 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Generalization of Vision-Based RL Without Data Augmentation
Paper and Code
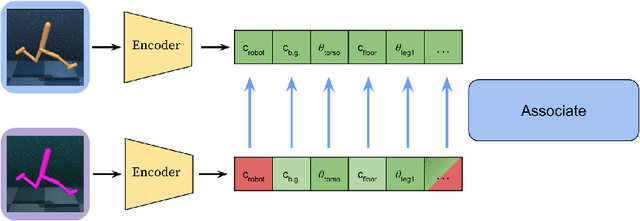
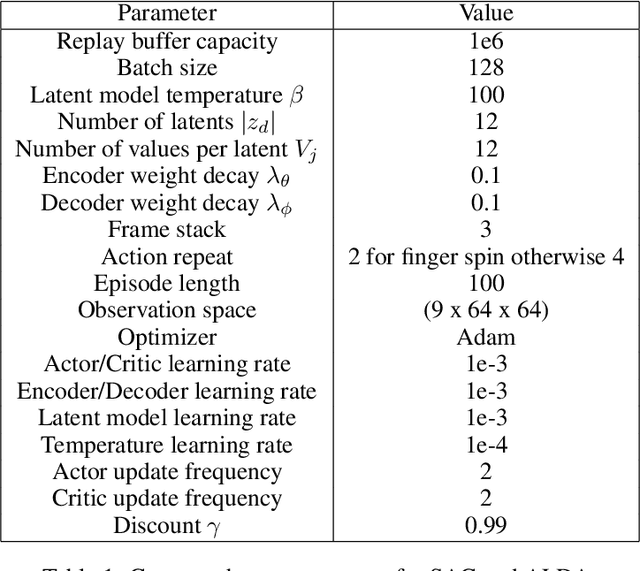
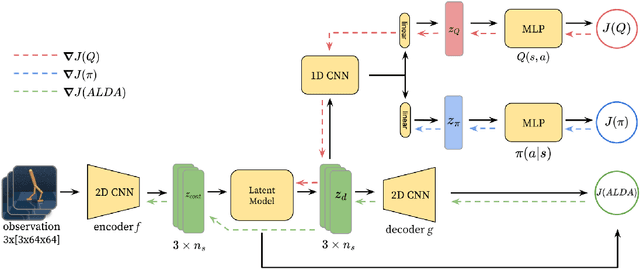
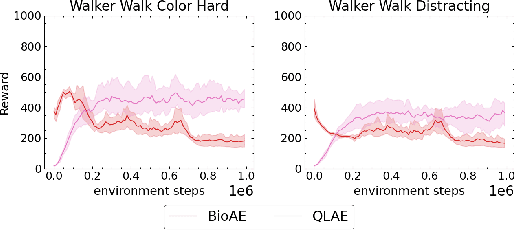
Generalizing vision-based reinforcement learning (RL) agents to novel environments remains a difficult and open challenge. Current trends are to collect large-scale datasets or use data augmentation techniques to prevent overfitting and improve downstream generalization. However, the computational and data collection costs increase exponentially with the number of task variations and can destabilize the already difficult task of training RL agents. In this work, we take inspiration from recent advances in computational neuroscience and propose a model, Associative Latent DisentAnglement (ALDA), that builds on standard off-policy RL towards zero-shot generalization. Specifically, we revisit the role of latent disentanglement in RL and show how combining it with a model of associative memory achieves zero-shot generalization on difficult task variations without relying on data augmentation. Finally, we formally show that data augmentation techniques are a form of weak disentanglement and discuss the implications of this insight.