 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback in Imitation Learning: The Three Regimes of Covariate Shift
Feb 11, 2021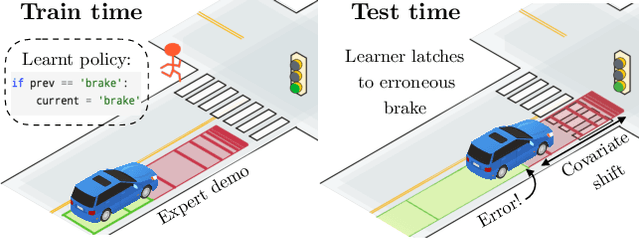
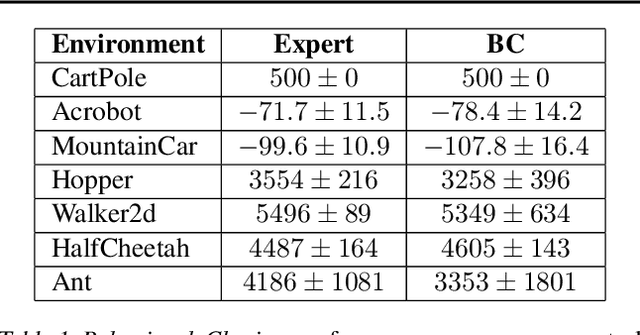
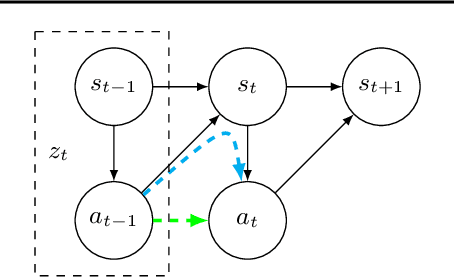

Imitation learning practitioners have often noted that conditioning policies on previous actions leads to a dramatic divergence between "held out" error and performance of the learner in situ. Interactive approaches can provably address this divergence but require repeated querying of a demonstrator. Recent work identifies this divergence as stemming from a "causal confound" in predicting the current action, and seek to ablate causal aspects of current state using tools from causal inference. In this work, we argue instead that this divergence is simply another manifestation of covariate shift, exacerbated particularly by settings of feedback between decisions and input features. The learner often comes to rely on features that are strongly predictive of decisions, but are subject to strong covariate shift. Our work demonstrates a broad class of problems where this shift can be mitigated, both theoretically and practically, by taking advantage of a simulator but without any further querying of expert demonstration. We analyze existing benchmarks used to test imitation learning approaches and find that these benchmarks are realizable and simple and thus insufficient for capturing the harder regimes of error compounding seen in real-world decision making problems. We find, in a surprising contrast with previous literature, but consistent with our theory, that naive behavioral cloning provides excellent results. We detail the need for new standardized benchmarks that capture the phenomena seen in robotics problems.
Predictive-State Decoders: Encoding the Future into Recurrent Networks
Sep 25, 2017

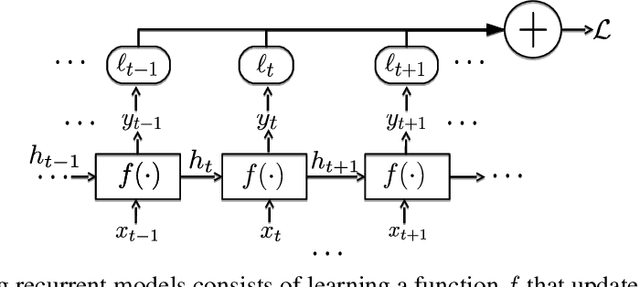

Recurrent neural networks (RNNs) are a vital modeling technique that rely on internal states learned indirectly by optimization of a supervised, unsupervised, or reinforcement training loss. RNNs are used to model dynamic processes that are characterized by underlying latent states whose form is often unknown, precluding its analytic representation inside an RNN. In the Predictive-State Representation (PSR) literature, latent state processes are modeled by an internal state representation that directly models the distribution of future observations, and most recent work in this area has relied on explicitly representing and targeting sufficient statistics of this probability distribution. We seek to combine the advantages of RNNs and PSRs by augmenting existing state-of-the-art recurrent neural networks with Predictive-State Decoders (PSDs), which add supervision to the network's internal state representation to target predicting future observations. Predictive-State Decoders are simple to implement and easily incorporated into existing training pipelines via additional loss regularization. We demonstrate the effectiveness of PSDs with experimental results in three different domains: probabilistic filtering, Imitation Learning, and Reinforcement Learning. In each, our method improves statistical performance of state-of-the-art recurrent baselines and does so with fewer iterations and less data.
Deeply AggreVaTeD: Differentiable Imitation Learning for Sequential Prediction
Mar 03, 2017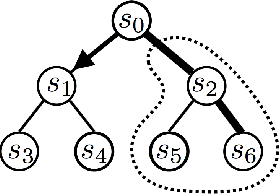


