 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning via Focused Satisficing
May 20, 2025

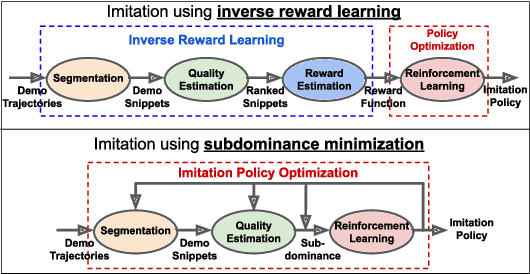

Imitation learning often assumes that demonstrations are close to optimal according to some fixed, but unknown, cost function. However, according to satisficing theory, humans often choose acceptable behavior based on their personal (and potentially dynamic) levels of aspiration, rather than achieving (near-) optimality. For example, a lunar lander demonstration that successfully lands without crashing might be acceptable to a novice despite being slow or jerky. Using a margin-based objective to guide deep reinforcement learning, our focused satisficing approach to imitation learning seeks a policy that surpasses the demonstrator's aspiration levels -- defined over trajectories or portions of trajectories -- on unseen demonstrations without explicitly learning those aspirations. We show experimentally that this focuses the policy to imitate the highest quality (portions of) demonstrations better than existing imitation learning methods, providing much higher rates of guaranteed acceptability to the demonstrator, and competitive true returns on a range of environments.
Modeling Low-Resource Health Coaching Dialogues via Neuro-Symbolic Goal Summarization and Text-Units-Text Generation
Apr 16, 2024
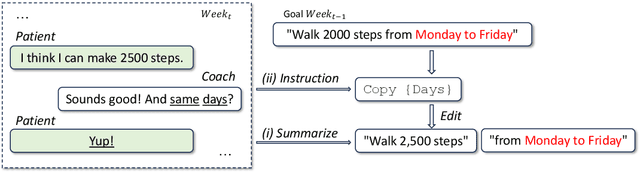
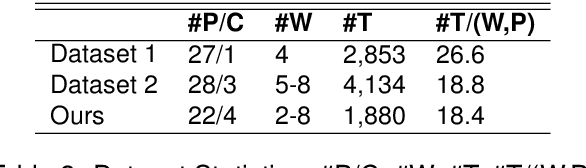
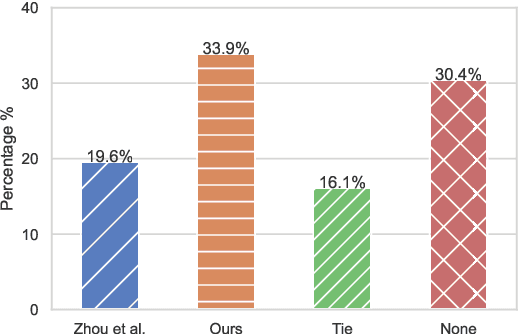
Health coaching helps patients achieve personalized and lifestyle-related goals, effectively managing chronic conditions and alleviating mental health issues. It is particularly beneficial, however cost-prohibitive, for low-socioeconomic status populations due to its highly personalized and labor-intensive nature. In this paper, we propose a neuro-symbolic goal summarizer to support health coaches in keeping track of the goals and a text-units-text dialogue generation model that converses with patients and helps them create and accomplish specific goals for physical activities. Our models outperform previous state-of-the-art while eliminating the need for predefined schema and corresponding annotation. We also propose a new health coaching dataset extending previous work and a metric to measure the unconventionality of the patient's response based on data difficulty, facilitating potential coach alerts during deployment.
