 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2: Mind-to-Mind Emotional Support System with Bidirectional Cognitive Discourse Analysis
Mar 17, 2025Emotional support (ES) systems alleviate users' mental distress by generating strategic supportive dialogues based on diverse user situations. However, ES systems are limited in their ability to generate effective ES dialogues that include timely context and interpretability, hindering them from earning public trust. Driven by cognitive models, we propose Mind-to-Mind (Mind2), an ES framework that approaches interpretable ES context modeling for the ES dialogue generation task from a discourse analysis perspective. Specifically, we perform cognitive discourse analysis on ES dialogues according to our dynamic discourse context propagation window, which accommodates evolving context as the conversation between the ES system and user progresses. To enhance interpretability, Mind2 prioritizes details that reflect each speaker's belief about the other speaker with bidirectionality, integrating Theory-of-Mind, physiological expected utility, and cognitive rationality to extract cognitive knowledge from ES conversations. Experimental results support that Mind2 achieves competitive performance versus state-of-the-art ES systems while trained with only 10\% of the available training data.
Improving Cross-Domain Hate Speech Generalizability with Emotion Knowledge
Nov 24, 2023Reliable automatic hate speech (HS) detection systems must adapt to the in-flow of diverse new data to curtail hate speech. However, hate speech detection systems commonly lack generalizability in identifying hate speech dissimilar to data used in training, impeding their robustness in real-world deployments. In this work, we propose a hate speech generalization framework that leverages emotion knowledge in a multitask architecture to improve the generalizability of hate speech detection in a cross-domain setting. We investigate emotion corpora with varying emotion categorical scopes to determine the best corpus scope for supplying emotion knowledge to foster generalized hate speech detection. We further assess the relationship between using pretrained Transformers models adapted for hate speech and its effect on our emotion-enriched hate speech generalization model. We perform extensive experiments on six publicly available datasets sourced from different online domains and show that our emotion-enriched HS detection generalization method demonstrates consistent generalization improvement in cross-domain evaluation, increasing generalization performance up to 18.1% and average cross-domain performance up to 8.5%, according to the F1 measure.
WaveNets: Wavelet Channel Attention Networks
Nov 04, 2022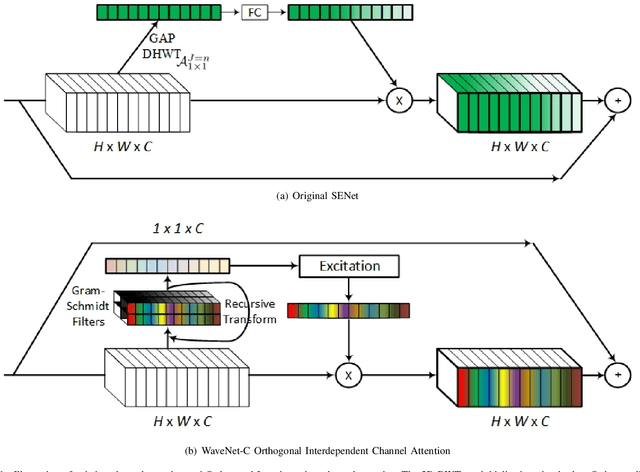

Channel Attention reigns supreme as an effective technique in the field of computer vision. However, the proposed channel attention by SENet suffers from information loss in feature learning caused by the use of Global Average Pooling (GAP) to represent channels as scalars. Thus, designing effective channel attention mechanisms requires finding a solution to enhance features preservation in modeling channel inter-dependencies. In this work, we utilize Wavelet transform compression as a solution to the channel representation problem. We first test wavelet transform as an Auto-Encoder model equipped with conventional channel attention module. Next, we test wavelet transform as a standalone channel compression method. We prove that global average pooling is equivalent to the recursive approximate Haar wavelet transform. With this proof, we generalize channel attention using Wavelet compression and name it WaveNet. Implementation of our method can be embedded within existing channel attention methods with a couple of lines of code. We test our proposed method using ImageNet dataset for image classification task. Our method outperforms the baseline SENet, and achieves the state-of-the-art results. Our code implementation is publicly available at https://github.com/hady1011/WaveNet-C.