 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Unlearning Using Conformal Prediction
Feb 03, 2026Machine unlearning is the process of efficiently removing specific information from a trained machine learning model without retraining from scratch. Existing unlearning methods, which often provide provable guarantees, typically involve retraining a subset of model parameters based on a forget set. While these approaches show promise in certain scenarios, their underlying assumptions are often challenged in real-world applications -- particularly when applied to generative models. Furthermore, updating parameters using these unlearning procedures often degrades the general-purpose capabilities the model acquired during pre-training. Motivated by these shortcomings, this paper considers the paradigm of inference time unlearning -- wherein, the generative model is equipped with an (approximately correct) verifier that judges whether the model's response satisfies appropriate unlearning guarantees. This paper introduces a framework that iteratively refines the quality of the generated responses using feedback from the verifier without updating the model parameters. The proposed framework leverages conformal prediction to reduce computational overhead and provide distribution-free unlearning guarantees. This paper's approach significantly outperforms existing state-of-the-art methods, reducing unlearning error by up to 93% across challenging unlearning benchmarks.
Scalable Bottom-Up Hierarchical Clustering
Nov 04, 2020
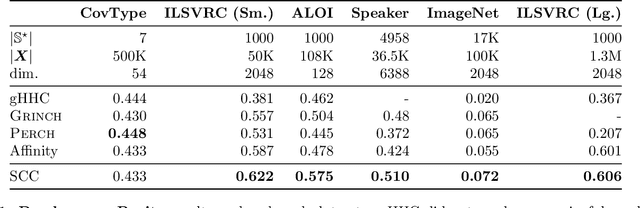

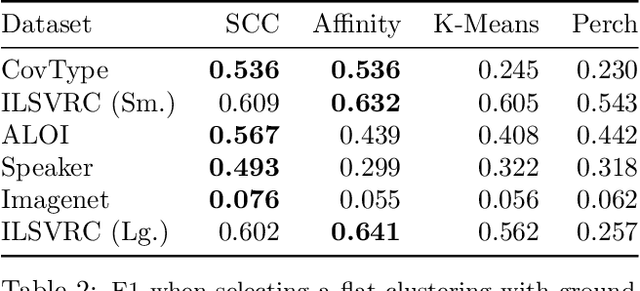
Bottom-up algorithms such as the classic hierarchical agglomerative clustering, are highly effective for hierarchical as well as flat clustering. However, the large number of rounds and their sequential nature limit the scalability of agglomerative clustering. In this paper, we present an alternative round-based bottom-up hierarchical clustering, the Sub-Cluster Component Algorithm (SCC), that scales gracefully to massive datasets. Our method builds many sub-clusters in parallel in a given round and requires many fewer rounds -- usually an order of magnitude smaller than classic agglomerative clustering. Our theoretical analysis shows that, under a modest separability assumption, SCC will contain the optimal flat clustering. SCC also provides a 2-approx solution to the DP-means objective, thereby introducing a novel application of hierarchical clustering methods. Empirically, SCC finds better hierarchies and flat clusterings even when the data does not satisfy the separability assumption. We demonstrate the scalability of our method by applying it to a dataset of 30 billion points and showing that SCC produces higher quality clusterings than the state-of-the-art.