 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE-32B: Agentic Reasoning via Iterative Distillation
Jan 04, 2026We demonstrate SAGE-32B, a 32 billion parameter language model that focuses on agentic reasoning and long range planning tasks. Unlike chat models that aim for general conversation fluency, SAGE-32B is designed to operate in an agentic loop, emphasizing task decomposition, tool usage, and error recovery. The model is initialized from the Qwen2.5-32B pretrained model and fine tuned using Iterative Distillation, a two stage training process that improves reasoning performance through rigorously tested feedback loops. SAGE-32B also introduces an inverse reasoning approach, which uses a meta cognition head to forecast potential failures in the planning process before execution. On agentic reasoning benchmarks including MMLU-Pro, AgentBench, and MATH-500, SAGE-32B achieves higher success rates in multi tool usage scenarios compared to similarly sized baseline models, while remaining competitive on standard reasoning evaluations. Model weights are publicly released at https://huggingface.co/sagea-ai/sage-reasoning-32b
Guaranteed Trust Region Optimization via Two-Phase KL Penalization
Dec 08, 2023



On-policy reinforcement learning (RL) has become a popular framework for solving sequential decision problems due to its computational efficiency and theoretical simplicity. Some on-policy methods guarantee every policy update is constrained to a trust region relative to the prior policy to ensure training stability. These methods often require computationally intensive non-linear optimization or require a particular form of action distribution. In this work, we show that applying KL penalization alone is nearly sufficient to enforce such trust regions. Then, we show that introducing a "fixup" phase is sufficient to guarantee a trust region is enforced on every policy update while adding fewer than 5% additional gradient steps in practice. The resulting algorithm, which we call FixPO, is able to train a variety of policy architectures and action spaces, is easy to implement, and produces results competitive with other trust region methods.
A Simple Approach to Continual Learning by Transferring Skill Parameters
Oct 19, 2021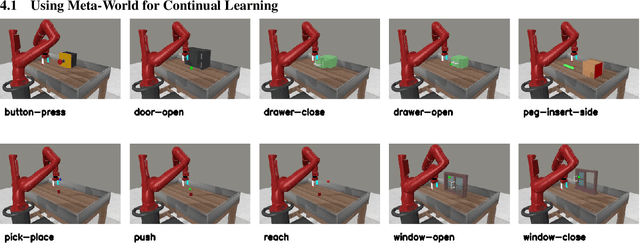
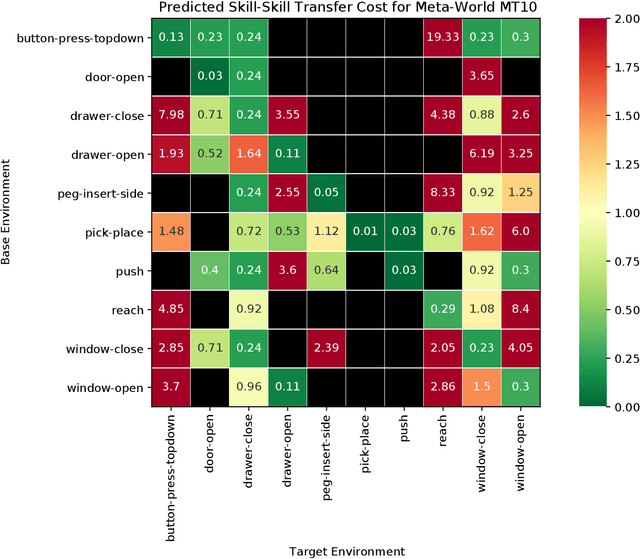
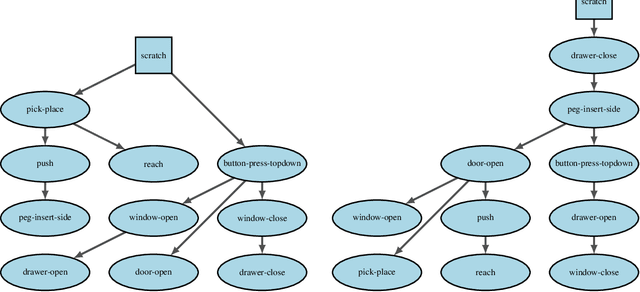
