 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Edge Evaluation in Explicit Generalized Binomial Graphs
Jun 28, 2017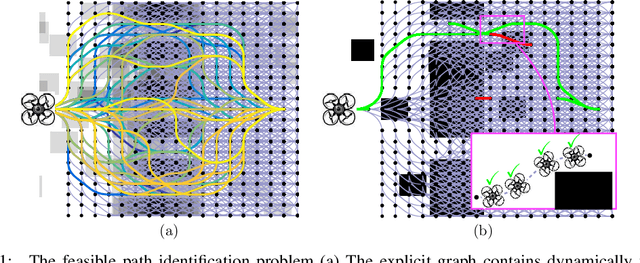
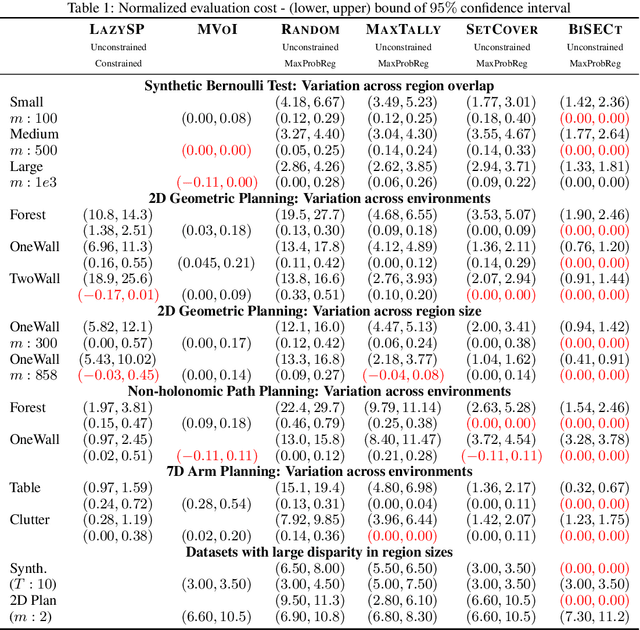
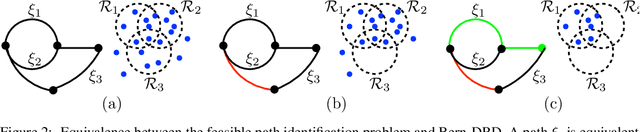
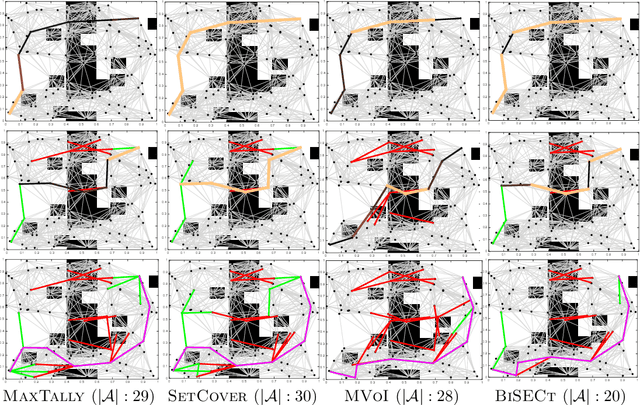
Robotic motion-planning problems, such as a UAV flying fast in a partially-known environment or a robot arm moving around cluttered objects, require finding collision-free paths quickly. Typically, this is solved by constructing a graph, where vertices represent robot configurations and edges represent potentially valid movements of the robot between these configurations. The main computational bottlenecks are expensive edge evaluations to check for collisions. State of the art planning methods do not reason about the optimal sequence of edges to evaluate in order to find a collision free path quickly. In this paper, we do so by drawing a novel equivalence between motion planning and the Bayesian active learning paradigm of decision region determination (DRD). Unfortunately, a straight application of existing methods requires computation exponential in the number of edges in a graph. We present BISECT, an efficient and near-optimal algorithm to solve the DRD problem when edges are independent Bernoulli random variables. By leveraging this property, we are able to significantly reduce computational complexity from exponential to linear in the number of edges. We show that BISECT outperforms several state of the art algorithms on a spectrum of planning problems for mobile robots, manipulators, and real flight data collected from a full scale helicopter.