Towards Enhancing Health Coaching Dialogue in Low-Resource Settings
Apr 13, 2024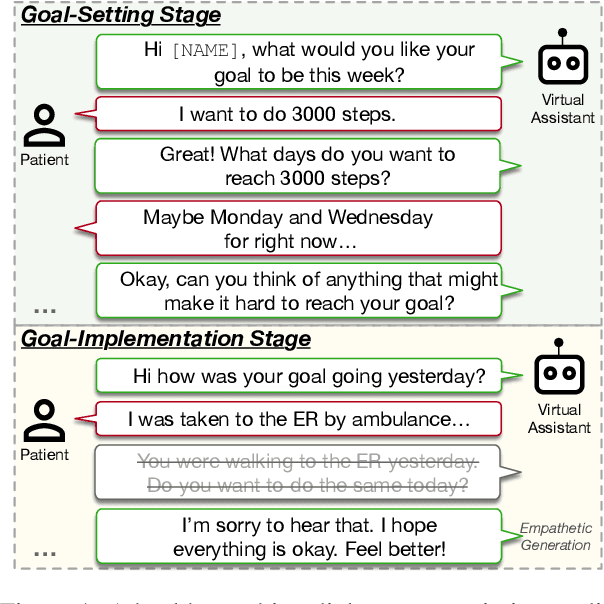
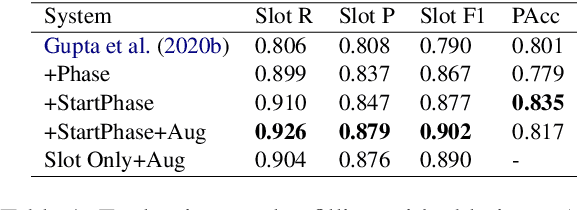
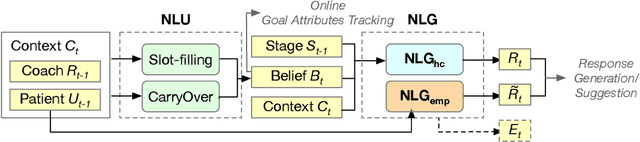

Health coaching helps patients identify and accomplish lifestyle-related goals, effectively improving the control of chronic diseases and mitigating mental health conditions. However, health coaching is cost-prohibitive due to its highly personalized and labor-intensive nature. In this paper, we propose to build a dialogue system that converses with the patients, helps them create and accomplish specific goals, and can address their emotions with empathy. However, building such a system is challenging since real-world health coaching datasets are limited and empathy is subtle. Thus, we propose a modularized health coaching dialogue system with simplified NLU and NLG frameworks combined with mechanism-conditioned empathetic response generation. Through automatic and human evaluation, we show that our system generates more empathetic, fluent, and coherent responses and outperforms the state-of-the-art in NLU tasks while requiring less annotation. We view our approach as a key step towards building automated and more accessible health coaching systems.
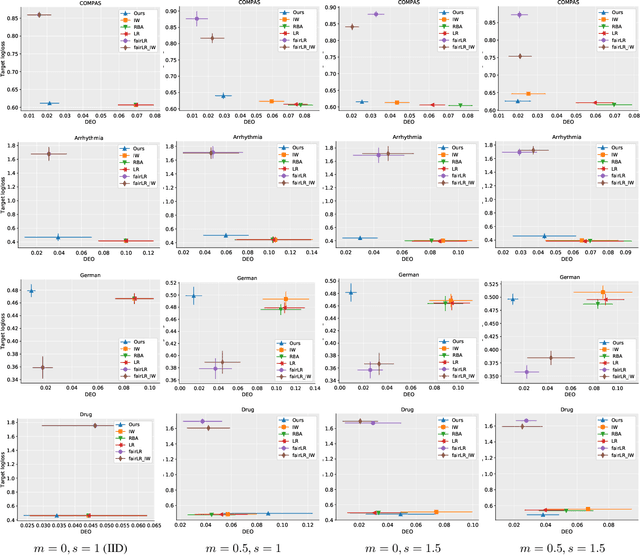
Superhuman Fairness
Jan 31, 2023The fairness of machine learning-based decisions has become an increasingly important focus in the design of supervised machine learning methods. Most fairness approaches optimize a specified trade-off between performance measure(s) (e.g., accuracy, log loss, or AUC) and fairness metric(s) (e.g., demographic parity, equalized odds). This begs the question: are the right performance-fairness trade-offs being specified? We instead re-cast fair machine learning as an imitation learning task by introducing superhuman fairness, which seeks to simultaneously outperform human decisions on multiple predictive performance and fairness measures. We demonstrate the benefits of this approach given suboptimal decisions.