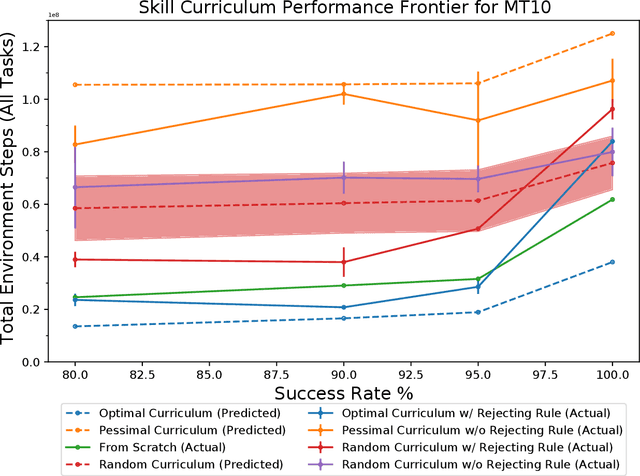
In order to be effective general purpose machines in real world environments, robots not only will need to adapt their existing manipulation skills to new circumstances, they will need to acquire entirely new skills on-the-fly. A great promise of continual learning is to endow robots with this ability, by using their accumulated knowledge and experience from prior skills. We take a fresh look at this problem, by considering a setting in which the robot is limited to storing that knowledge and experience only in the form of learned skill policies. We show that storing skill policies, careful pre-training, and appropriately choosing when to transfer those skill policies is sufficient to build a continual learner in the context of robotic manipulation. We analyze which conditions are needed to transfer skills in the challenging Meta-World simulation benchmark. Using this analysis, we introduce a pair-wise metric relating skills that allows us to predict the effectiveness of skill transfer between tasks, and use it to reduce the problem of continual learning to curriculum selection. Given an appropriate curriculum, we show how to continually acquire robotic manipulation skills without forgetting, and using far fewer samples than needed to train them from scratch.
Towards Exploiting Geometry and Time for Fast Off-Distribution Adaptation in Multi-Task Robot Learning
Jun 29, 2021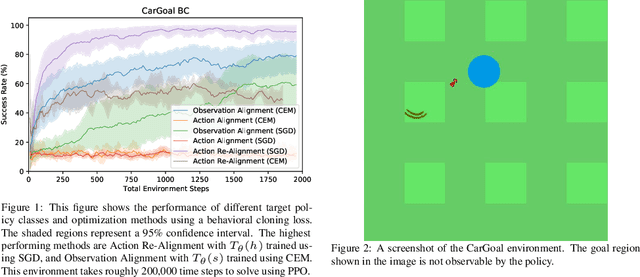
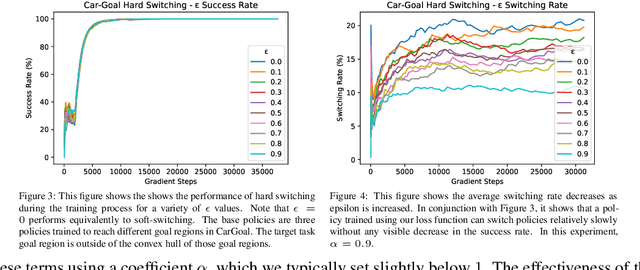
We explore possible methods for multi-task transfer learning which seek to exploit the shared physical structure of robotics tasks. Specifically, we train policies for a base set of pre-training tasks, then experiment with adapting to new off-distribution tasks, using simple architectural approaches for re-using these policies as black-box priors. These approaches include learning an alignment of either the observation space or action space from a base to a target task to exploit rigid body structure, and methods for learning a time-domain switching policy across base tasks which solves the target task, to exploit temporal coherence. We find that combining low-complexity target policy classes, base policies as black-box priors, and simple optimization algorithms allows us to acquire new tasks outside the base task distribution, using small amounts of offline training data.