Shared Autonomy via Hindsight Optimization for Teleoperation and Teaming
Jun 01, 2017

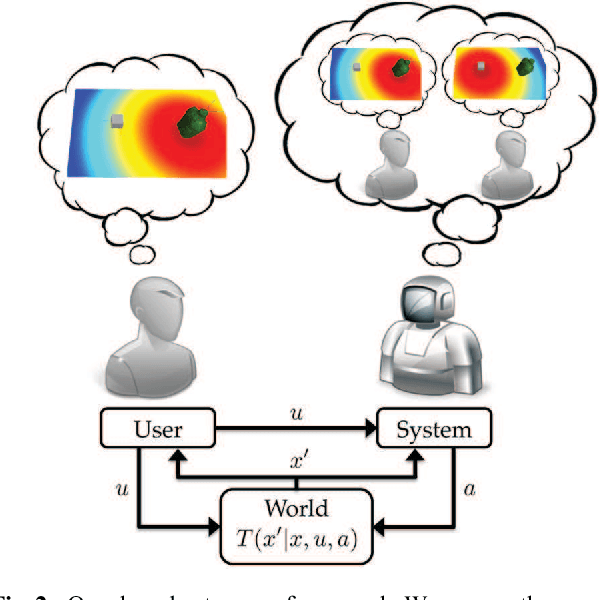
In shared autonomy, a user and autonomous system work together to achieve shared goals. To collaborate effectively, the autonomous system must know the user's goal. As such, most prior works follow a predict-then-act model, first predicting the user's goal with high confidence, then assisting given that goal. Unfortunately, confidently predicting the user's goal may not be possible until they have nearly achieved it, causing predict-then-act methods to provide little assistance. However, the system can often provide useful assistance even when confidence for any single goal is low (e.g. move towards multiple goals). In this work, we formalize this insight by modelling shared autonomy as a Partially Observable Markov Decision Process (POMDP), providing assistance that minimizes the expected cost-to-go with an unknown goal. As solving this POMDP optimally is intractable, we use hindsight optimization to approximate. We apply our framework to both shared-control teleoperation and human-robot teaming. Compared to predict-then-act methods, our method achieves goals faster, requires less user input, decreases user idling time, and results in fewer user-robot collisions.
Autonomy Infused Teleoperation with Application to BCI Manipulation
Jun 07, 2015
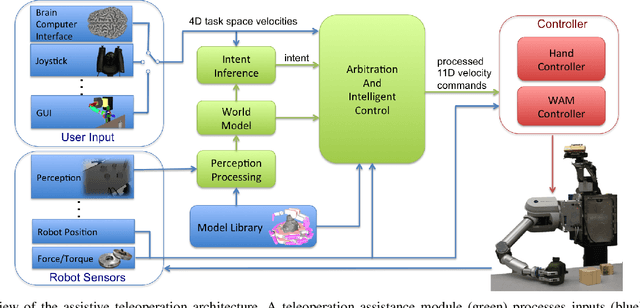


Robot teleoperation systems face a common set of challenges including latency, low-dimensional user commands, and asymmetric control inputs. User control with Brain-Computer Interfaces (BCIs) exacerbates these problems through especially noisy and erratic low-dimensional motion commands due to the difficulty in decoding neural activity. We introduce a general framework to address these challenges through a combination of computer vision, user intent inference, and arbitration between the human input and autonomous control schemes. Adjustable levels of assistance allow the system to balance the operator's capabilities and feelings of comfort and control while compensating for a task's difficulty. We present experimental results demonstrating significant performance improvement using the shared-control assistance framework on adapted rehabilitation benchmarks with two subjects implanted with intracortical brain-computer interfaces controlling a seven degree-of-freedom robotic manipulator as a prosthetic. Our results further indicate that shared assistance mitigates perceived user difficulty and even enables successful performance on previously infeasible tasks. We showcase the extensibility of our architecture with applications to quality-of-life tasks such as opening a door, pouring liquids from containers, and manipulation with novel objects in densely cluttered environments.
