 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning On-Road Visual Control for Self-Driving Vehicles with Auxiliary Tasks
Dec 19, 2018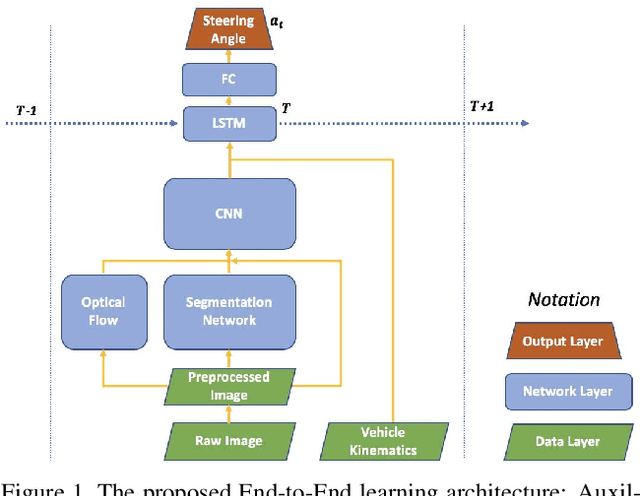


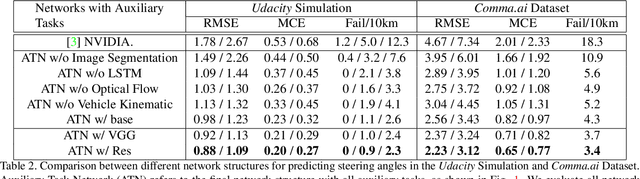
A safe and robust on-road navigation system is a crucial component of achieving fully automated vehicles. NVIDIA recently proposed an End-to-End algorithm that can directly learn steering commands from raw pixels of a front camera by using one convolutional neural network. In this paper, we leverage auxiliary information aside from raw images and design a novel network structure, called Auxiliary Task Network (ATN), to help boost the driving performance while maintaining the advantage of minimal training data and an End-to-End training method. In this network, we introduce human prior knowledge into vehicle navigation by transferring features from image recognition tasks. Image semantic segmentation is applied as an auxiliary task for navigation. We consider temporal information by introducing an LSTM module and optical flow to the network. Finally, we combine vehicle kinematics with a sensor fusion step. We discuss the benefits of our method over state-of-the-art visual navigation methods both in the Udacity simulation environment and on the real-world Comma.ai dataset.
Model Learning for Look-ahead Exploration in Continuous Control
Nov 20, 2018
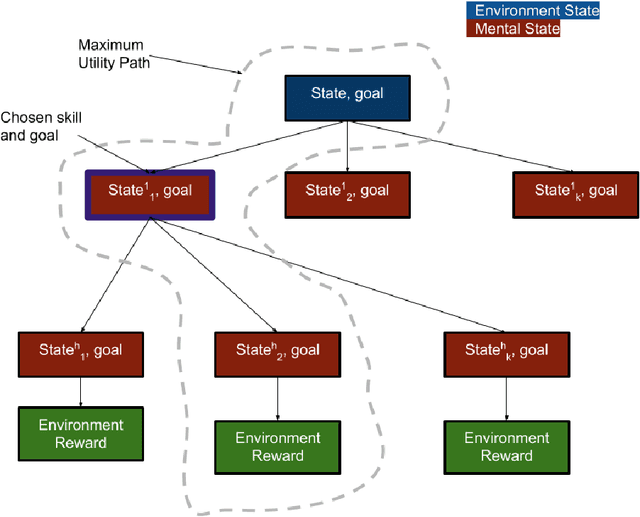


