 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Domain Adaptation for Text Line Recognition via Decoupled Language Models
Mar 30, 2026Optical character recognition remains critical infrastructure for document digitization, yet state-of-the-art performance is often restricted to well-resourced institutions by prohibitive computational barriers. End-to-end transformer architectures achieve strong accuracy but demand hundreds of GPU hours for domain adaptation, limiting accessibility for practitioners and digital humanities scholars. We present a modular detection-and-correction framework that achieves near-SOTA accuracy with single-GPU training. Our approach decouples lightweight visual character detection (domain-agnostic) from domain-specific linguistic correction using pretrained sequence models including T5, ByT5, and BART. By training the correctors entirely on synthetic noise, we enable annotation-free domain adaptation without requiring labeled target images. Evaluating across modern clean handwriting, cursive script, and historical documents, we identify a critical "Pareto frontier" in architecture selection: T5-Base excels on modern text with standard vocabulary, whereas ByT5-Base dominates on historical documents by reconstructing archaic spellings at the byte level. Our results demonstrate that this decoupled paradigm matches end-to-end transformer accuracy while reducing compute by approximately 95%, establishing a viable, resource-efficient alternative to monolithic OCR architectures.
Self-Tuning Sparse Attention: Multi-Fidelity Hyperparameter Optimization for Transformer Acceleration
Mar 19, 2026Sparse attention mechanisms promise to break the quadratic bottleneck of long-context transformers, yet production adoption remains limited by a critical usability gap: optimal hyperparameters vary substantially across layers and models, and current methods (e.g., SpargeAttn) rely on manual grid search to identify them. We propose AFBS-BO (Adaptive Fidelity Binary Search with Bayesian Optimization), a fully automated framework that discovers optimal layer- and head-specific hyperparameters without human intervention. Our hybrid algorithm combines Bayesian Optimization for global exploration with binary search for local refinement, leveraging multi-fidelity evaluation across sequence lengths to reduce tuning cost. On Llama-2-7B, AFBS-BO accelerates hyperparameter discovery by 3.4x with 8.8x fewer evaluations than grid search, and identifies high-sparsity configurations that outperform existing sparse attention baselines while closely matching dense attention quality. By transforming sparse attention from a manually tuned heuristic into a self-optimizing primitive, AFBS-BO enables plug-and-play acceleration across diverse transformer architectures and domains.
Adaptive Temperature Based on Logits Correlation in Knowledge Distillation
Mar 12, 2025Knowledge distillation is a technique to imitate a performance that a deep learning model has, but reduce the size on another model. It applies the outputs of a model to train another model having comparable accuracy. These two distinct models are similar to the way information is delivered in human society, with one acting as the "teacher" and the other as the "student". Softmax plays a role in comparing logits generated by models with each other by converting probability distributions. It delivers the logits of a teacher to a student with compression through a parameter named temperature. Tuning this variable reinforces the distillation performance. Although only this parameter helps with the interaction of logits, it is not clear how temperatures promote information transfer. In this paper, we propose a novel approach to calculate the temperature. Our method only refers to the maximum logit generated by a teacher model, which reduces computational time against state-of-the-art methods. Our method shows a promising result in different student and teacher models on a standard benchmark dataset. Algorithms using temperature can obtain the improvement by plugging in this dynamic approach. Furthermore, the approximation of the distillation process converges to a correlation of logits by both models. This reinforces the previous argument that the distillation conveys the relevance of logits. We report that this approximating algorithm yields a higher temperature compared to the commonly used static values in testing.