Shared Autonomy via Hindsight Optimization
Apr 17, 2015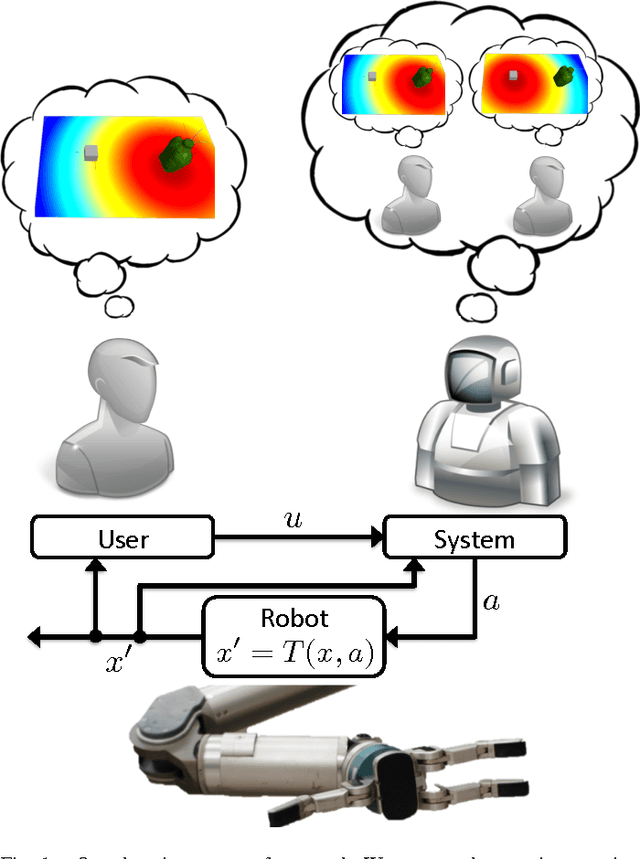
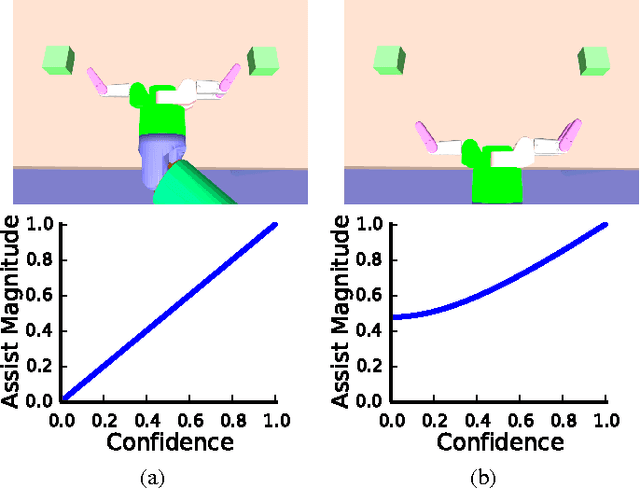
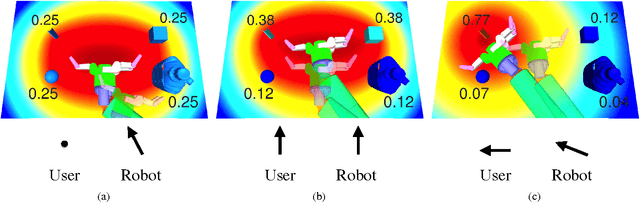
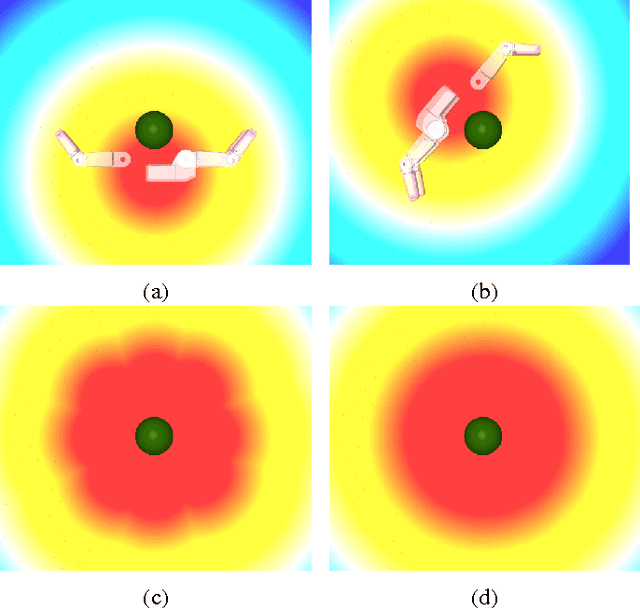
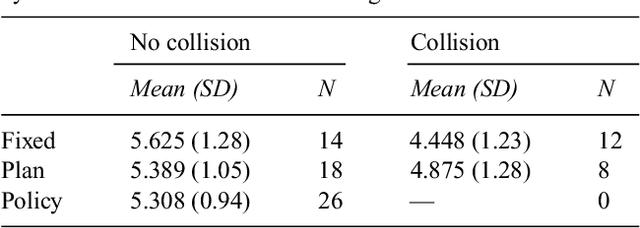
In shared autonomy, user input and robot autonomy are combined to control a robot to achieve a goal. Often, the robot does not know a priori which goal the user wants to achieve, and must both predict the user's intended goal, and assist in achieving that goal. We formulate the problem of shared autonomy as a Partially Observable Markov Decision Process with uncertainty over the user's goal. We utilize maximum entropy inverse optimal control to estimate a distribution over the user's goal based on the history of inputs. Ideally, the robot assists the user by solving for an action which minimizes the expected cost-to-go for the (unknown) goal. As solving the POMDP to select the optimal action is intractable, we use hindsight optimization to approximate the solution. In a user study, we compare our method to a standard predict-then-blend approach. We find that our method enables users to accomplish tasks more quickly while utilizing less input. However, when asked to rate each system, users were mixed in their assessment, citing a tradeoff between maintaining control authority and accomplishing tasks quickly.
