 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Koopman Distillation for Real-Time Robot Control Using Diffusion Models
May 24, 2026Diffusion models excel at generating diverse and multimodal trajectories for robotic planning, yet their iterative denoising process introduces latency that is incompatible with high-frequency closed-loop control. To address this problem, we propose Dynamic Neural Koopman Distillation, a framework that distills multistep diffusion inference into a single forward pass while retaining the multimodal expressivity of the teacher model. Specifically, we introduce a Factorized Dynamic Koopman layer that models the denoising process through a factorized latent transition with state-dependent modal gains. We evaluate the proposed method on standard D4RL MuJoCo locomotion benchmarks and a physical Kinova manipulator, comparing against one-step baselines. The results show that our method significantly outperforms existing one-step distillation approaches on the reported locomotion tasks, and reduces the inference latency to the millisecond regime compared with the teacher policy. Hardware experiments further demonstrate that our method enables smooth and fast closed-loop execution while maintaining task success and comparable accuracy. A project page is available at https://fdkoopman.github.io/.
Emergent Neural Automaton Policies: Learning Symbolic Structure from Visuomotor Trajectories
Mar 26, 2026Scaling robot learning to long-horizon tasks remains a formidable challenge. While end-to-end policies often lack the structural priors needed for effective long-term reasoning, traditional neuro-symbolic methods rely heavily on hand-crafted symbolic priors. To address the issue, we introduce ENAP (Emergent Neural Automaton Policy), a framework that allows a bi-level neuro-symbolic policy adaptively emerge from visuomotor demonstrations. Specifically, we first employ adaptive clustering and an extension of the L* algorithm to infer a Mealy state machine from visuomotor data, which serves as an interpretable high-level planner capturing latent task modes. Then, this discrete structure guides a low-level reactive residual network to learn precise continuous control via behavior cloning (BC). By explicitly modeling the task structure with discrete transitions and continuous residuals, ENAP achieves high sample efficiency and interpretability without requiring task-specific labels. Extensive experiments on complex manipulation and long-horizon tasks demonstrate that ENAP outperforms state-of-the-art (SoTA) end-to-end VLA policies by up to 27% in low-data regimes, while offering a structured representation of robotic intent (Fig. 1).
Autonomous Integration and Improvement of Robotic Assembly using Skill Graph Representations
Mar 13, 2026Robotic assembly systems traditionally require substantial manual engineering effort to integrate new tasks, adapt to new environments, and improve performance over time. This paper presents a framework for autonomous integration and continuous improvement of robotic assembly systems based on Skill Graph representations. A Skill Graph organizes robot capabilities as verb-based skills, explicitly linking semantic descriptions (verbs and nouns) with executable policies, pre-conditions, post-conditions, and evaluators. We show how Skill Graphs enable rapid system integration by supporting semantic-level planning over skills, while simultaneously grounding execution through well-defined interfaces to robot controllers and perception modules. After initial deployment, the same Skill Graph structure supports systematic data collection and closed-loop performance improvement, enabling iterative refinement of skills and their composition. We demonstrate how this approach unifies system configuration, execution, evaluation, and learning within a single representation, providing a scalable pathway toward adaptive and reusable robotic assembly systems. The code is at https://github.com/intelligent-control-lab/AIDF.
Efficient Post-Training Pruning of Large Language Models with Statistical Correction
Feb 07, 2026Post-training pruning is an effective approach for reducing the size and inference cost of large language models (LLMs), but existing methods often face a trade-off between pruning quality and computational efficiency. Heuristic pruning methods are efficient but sensitive to activation outliers, while reconstruction-based approaches improve fidelity at the cost of heavy computation. In this work, we propose a lightweight post-training pruning framework based on first-order statistical properties of model weights and activations. During pruning, channel-wise statistics are used to calibrate magnitude-based importance scores, reducing bias from activation-dominated channels. After pruning, we apply an analytic energy compensation to correct distributional distortions caused by weight removal. Both steps operate without retraining, gradients, or second-order information. Experiments across multiple LLM families, sparsity patterns, and evaluation tasks show that the proposed approach improves pruning performance while maintaining computational cost comparable to heuristic methods. The results suggest that simple statistical corrections can be effective for post-training pruning of LLMs.
NeSyPack: A Neuro-Symbolic Framework for Bimanual Logistics Packing
Jun 06, 2025This paper presents NeSyPack, a neuro-symbolic framework for bimanual logistics packing. NeSyPack combines data-driven models and symbolic reasoning to build an explainable hierarchical system that is generalizable, data-efficient, and reliable. It decomposes a task into subtasks via hierarchical reasoning, and further into atomic skills managed by a symbolic skill graph. The graph selects skill parameters, robot configurations, and task-specific control strategies for execution. This modular design enables robustness, adaptability, and efficient reuse - outperforming end-to-end models that require large-scale retraining. Using NeSyPack, our team won the First Prize in the What Bimanuals Can Do (WBCD) competition at the 2025 IEEE International Conference on Robotics and Automation.
