 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic memory in AI agents poses risks that should be studied and mitigated
Jan 20, 2025Most current AI models have little ability to store and later retrieve a record or representation of what they do. In human cognition, episodic memories play an important role in both recall of the past as well as planning for the future. The ability to form and use episodic memories would similarly enable a broad range of improved capabilities in an AI agent that interacts with and takes actions in the world. Researchers have begun directing more attention to developing memory abilities in AI models. It is therefore likely that models with such capability will be become widespread in the near future. This could in some ways contribute to making such AI agents safer by enabling users to better monitor, understand, and control their actions. However, as a new capability with wide applications, we argue that it will also introduce significant new risks that researchers should begin to study and address. We outline these risks and benefits and propose four principles to guide the development of episodic memory capabilities so that these will enhance, rather than undermine, the effort to keep AI safe and trustworthy.
Episodic Memory Verbalization using Hierarchical Representations of Life-Long Robot Experience
Sep 26, 2024Verbalization of robot experience, i.e., summarization of and question answering about a robot's past, is a crucial ability for improving human-robot interaction. Previous works applied rule-based systems or fine-tuned deep models to verbalize short (several-minute-long) streams of episodic data, limiting generalization and transferability. In our work, we apply large pretrained models to tackle this task with zero or few examples, and specifically focus on verbalizing life-long experiences. For this, we derive a tree-like data structure from episodic memory (EM), with lower levels representing raw perception and proprioception data, and higher levels abstracting events to natural language concepts. Given such a hierarchical representation built from the experience stream, we apply a large language model as an agent to interactively search the EM given a user's query, dynamically expanding (initially collapsed) tree nodes to find the relevant information. The approach keeps computational costs low even when scaling to months of robot experience data. We evaluate our method on simulated household robot data, human egocentric videos, and real-world robot recordings, demonstrating its flexibility and scalability.
Learning to Summarize and Answer Questions about a Virtual Robot's Past Actions
Jun 16, 2023When robots perform long action sequences, users will want to easily and reliably find out what they have done. We therefore demonstrate the task of learning to summarize and answer questions about a robot agent's past actions using natural language alone. A single system with a large language model at its core is trained to both summarize and answer questions about action sequences given ego-centric video frames of a virtual robot and a question prompt. To enable training of question answering, we develop a method to automatically generate English-language questions and answers about objects, actions, and the temporal order in which actions occurred during episodes of robot action in the virtual environment. Training one model to both summarize and answer questions enables zero-shot transfer of representations of objects learned through question answering to improved action summarization. % involving objects not seen in training to summarize.
Summarizing a virtual robot's past actions in natural language
Mar 13, 2022
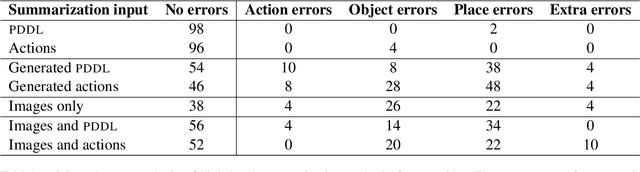
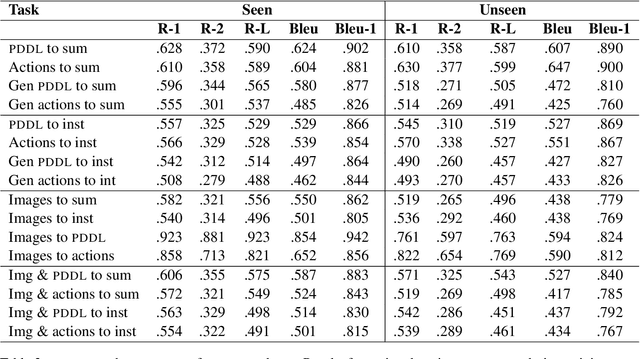
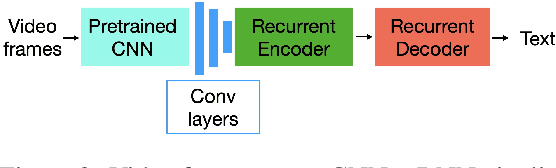
We propose and demonstrate the task of giving natural language summaries of the actions of a robotic agent in a virtual environment. We explain why such a task is important, what makes it difficult, and discuss how it might be addressed. To encourage others to work on this, we show how a popular existing dataset that matches robot actions with natural language descriptions designed for an instruction following task can be repurposed to serve as a training ground for robot action summarization work. We propose and test several methods of learning to generate such summaries, starting from either egocentric video frames of the robot taking actions or intermediate text representations of the actions used by an automatic planner. We provide quantitative and qualitative evaluations of our results, which can serve as a baseline for future work.