Near Optimal Bayesian Active Learning for Decision Making
Feb 24, 2014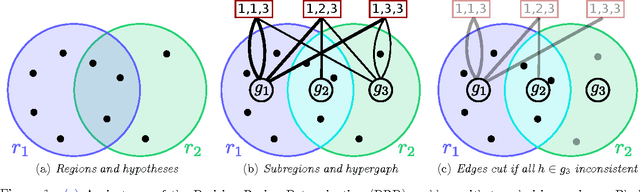
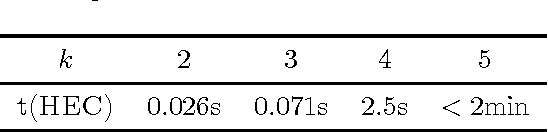
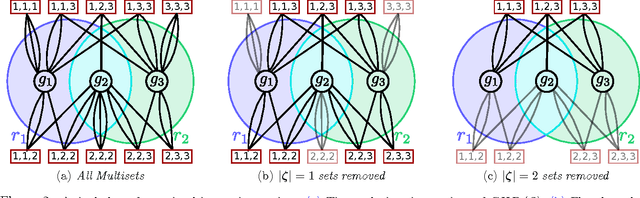

How should we gather information to make effective decisions? We address Bayesian active learning and experimental design problems, where we sequentially select tests to reduce uncertainty about a set of hypotheses. Instead of minimizing uncertainty per se, we consider a set of overlapping decision regions of these hypotheses. Our goal is to drive uncertainty into a single decision region as quickly as possible. We identify necessary and sufficient conditions for correctly identifying a decision region that contains all hypotheses consistent with observations. We develop a novel Hyperedge Cutting (HEC) algorithm for this problem, and prove that is competitive with the intractable optimal policy. Our efficient implementation of the algorithm relies on computing subsets of the complete homogeneous symmetric polynomials. Finally, we demonstrate its effectiveness on two practical applications: approximate comparison-based learning and active localization using a robot manipulator.
Efficient Touch Based Localization through Submodularity
Apr 23, 2013
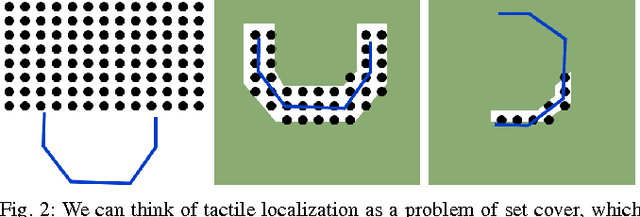
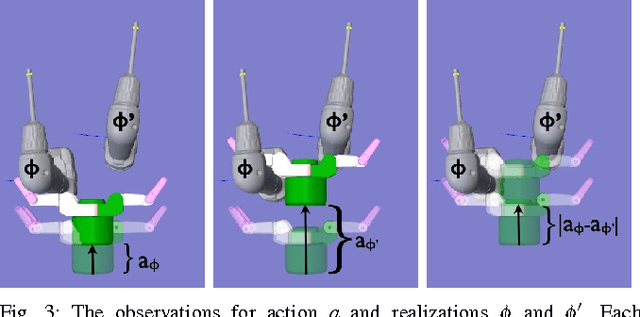
Many robotic systems deal with uncertainty by performing a sequence of information gathering actions. In this work, we focus on the problem of efficiently constructing such a sequence by drawing an explicit connection to submodularity. Ideally, we would like a method that finds the optimal sequence, taking the minimum amount of time while providing sufficient information. Finding this sequence, however, is generally intractable. As a result, many well-established methods select actions greedily. Surprisingly, this often performs well. Our work first explains this high performance -- we note a commonly used metric, reduction of Shannon entropy, is submodular under certain assumptions, rendering the greedy solution comparable to the optimal plan in the offline setting. However, reacting online to observations can increase performance. Recently developed notions of adaptive submodularity provide guarantees for a greedy algorithm in this online setting. In this work, we develop new methods based on adaptive submodularity for selecting a sequence of information gathering actions online. In addition to providing guarantees, we can capitalize on submodularity to attain additional computational speedups. We demonstrate the effectiveness of these methods in simulation and on a robot.