Robustifying Long-term Human-Robot Collaboration through a Hierarchical and Multimodal Framework
Nov 24, 2024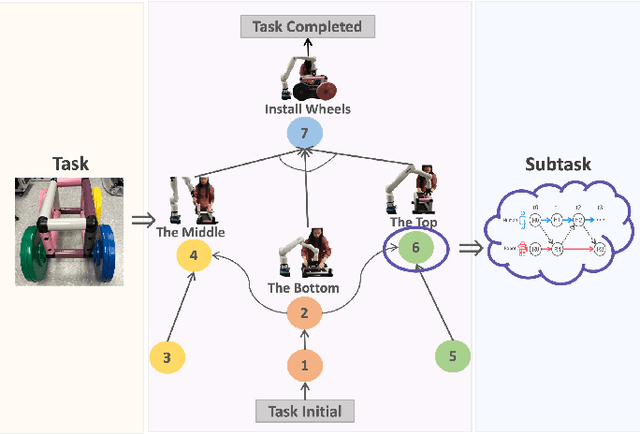
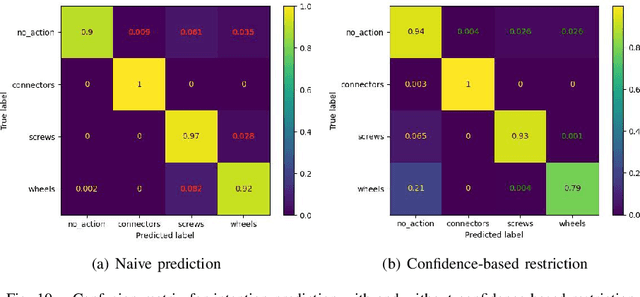
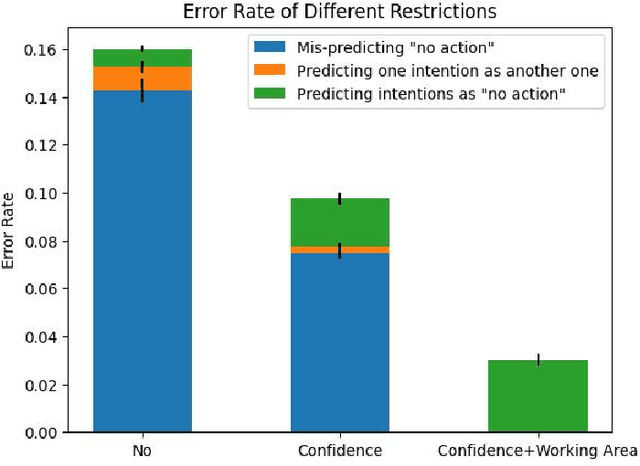
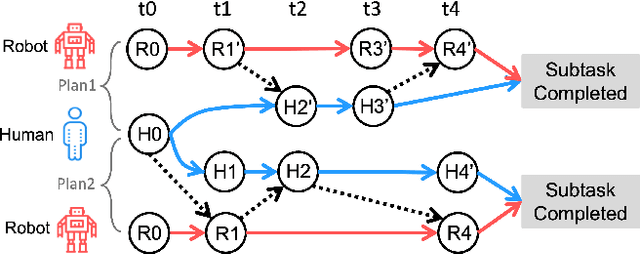
Long-term Human-Robot Collaboration (HRC) is crucial for developing flexible manufacturing systems and for integrating companion robots into daily human environments over extended periods. However, sustaining such collaborations requires overcoming challenges such as accurately understanding human intentions, maintaining robustness in noisy and dynamic environments, and adapting to diverse user behaviors. This paper presents a novel multimodal and hierarchical framework to address these challenges, facilitating efficient and robust long-term HRC. In particular, the proposed multimodal framework integrates visual observations with speech commands, which enables intuitive, natural, and flexible interactions between humans and robots. Additionally, our hierarchical approach for human detection and intention prediction significantly enhances the system's robustness, allowing robots to better understand human behaviors. The proactive understanding enables robots to take timely and appropriate actions based on predicted human intentions. We deploy the proposed multimodal hierarchical framework to the KINOVA GEN3 robot and conduct extensive user studies on real-world long-term HRC experiments. The results demonstrate that our approach effectively improves the system efficiency, flexibility, and adaptability in long-term HRC, showcasing the framework's potential to significantly improve the way humans and robots work together.
Prompt-Guided Internal States for Hallucination Detection of Large Language Models
Nov 07, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of tasks in different domains. However, they sometimes generate responses that are logically coherent but factually incorrect or misleading, which is known as LLM hallucinations. Data-driven supervised methods train hallucination detectors by leveraging the internal states of LLMs, but detectors trained on specific domains often struggle to generalize well to other domains. In this paper, we aim to enhance the cross-domain performance of supervised detectors with only in-domain data. We propose a novel framework, prompt-guided internal states for hallucination detection of LLMs, namely PRISM. By utilizing appropriate prompts to guide changes in the structure related to text truthfulness within the LLM's internal states, we make this structure more salient and consistent across texts from different domains. We integrated our framework with existing hallucination detection methods and conducted experiments on datasets from different domains. The experimental results indicate that our framework significantly enhances the cross-domain generalization of existing hallucination detection methods.