Fine-tuning BERT with Bidirectional LSTM for Fine-grained Movie Reviews Sentiment Analysis
Feb 28, 2025Sentiment Analysis (SA) is instrumental in understanding peoples viewpoints facilitating social media monitoring recognizing products and brands and gauging customer satisfaction. Consequently SA has evolved into an active research domain within Natural Language Processing (NLP). Many approaches outlined in the literature devise intricate frameworks aimed at achieving high accuracy, focusing exclusively on either binary sentiment classification or fine-grained sentiment classification. In this paper our objective is to fine-tune the pre-trained BERT model with Bidirectional LSTM (BiLSTM) to enhance both binary and fine-grained SA specifically for movie reviews. Our approach involves conducting sentiment classification for each review followed by computing the overall sentiment polarity across all reviews. We present our findings on binary classification as well as fine-grained classification utilizing benchmark datasets. Additionally we implement and assess two accuracy improvement techniques Synthetic Minority Oversampling Technique (SMOTE) and NLP Augmenter (NLPAUG) to bolster the models generalization in fine-grained sentiment classification. Finally a heuristic algorithm is employed to calculate the overall polarity of predicted reviews from the BERT+BiLSTM output vector. Our approach performs comparably with state-of-the-art (SOTA) techniques in both classifications. For instance in binary classification we achieve 97.67% accuracy surpassing the leading SOTA model NB-weighted-BON+dv-cosine by 0.27% on the renowned IMDb dataset. Conversely for five-class classification on SST-5 while the top SOTA model RoBERTa+large+Self-explaining attains 55.5% accuracy our model achieves 59.48% accuracy surpassing the BERT-large baseline by 3.6%.
Sentiment Analysis of Movie Reviews Using BERT
Feb 26, 2025Sentiment Analysis (SA) or opinion mining is analysis of emotions and opinions from any kind of text. SA helps in tracking peoples viewpoints and it is an important factor when it comes to social media monitoring product and brand recognition customer satisfaction customer loyalty advertising and promotions success and product acceptance. That is why SA is one of the active research areas in Natural Language Processing (NLP). SA is applied on data sourced from various media platforms to mine sentiment knowledge from them. Various approaches have been deployed in the literature to solve the problem. Most techniques devise complex and sophisticated frameworks in order to attain optimal accuracy. This work aims to finetune Bidirectional Encoder Representations from Transformers (BERT) with Bidirectional Long Short-Term Memory (BiLSTM) for movie reviews sentiment analysis and still provide better accuracy than the State-of-The-Art (SOTA) methods. The paper also shows how sentiment analysis can be applied if someone wants to recommend a certain movie for example by computing overall polarity of its sentiments predicted by the model. That is our proposed method serves as an upper-bound baseline in prediction of a predominant reaction to a movie. To compute overall polarity a heuristic algorithm is applied to BERTBiLSTM output vector. Our model can be extended to three-class four-class or any fine-grained classification and apply overall polarity computation again. This is intended to be exploited in future work.
Towards Modeling Data Quality and Machine Learning Model Performance
Dec 08, 2024



Understanding the effect of uncertainty and noise in data on machine learning models (MLM) is crucial in developing trust and measuring performance. In this paper, a new model is proposed to quantify uncertainties and noise in data on MLMs. Using the concept of signal-to-noise ratio (SNR), a new metric called deterministic-non-deterministic ratio (DDR) is proposed to formulate performance of a model. Using synthetic data in experiments, we show how accuracy can change with DDR and how we can use DDR-accuracy curves to determine performance of a model.
