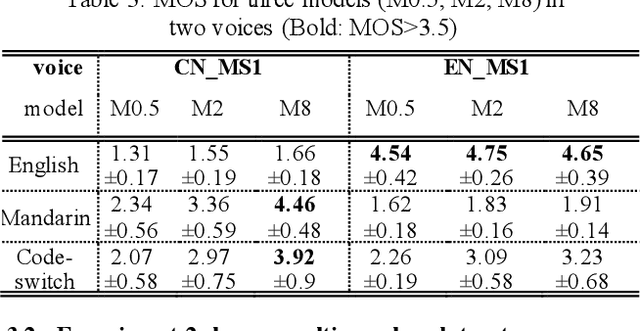
This study investigates whether the phonological features derived from the Featurally Underspecified Lexicon model can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. This mapping was tested for whether it could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results supported that phonological features could be used as a feasible input system for languages in or not in the train data, although further investigation is needed to improve model performance. The results lend support to FUL by presenting successfully synthesised output, and by having the output carrying a source-language accent when synthesising a language not in the training data. The TTS process stimulated human second language acquisition process and thus also confirm FUL's ability to account for acquisition.