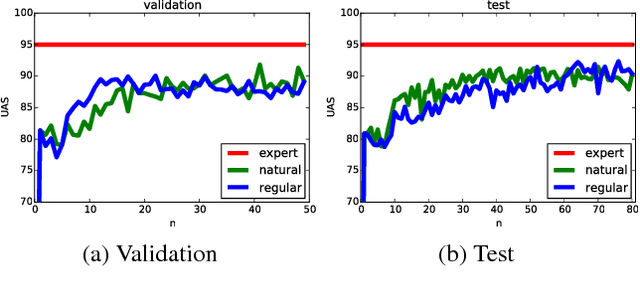
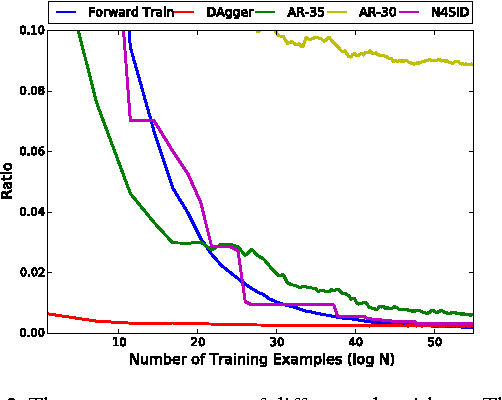
Researchers have demonstrated state-of-the-art performance in sequential decision making problems (e.g., robotics control, sequential prediction) with deep neural network models. One often has access to near-optimal oracles that achieve good performance on the task during training. We demonstrate that AggreVaTeD --- a policy gradient extension of the Imitation Learning (IL) approach of (Ross & Bagnell, 2014) --- can leverage such an oracle to achieve faster and better solutions with less training data than a less-informed Reinforcement Learning (RL) technique. Using both feedforward and recurrent neural network predictors, we present stochastic gradient procedures on a sequential prediction task, dependency-parsing from raw image data, as well as on various high dimensional robotics control problems. We also provide a comprehensive theoretical study of IL that demonstrates we can expect up to exponentially lower sample complexity for learning with AggreVaTeD than with RL algorithms, which backs our empirical findings. Our results and theory indicate that the proposed approach can achieve superior performance with respect to the oracle when the demonstrator is sub-optimal.
Gradient Boosting on Stochastic Data Streams
Mar 01, 2017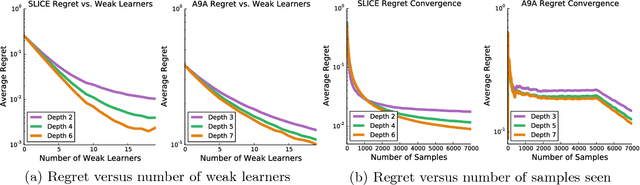
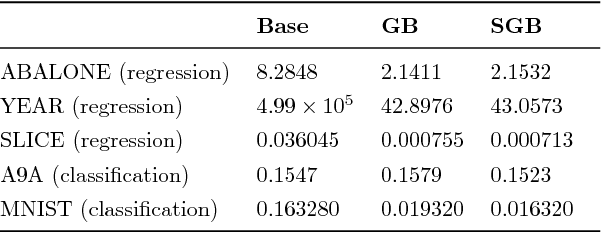
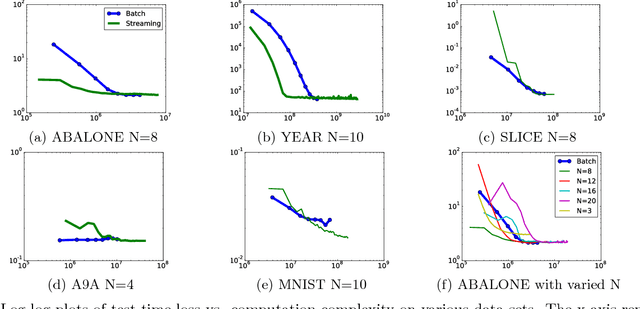
Boosting is a popular ensemble algorithm that generates more powerful learners by linearly combining base models from a simpler hypothesis class. In this work, we investigate the problem of adapting batch gradient boosting for minimizing convex loss functions to online setting where the loss at each iteration is i.i.d sampled from an unknown distribution. To generalize from batch to online, we first introduce the definition of online weak learning edge with which for strongly convex and smooth loss functions, we present an algorithm, Streaming Gradient Boosting (SGB) with exponential shrinkage guarantees in the number of weak learners. We further present an adaptation of SGB to optimize non-smooth loss functions, for which we derive a O(ln N/N) convergence rate. We also show that our analysis can extend to adversarial online learning setting under a stronger assumption that the online weak learning edge will hold in adversarial setting. We finally demonstrate experimental results showing that in practice our algorithms can achieve competitive results as classic gradient boosting while using less computation.
Learning to Filter with Predictive State Inference Machines
May 30, 2016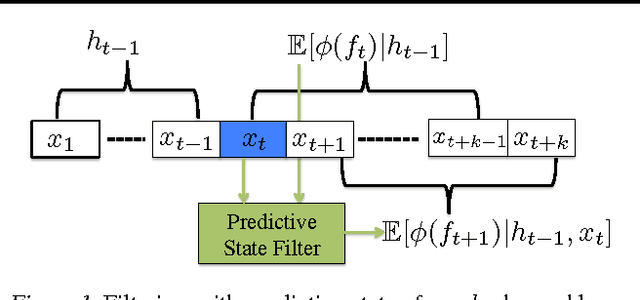