BSSAD: Towards A Novel Bayesian State-Space Approach for Anomaly Detection in Multivariate Time Series
Jan 30, 2023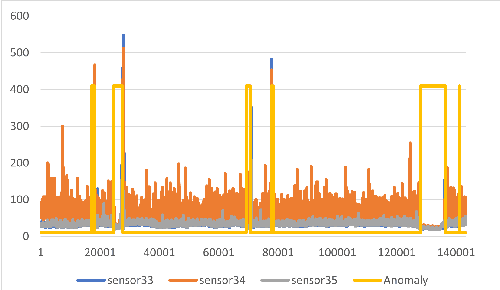
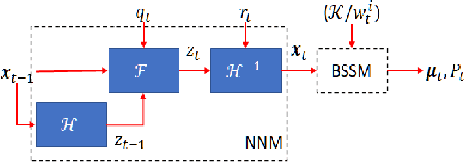
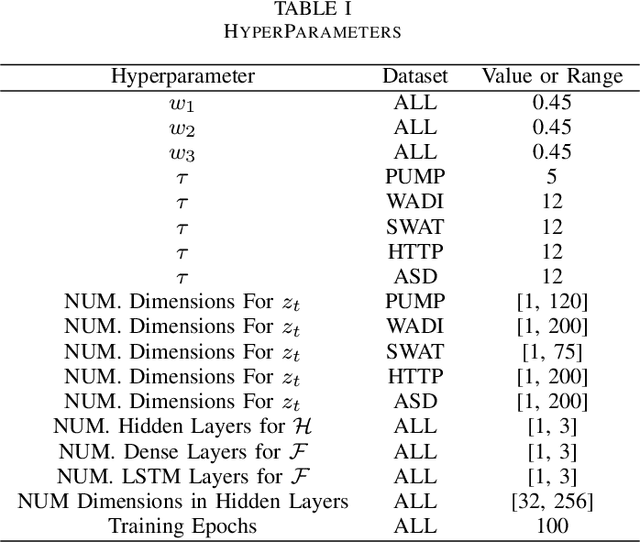
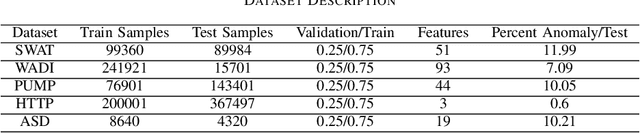
Detecting anomalies in multivariate time series(MTS) data plays an important role in many domains. The abnormal values could indicate events, medical abnormalities,cyber-attacks, or faulty devices which if left undetected could lead to significant loss of resources, capital, or human lives. In this paper, we propose a novel and innovative approach to anomaly detection called Bayesian State-Space Anomaly Detection(BSSAD). The BSSAD consists of two modules: the neural network module and the Bayesian state-space module. The design of our approach combines the strength of Bayesian state-space algorithms in predicting the next state and the effectiveness of recurrent neural networks and autoencoders in understanding the relationship between the data to achieve high accuracy in detecting anomalies. The modular design of our approach allows flexibility in implementation with the option of changing the parameters of the Bayesian state-space models or swap-ping neural network algorithms to achieve different levels of performance. In particular, we focus on using Bayesian state-space models of particle filters and ensemble Kalman filters. We conducted extensive experiments on five different datasets. The experimental results show the superior performance of our model over baselines, achieving an F1-score greater than 0.95. In addition, we also propose using a metric called MatthewCorrelation Coefficient (MCC) to obtain more comprehensive information about the accuracy of anomaly detection.
WaveNets: Wavelet Channel Attention Networks
Nov 04, 2022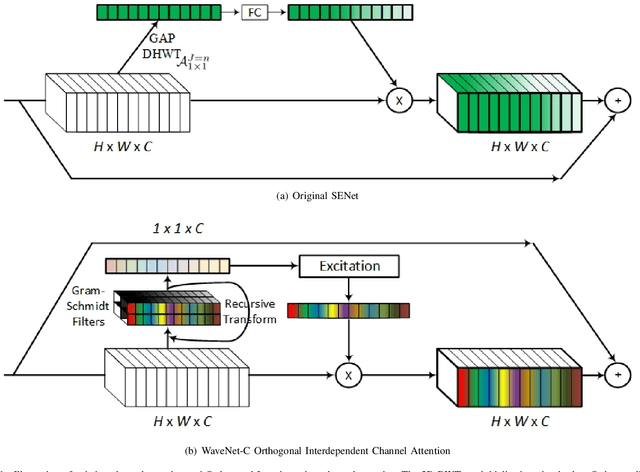

Channel Attention reigns supreme as an effective technique in the field of computer vision. However, the proposed channel attention by SENet suffers from information loss in feature learning caused by the use of Global Average Pooling (GAP) to represent channels as scalars. Thus, designing effective channel attention mechanisms requires finding a solution to enhance features preservation in modeling channel inter-dependencies. In this work, we utilize Wavelet transform compression as a solution to the channel representation problem. We first test wavelet transform as an Auto-Encoder model equipped with conventional channel attention module. Next, we test wavelet transform as a standalone channel compression method. We prove that global average pooling is equivalent to the recursive approximate Haar wavelet transform. With this proof, we generalize channel attention using Wavelet compression and name it WaveNet. Implementation of our method can be embedded within existing channel attention methods with a couple of lines of code. We test our proposed method using ImageNet dataset for image classification task. Our method outperforms the baseline SENet, and achieves the state-of-the-art results. Our code implementation is publicly available at https://github.com/hady1011/WaveNet-C.
