 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Diffusion Autoencoders: Toward Counterfactual Generation via Diffusion Probabilistic Models
Apr 27, 2024



Diffusion probabilistic models (DPMs) have become the state-of-the-art in high-quality image generation. However, DPMs have an arbitrary noisy latent space with no interpretable or controllable semantics. Although there has been significant research effort to improve image sample quality, there is little work on representation-controlled generation using diffusion models. Specifically, causal modeling and controllable counterfactual generation using DPMs is an underexplored area. In this work, we propose CausalDiffAE, a diffusion-based causal representation learning framework to enable counterfactual generation according to a specified causal model. Our key idea is to use an encoder to extract high-level semantically meaningful causal variables from high-dimensional data and model stochastic variation using reverse diffusion. We propose a causal encoding mechanism that maps high-dimensional data to causally related latent factors and parameterize the causal mechanisms among latent factors using neural networks. To enforce the disentanglement of causal variables, we formulate a variational objective and leverage auxiliary label information in a prior to regularize the latent space. We propose a DDIM-based counterfactual generation procedure subject to do-interventions. Finally, to address the limited label supervision scenario, we also study the application of CausalDiffAE when a part of the training data is unlabeled, which also enables granular control over the strength of interventions in generating counterfactuals during inference. We empirically show that CausalDiffAE learns a disentangled latent space and is capable of generating high-quality counterfactual images.
From Identifiable Causal Representations to Controllable Counterfactual Generation: A Survey on Causal Generative Modeling
Oct 17, 2023



Deep generative models have shown tremendous success in data density estimation and data generation from finite samples. While these models have shown impressive performance by learning correlations among features in the data, some fundamental shortcomings are their lack of explainability, the tendency to induce spurious correlations, and poor out-of-distribution extrapolation. In an effort to remedy such challenges, one can incorporate the theory of causality in deep generative modeling. Structural causal models (SCMs) describe data-generating processes and model complex causal relationships and mechanisms among variables in a system. Thus, SCMs can naturally be combined with deep generative models. Causal models offer several beneficial properties to deep generative models, such as distribution shift robustness, fairness, and interoperability. We provide a technical survey on causal generative modeling categorized into causal representation learning and controllable counterfactual generation methods. We focus on fundamental theory, formulations, drawbacks, datasets, metrics, and applications of causal generative models in fairness, privacy, out-of-distribution generalization, and precision medicine. We also discuss open problems and fruitful research directions for future work in the field.
Learning Causally Disentangled Representations via the Principle of Independent Causal Mechanisms
Jun 02, 2023



Learning disentangled causal representations is a challenging problem that has gained significant attention recently due to its implications for extracting meaningful information for downstream tasks. In this work, we define a new notion of causal disentanglement from the perspective of independent causal mechanisms. We propose ICM-VAE, a framework for learning causally disentangled representations supervised by causally related observed labels. We model causal mechanisms using learnable flow-based diffeomorphic functions to map noise variables to latent causal variables. Further, to promote the disentanglement of causal factors, we propose a causal disentanglement prior that utilizes the known causal structure to encourage learning a causally factorized distribution in the latent space. Under relatively mild conditions, we provide theoretical results showing the identifiability of causal factors and mechanisms up to permutation and elementwise reparameterization. We empirically demonstrate that our framework induces highly disentangled causal factors, improves interventional robustness, and is compatible with counterfactual generation.
Neighborhood Random Walk Graph Sampling for Regularized Bayesian Graph Convolutional Neural Networks
Dec 14, 2021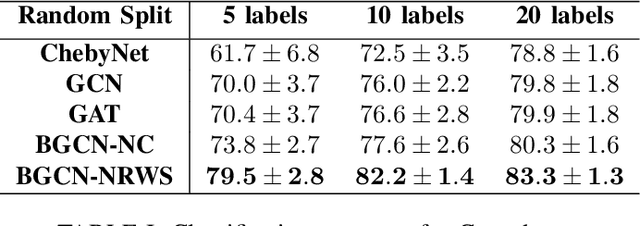