We propose an exploration method that incorporates look-ahead search over basic learnt skills and their dynamics, and use it for reinforcement learning (RL) of manipulation policies . Our skills are multi-goal policies learned in isolation in simpler environments using existing multigoal RL formulations, analogous to options or macroactions. Coarse skill dynamics, i.e., the state transition caused by a (complete) skill execution, are learnt and are unrolled forward during lookahead search. Policy search benefits from temporal abstraction during exploration, though itself operates over low-level primitive actions, and thus the resulting policies does not suffer from suboptimality and inflexibility caused by coarse skill chaining. We show that the proposed exploration strategy results in effective learning of complex manipulation policies faster than current state-of-the-art RL methods, and converges to better policies than methods that use options or parametrized skills as building blocks of the policy itself, as opposed to guiding exploration. We show that the proposed exploration strategy results in effective learning of complex manipulation policies faster than current state-of-the-art RL methods, and converges to better policies than methods that use options or parameterized skills as building blocks of the policy itself, as opposed to guiding exploration.
Social Attention: Modeling Attention in Human Crowds
Oct 29, 2018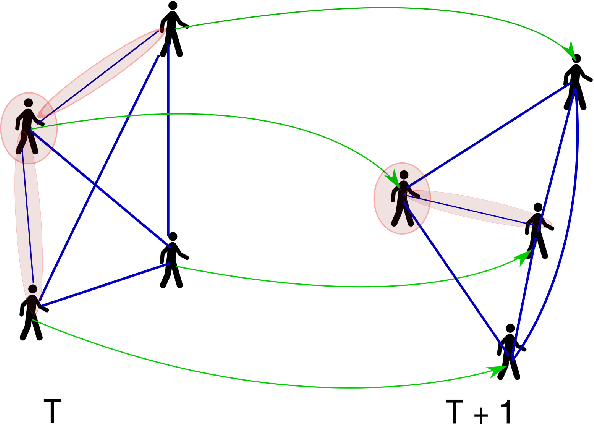



Robots that navigate through human crowds need to be able to plan safe, efficient, and human predictable trajectories. This is a particularly challenging problem as it requires the robot to predict future human trajectories within a crowd where everyone implicitly cooperates with each other to avoid collisions. Previous approaches to human trajectory prediction have modeled the interactions between humans as a function of proximity. However, that is not necessarily true as some people in our immediate vicinity moving in the same direction might not be as important as other people that are further away, but that might collide with us in the future. In this work, we propose Social Attention, a novel trajectory prediction model that captures the relative importance of each person when navigating in the crowd, irrespective of their proximity. We demonstrate the performance of our method against a state-of-the-art approach on two publicly available crowd datasets and analyze the trained attention model to gain a better understanding of which surrounding agents humans attend to, when navigating in a crowd.
Learning Neural Parsers with Deterministic Differentiable Imitation Learning
Sep 19, 2018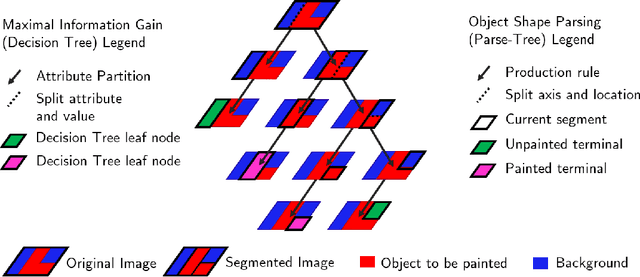