GHM Wavelet Transform for Deep Image Super Resolution
Apr 16, 2022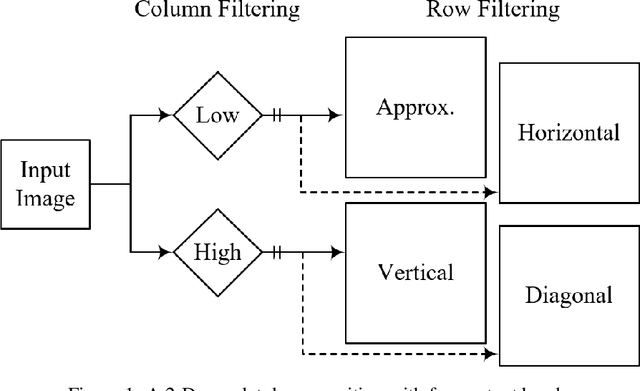
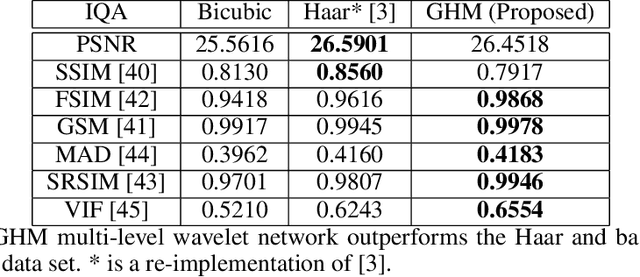
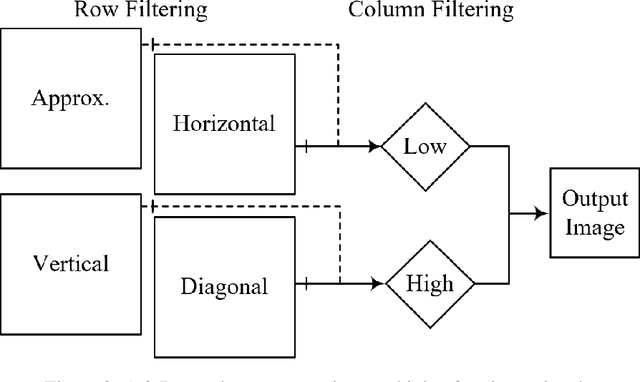
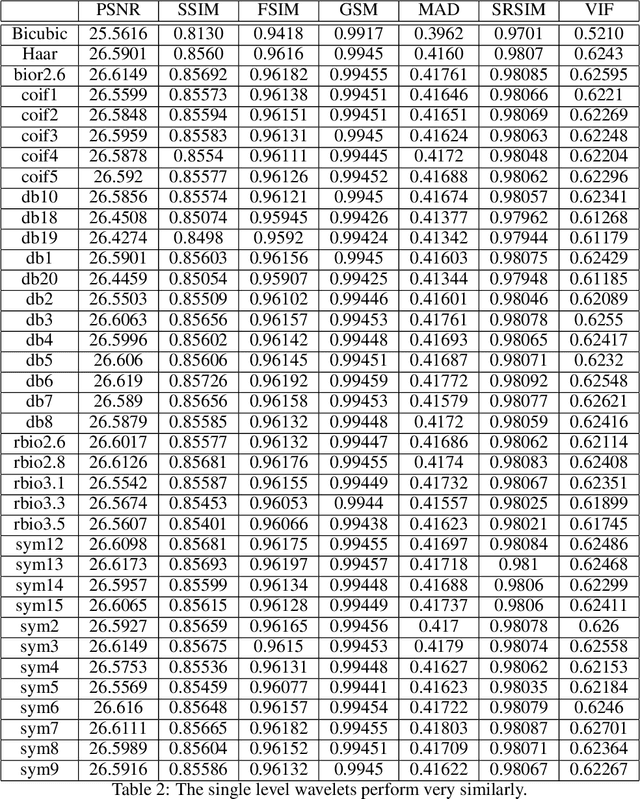
The GHM multi-level discrete wavelet transform is proposed as preprocessing for image super resolution with convolutional neural networks. Previous works perform analysis with the Haar wavelet only. In this work, 37 single-level wavelets are experimentally analyzed from Haar, Daubechies, Biorthogonal, Reverse Biorthogonal, Coiflets, and Symlets wavelet families. All single-level wavelets report similar results indicating that the convolutional neural network is invariant to choice of wavelet in a single-level filter approach. However, the GHM multi-level wavelet achieves higher quality reconstructions than the single-level wavelets. Three large data sets are used for the experiments: DIV2K, a dataset of textures, and a dataset of satellite images. The approximate high resolution images are compared using seven objective error measurements. A convolutional neural network based approach using wavelet transformed images has good results in the literature.
Neighborhood Random Walk Graph Sampling for Regularized Bayesian Graph Convolutional Neural Networks
Dec 14, 2021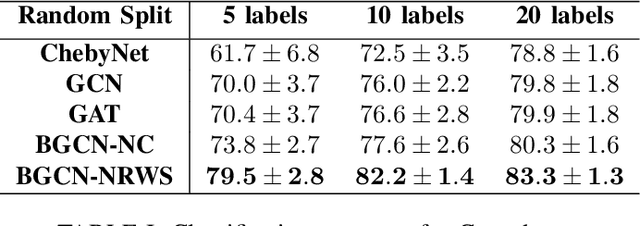

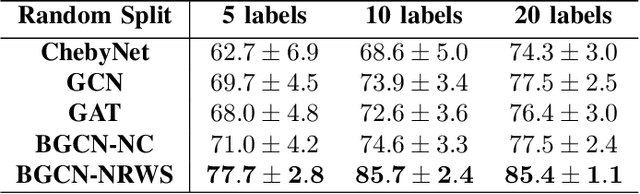
In the modern age of social media and networks, graph representations of real-world phenomena have become an incredibly useful source to mine insights. Often, we are interested in understanding how entities in a graph are interconnected. The Graph Neural Network (GNN) has proven to be a very useful tool in a variety of graph learning tasks including node classification, link prediction, and edge classification. However, in most of these tasks, the graph data we are working with may be noisy and may contain spurious edges. That is, there is a lot of uncertainty associated with the underlying graph structure. Recent approaches to modeling uncertainty have been to use a Bayesian framework and view the graph as a random variable with probabilities associated with model parameters. Introducing the Bayesian paradigm to graph-based models, specifically for semi-supervised node classification, has been shown to yield higher classification accuracies. However, the method of graph inference proposed in recent work does not take into account the structure of the graph. In this paper, we propose a novel algorithm called Bayesian Graph Convolutional Network using Neighborhood Random Walk Sampling (BGCN-NRWS), which uses a Markov Chain Monte Carlo (MCMC) based graph sampling algorithm utilizing graph structure, reduces overfitting by using a variational inference layer, and yields consistently competitive classification results compared to the state-of-the-art in semi-supervised node classification.