Automated Grassy Weed Detection in Aerial Imagery with Context
Oct 09, 2019


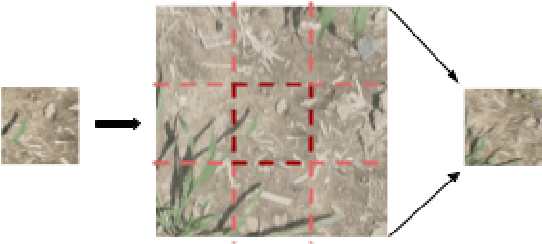
In this paper, we demonstrate the ability to discriminate between cultivated maize plant and grassy weed image segments using the context surrounding the image segments. While convolutional neural networks have brought state of the art accuracies within object detection, errors arise when objects in different classes share similar features. This scenario often occurs when objects in images are viewed at too small of a scale to discern distinct differences in features, causing images to be incorrectly classified or localized. To solve this problem, we will explore using context when classifying image segments. This technique involves feeding a convolutional neural network a central square image along with a border of its direct surroundings at train and test times. This means that although images are labelled at a smaller scale to preserve accurate localization, the network classifies the images and learns features that include the wider context. We demonstrate the benefits of this context technique in the object detection task through a case study of grassy weed detection in maize fields. In this standard situation, adding context alone nearly halved the error of the neural network from 7.1% to 4.3%. After only one epoch with context, the network also achieved a higher accuracy than the network without context did after 50 epochs. The benefits of using the context technique are likely to particularly evident in agricultural contexts in which parts (such as leaves) of several plants may appear similar when not taking into account the context in which those parts appear.
Shape Completion Enabled Robotic Grasping
Mar 02, 2017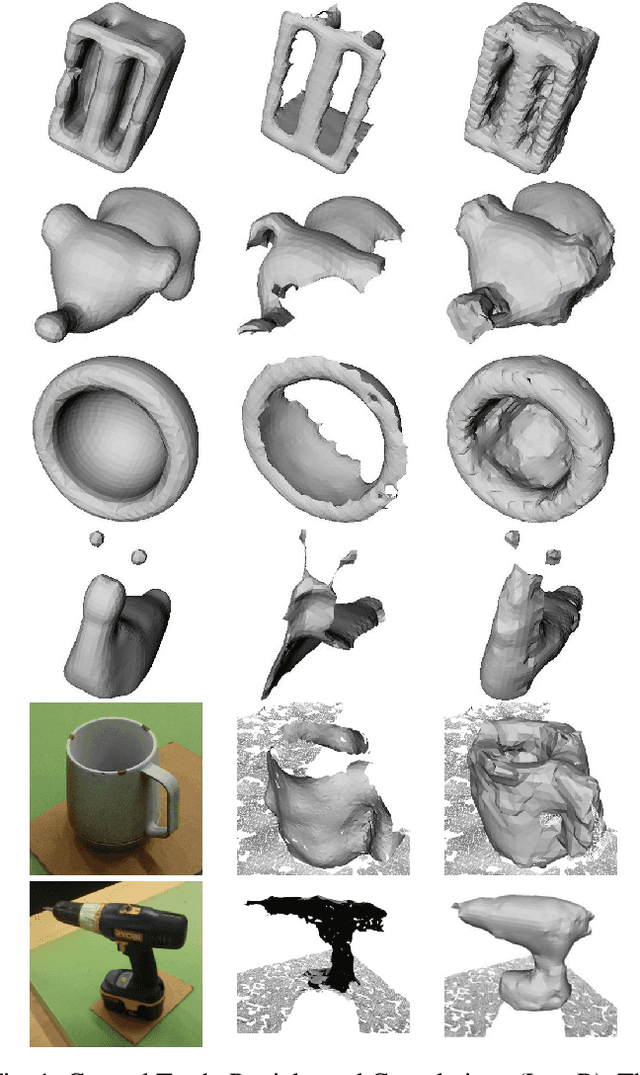
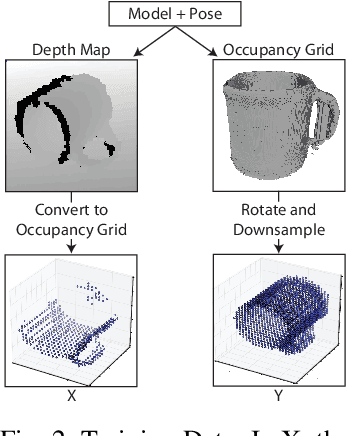
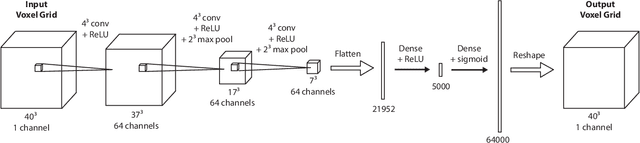

This work provides an architecture to enable robotic grasp planning via shape completion. Shape completion is accomplished through the use of a 3D convolutional neural network (CNN). The network is trained on our own new open source dataset of over 440,000 3D exemplars captured from varying viewpoints. At runtime, a 2.5D pointcloud captured from a single point of view is fed into the CNN, which fills in the occluded regions of the scene, allowing grasps to be planned and executed on the completed object. Runtime shape completion is very rapid because most of the computational costs of shape completion are borne during offline training. We explore how the quality of completions vary based on several factors. These include whether or not the object being completed existed in the training data and how many object models were used to train the network. We also look at the ability of the network to generalize to novel objects allowing the system to complete previously unseen objects at runtime. Finally, experimentation is done both in simulation and on actual robotic hardware to explore the relationship between completion quality and the utility of the completed mesh model for grasping.