We explore the problem of learning to decompose spatial tasks into segments, as exemplified by the problem of a painting robot covering a large object. Inspired by the ability of classical decision tree algorithms to construct structured partitions of their input spaces, we formulate the problem of decomposing objects into segments as a parsing approach. We make the insight that the derivation of a parse-tree that decomposes the object into segments closely resembles a decision tree constructed by ID3, which can be done when the ground-truth available. We learn to imitate an expert parsing oracle, such that our neural parser can generalize to parse natural images without ground truth. We introduce a novel deterministic policy gradient update, DRAG (i.e., DeteRministically AGgrevate) in the form of a deterministic actor-critic variant of AggreVaTeD, to train our neural parser. From another perspective, our approach is a variant of the Deterministic Policy Gradient suitable for the imitation learning setting. The deterministic policy representation offered by training our neural parser with DRAG allows it to outperform state of the art imitation and reinforcement learning approaches.
Automatic Design of Task-specific Robotic Arms
Jun 19, 2018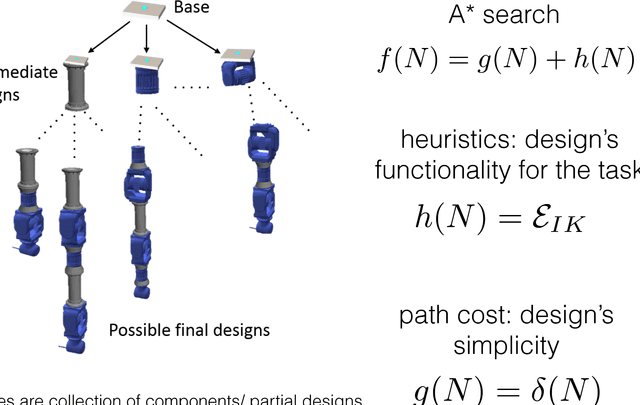
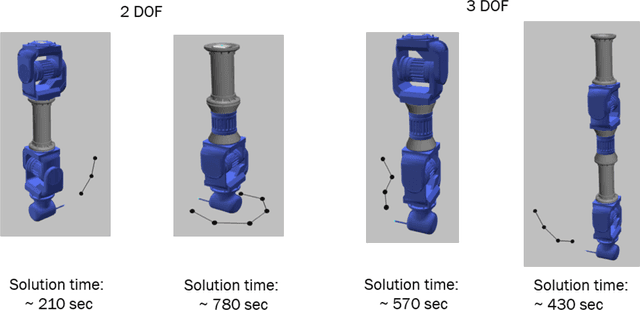

We present an interactive, computational design system for creating custom robotic arms given high-level task descriptions and environmental constraints. Various task requirements can be encoded as desired motion trajectories for the robot arm's end-effector. Given such end-effector trajectories, our system enables on-demand design of custom robot arms using a library of modular and reconfigurable parts such as actuators and connecting links. By searching through the combinatorial set of possible arrangements of these parts, our method generates a functional, as-simple-as-possible robot arm that is capable of tracking the desired trajectories. We demonstrate our system's capabilities by creating robot arm designs in simulation, for various trajectory following scenarios.
Modeling Cooperative Navigation in Dense Human Crowds
May 17, 2017