Fairness for Robust Learning to Rank
Dec 12, 2021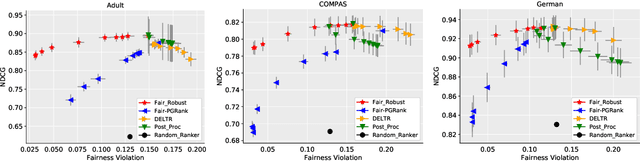

While conventional ranking systems focus solely on maximizing the utility of the ranked items to users, fairness-aware ranking systems additionally try to balance the exposure for different protected attributes such as gender or race. To achieve this type of group fairness for ranking, we derive a new ranking system based on the first principles of distributional robustness. We formulate a minimax game between a player choosing a distribution over rankings to maximize utility while satisfying fairness constraints against an adversary seeking to minimize utility while matching statistics of the training data. We show that our approach provides better utility for highly fair rankings than existing baseline methods.
Feedback in Imitation Learning: The Three Regimes of Covariate Shift
Feb 11, 2021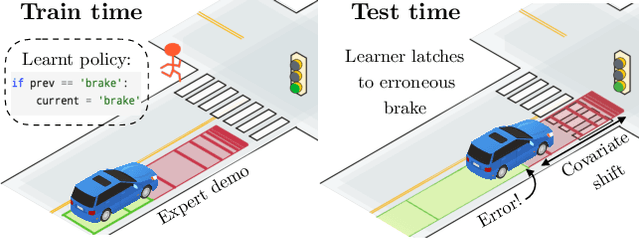
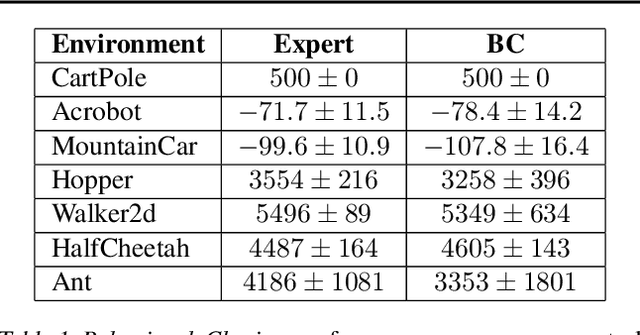
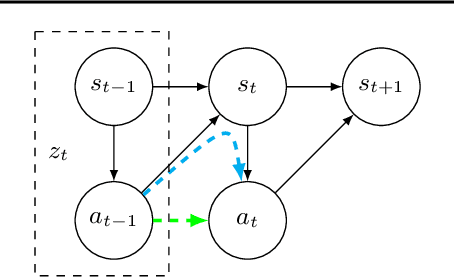

Imitation learning practitioners have often noted that conditioning policies on previous actions leads to a dramatic divergence between "held out" error and performance of the learner in situ. Interactive approaches can provably address this divergence but require repeated querying of a demonstrator. Recent work identifies this divergence as stemming from a "causal confound" in predicting the current action, and seek to ablate causal aspects of current state using tools from causal inference. In this work, we argue instead that this divergence is simply another manifestation of covariate shift, exacerbated particularly by settings of feedback between decisions and input features. The learner often comes to rely on features that are strongly predictive of decisions, but are subject to strong covariate shift. Our work demonstrates a broad class of problems where this shift can be mitigated, both theoretically and practically, by taking advantage of a simulator but without any further querying of expert demonstration. We analyze existing benchmarks used to test imitation learning approaches and find that these benchmarks are realizable and simple and thus insufficient for capturing the harder regimes of error compounding seen in real-world decision making problems. We find, in a surprising contrast with previous literature, but consistent with our theory, that naive behavioral cloning provides excellent results. We detail the need for new standardized benchmarks that capture the phenomena seen in robotics problems.