Latent state space models are a fundamental and widely used tool for modeling dynamical systems. However, they are difficult to learn from data and learned models often lack performance guarantees on inference tasks such as filtering and prediction. In this work, we present the PREDICTIVE STATE INFERENCE MACHINE (PSIM), a data-driven method that considers the inference procedure on a dynamical system as a composition of predictors. The key idea is that rather than first learning a latent state space model, and then using the learned model for inference, PSIM directly learns predictors for inference in predictive state space. We provide theoretical guarantees for inference, in both realizable and agnostic settings, and showcase practical performance on a variety of simulated and real world robotics benchmarks.
Autonomy Infused Teleoperation with Application to BCI Manipulation
Jun 07, 2015
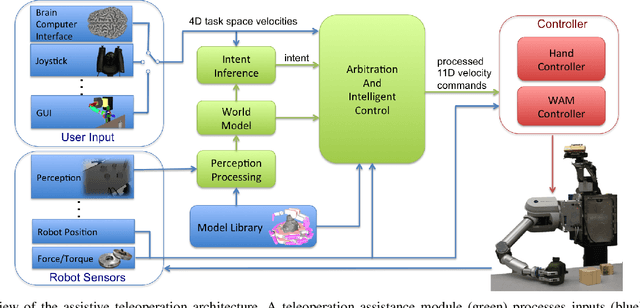


Robot teleoperation systems face a common set of challenges including latency, low-dimensional user commands, and asymmetric control inputs. User control with Brain-Computer Interfaces (BCIs) exacerbates these problems through especially noisy and erratic low-dimensional motion commands due to the difficulty in decoding neural activity. We introduce a general framework to address these challenges through a combination of computer vision, user intent inference, and arbitration between the human input and autonomous control schemes. Adjustable levels of assistance allow the system to balance the operator's capabilities and feelings of comfort and control while compensating for a task's difficulty. We present experimental results demonstrating significant performance improvement using the shared-control assistance framework on adapted rehabilitation benchmarks with two subjects implanted with intracortical brain-computer interfaces controlling a seven degree-of-freedom robotic manipulator as a prosthetic. Our results further indicate that shared assistance mitigates perceived user difficulty and even enables successful performance on previously infeasible tasks. We showcase the extensibility of our architecture with applications to quality-of-life tasks such as opening a door, pouring liquids from containers, and manipulation with novel objects in densely cluttered environments.