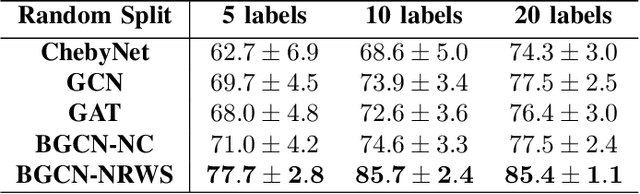
In the modern age of social media and networks, graph representations of real-world phenomena have become an incredibly useful source to mine insights. Often, we are interested in understanding how entities in a graph are interconnected. The Graph Neural Network (GNN) has proven to be a very useful tool in a variety of graph learning tasks including node classification, link prediction, and edge classification. However, in most of these tasks, the graph data we are working with may be noisy and may contain spurious edges. That is, there is a lot of uncertainty associated with the underlying graph structure. Recent approaches to modeling uncertainty have been to use a Bayesian framework and view the graph as a random variable with probabilities associated with model parameters. Introducing the Bayesian paradigm to graph-based models, specifically for semi-supervised node classification, has been shown to yield higher classification accuracies. However, the method of graph inference proposed in recent work does not take into account the structure of the graph. In this paper, we propose a novel algorithm called Bayesian Graph Convolutional Network using Neighborhood Random Walk Sampling (BGCN-NRWS), which uses a Markov Chain Monte Carlo (MCMC) based graph sampling algorithm utilizing graph structure, reduces overfitting by using a variational inference layer, and yields consistently competitive classification results compared to the state-of-the-art in semi-supervised node classification.
A Comparative Study of Transformer-Based Language Models on Extractive Question Answering
Oct 07, 2021
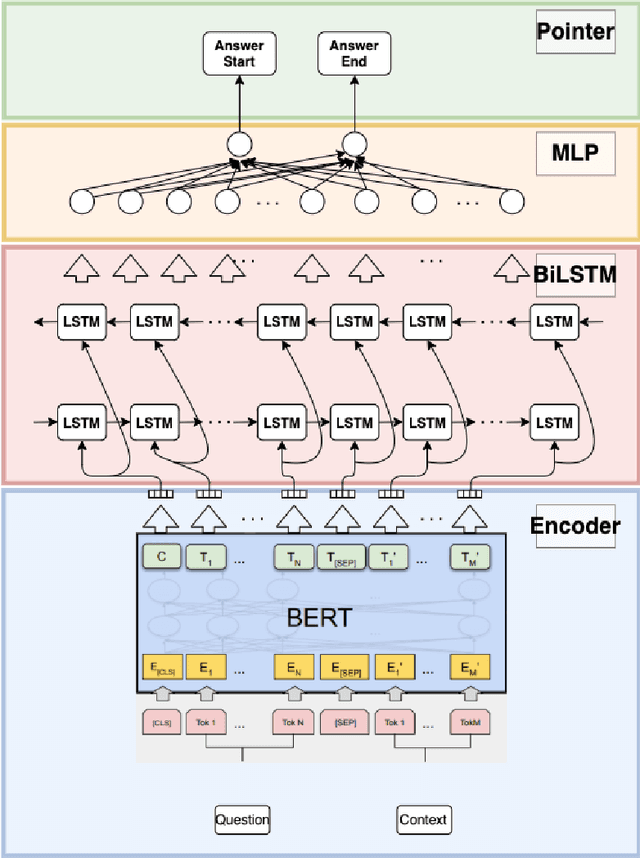


Question Answering (QA) is a task in natural language processing that has seen considerable growth after the advent of transformers. There has been a surge in QA datasets that have been proposed to challenge natural language processing models to improve human and existing model performance. Many pre-trained language models have proven to be incredibly effective at the task of extractive question answering. However, generalizability remains as a challenge for the majority of these models. That is, some datasets require models to reason more than others. In this paper, we train various pre-trained language models and fine-tune them on multiple question answering datasets of varying levels of difficulty to determine which of the models are capable of generalizing the most comprehensively across different datasets. Further, we propose a new architecture, BERT-BiLSTM, and compare it with other language models to determine if adding more bidirectionality can improve model performance. Using the F1-score as our metric, we find that the RoBERTa and BART pre-trained models perform the best across all datasets and that our BERT-BiLSTM model outperforms the baseline BERT model.