Robust Fairness under Covariate Shift
Oct 17, 2020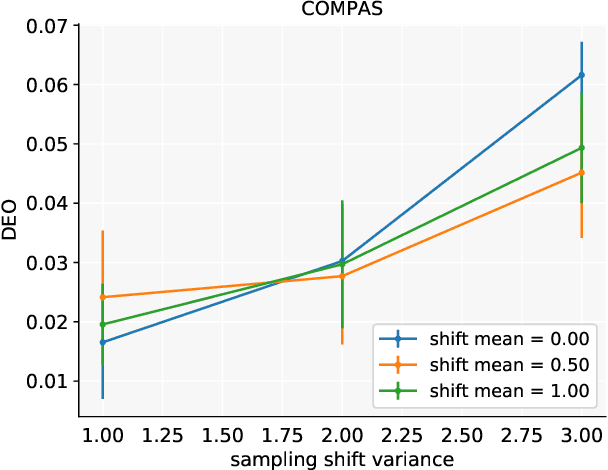

Making predictions that are fair with regard to protected group membership (race, gender, age, etc.) has become an important requirement for classification algorithms. Existing techniques derive a fair model from sampled labeled data relying on the assumption that training and testing data are identically and independently drawn (iid) from the same distribution.In practice, distribution shift can and does occur between training and testing datasets as the characteristics of individuals interacting with the machine learning system -- and which individuals interact with the system -- change. We investigate fairness under covariate shift, a relaxation of the iid assumption in which the inputs or covariates change while the conditional label distribution remains the same. We seek fair decisions under these assumptions on target data with unknown labels.We propose an approach that obtains the predictor that is robust to the worst-case in terms of target performance while satisfying target fairness requirements and matching statistical properties of the source data. We demonstrate the benefits of our approach on benchmark prediction tasks.
Fair Logistic Regression: An Adversarial Perspective
Mar 19, 2019
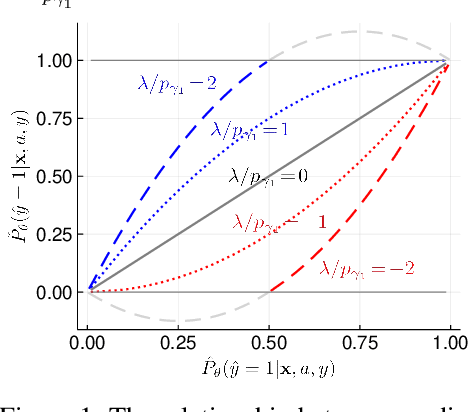
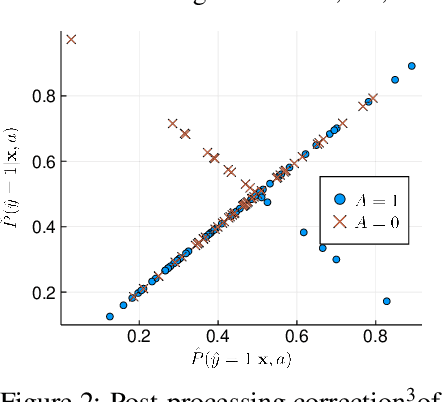
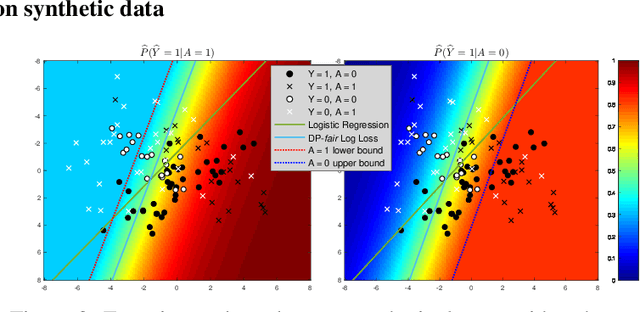
Fair prediction methods have primarily been built around existing classification techniques using pre-processing methods, post-hoc adjustments, reduction-based constructions, or deep learning procedures. We investigate a new approach to fair data-driven decision making by designing predictors with fairness requirements integrated into their core formulations. We augment a game-theoretic construction of the logistic regression model with fairness constraints, producing a novel prediction model that robustly and fairly minimizes the logarithmic loss. We demonstrate the advantages of our approach on a range of benchmark datasets for fairness.