 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Phonological Features in Multilingual Text-To-Speech
Paper and Code

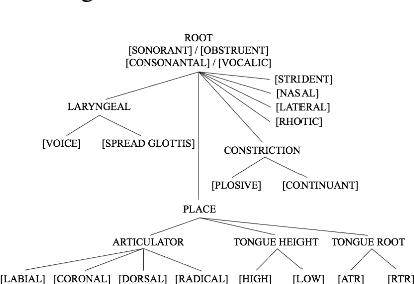

This study investigates whether phonological features can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. We tested whether this mapping could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results proved that phonological features could be used as a feasible input system, although further investigation is needed to improve model performance. The accented output generated by the TTS models also helps with understanding human second language acquisition processes.