For robots to be a part of our daily life, they need to be able to navigate among crowds not only safely but also in a socially compliant fashion. This is a challenging problem because humans tend to navigate by implicitly cooperating with one another to avoid collisions, while heading toward their respective destinations. Previous approaches have used hand-crafted functions based on proximity to model human-human and human-robot interactions. However, these approaches can only model simple interactions and fail to generalize for complex crowded settings. In this paper, we develop an approach that models the joint distribution over future trajectories of all interacting agents in the crowd, through a local interaction model that we train using real human trajectory data. The interaction model infers the velocity of each agent based on the spatial orientation of other agents in his vicinity. During prediction, our approach infers the goal of the agent from its past trajectory and uses the learned model to predict its future trajectory. We demonstrate the performance of our method against a state-of-the-art approach on a public dataset and show that our model outperforms when predicting future trajectories for longer horizons.
Path Planning in Dynamic Environments with Adaptive Dimensionality
May 22, 2016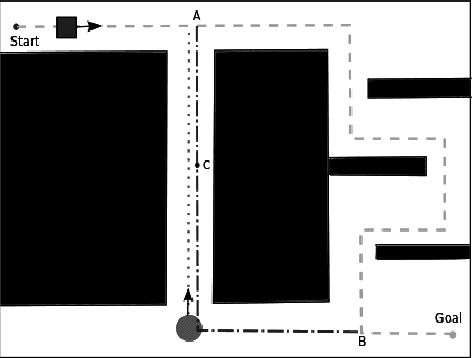
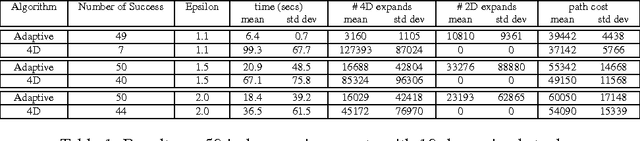
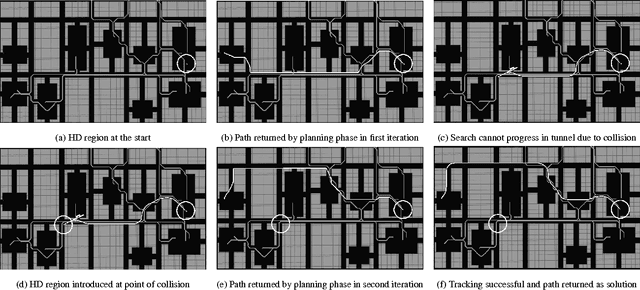
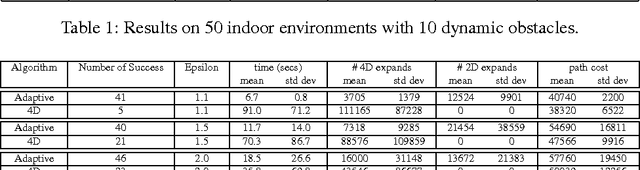
Path planning in the presence of dynamic obstacles is a challenging problem due to the added time dimension in search space. In approaches that ignore the time dimension and treat dynamic obstacles as static, frequent re-planning is unavoidable as the obstacles move, and their solutions are generally sub-optimal and can be incomplete. To achieve both optimality and completeness, it is necessary to consider the time dimension during planning. The notion of adaptive dimensionality has been successfully used in high-dimensional motion planning such as manipulation of robot arms, but has not been used in the context of path planning in dynamic environments. In this paper, we apply the idea of adaptive dimensionality to speed up path planning in dynamic environments for a robot with no assumptions on its dynamic model. Specifically, our approach considers the time dimension only in those regions of the environment where a potential collision may occur, and plans in a low-dimensional state-space elsewhere. We show that our approach is complete and is guaranteed to find a solution, if one exists, within a cost sub-optimality bound. We experimentally validate our method on the problem of 3D vehicle navigation (x, y, heading) in dynamic environments. Our results show that the presented approach achieves substantial speedups in planning time over 4D heuristic-based A*, especially when the resulting plan deviates significantly from the one suggested by the heuristic.
Autonomy Infused Teleoperation with Application to BCI Manipulation
Jun 07, 2015
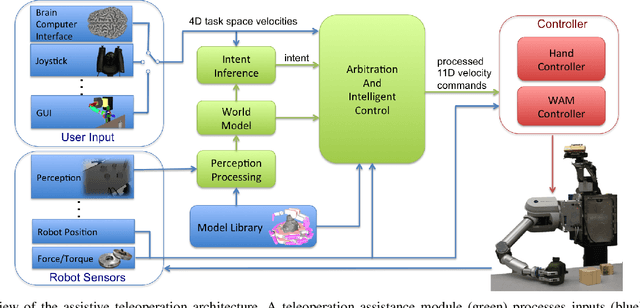


Robot teleoperation systems face a common set of challenges including latency, low-dimensional user commands, and asymmetric control inputs. User control with Brain-Computer Interfaces (BCIs) exacerbates these problems through especially noisy and erratic low-dimensional motion commands due to the difficulty in decoding neural activity. We introduce a general framework to address these challenges through a combination of computer vision, user intent inference, and arbitration between the human input and autonomous control schemes. Adjustable levels of assistance allow the system to balance the operator's capabilities and feelings of comfort and control while compensating for a task's difficulty. We present experimental results demonstrating significant performance improvement using the shared-control assistance framework on adapted rehabilitation benchmarks with two subjects implanted with intracortical brain-computer interfaces controlling a seven degree-of-freedom robotic manipulator as a prosthetic. Our results further indicate that shared assistance mitigates perceived user difficulty and even enables successful performance on previously infeasible tasks. We showcase the extensibility of our architecture with applications to quality-of-life tasks such as opening a door, pouring liquids from containers, and manipulation with novel objects in densely cluttered environments.