 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman Fairness
Jan 31, 2023The fairness of machine learning-based decisions has become an increasingly important focus in the design of supervised machine learning methods. Most fairness approaches optimize a specified trade-off between performance measure(s) (e.g., accuracy, log loss, or AUC) and fairness metric(s) (e.g., demographic parity, equalized odds). This begs the question: are the right performance-fairness trade-offs being specified? We instead re-cast fair machine learning as an imitation learning task by introducing superhuman fairness, which seeks to simultaneously outperform human decisions on multiple predictive performance and fairness measures. We demonstrate the benefits of this approach given suboptimal decisions.
Fairness for Robust Learning to Rank
Dec 12, 2021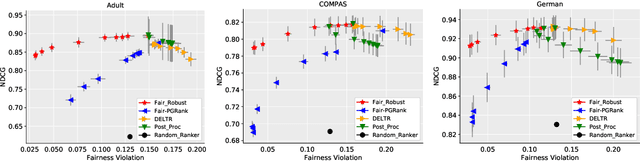

While conventional ranking systems focus solely on maximizing the utility of the ranked items to users, fairness-aware ranking systems additionally try to balance the exposure for different protected attributes such as gender or race. To achieve this type of group fairness for ranking, we derive a new ranking system based on the first principles of distributional robustness. We formulate a minimax game between a player choosing a distribution over rankings to maximize utility while satisfying fairness constraints against an adversary seeking to minimize utility while matching statistics of the training data. We show that our approach provides better utility for highly fair rankings than existing baseline methods.
ParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
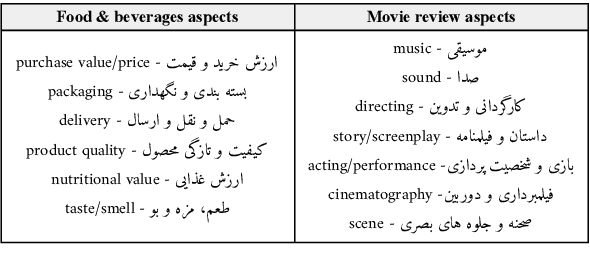
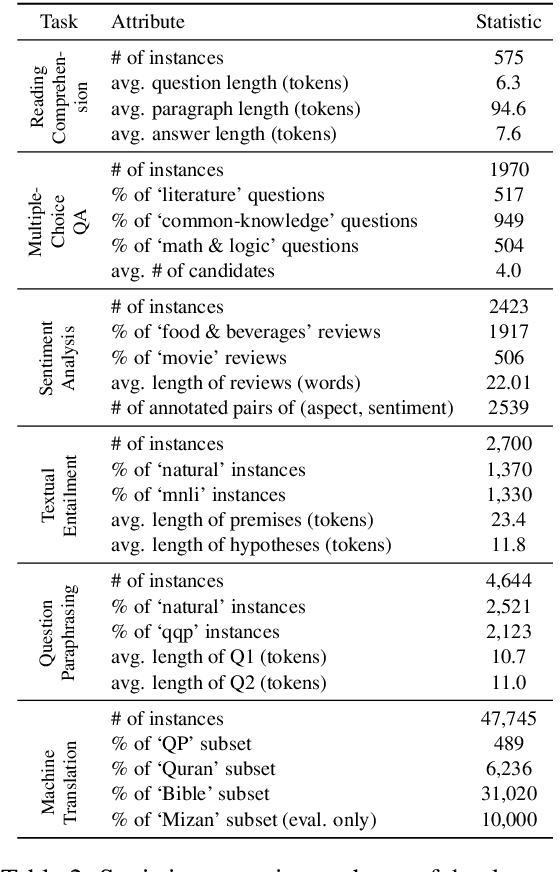
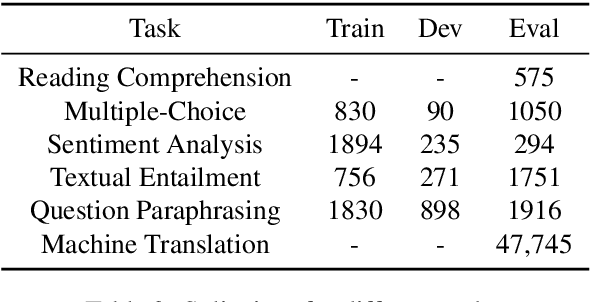
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
Robust Fairness under Covariate Shift
Oct 17, 2020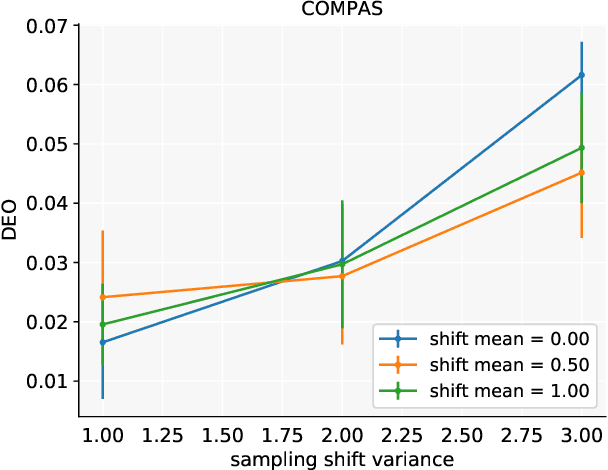

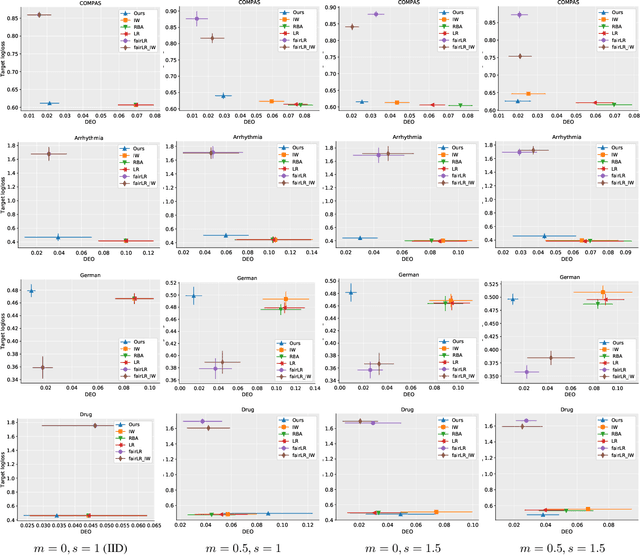
Making predictions that are fair with regard to protected group membership (race, gender, age, etc.) has become an important requirement for classification algorithms. Existing techniques derive a fair model from sampled labeled data relying on the assumption that training and testing data are identically and independently drawn (iid) from the same distribution.In practice, distribution shift can and does occur between training and testing datasets as the characteristics of individuals interacting with the machine learning system -- and which individuals interact with the system -- change. We investigate fairness under covariate shift, a relaxation of the iid assumption in which the inputs or covariates change while the conditional label distribution remains the same. We seek fair decisions under these assumptions on target data with unknown labels.We propose an approach that obtains the predictor that is robust to the worst-case in terms of target performance while satisfying target fairness requirements and matching statistical properties of the source data. We demonstrate the benefits of our approach on benchmark prediction tasks.
Fair Logistic Regression: An Adversarial Perspective
Mar 19, 2019
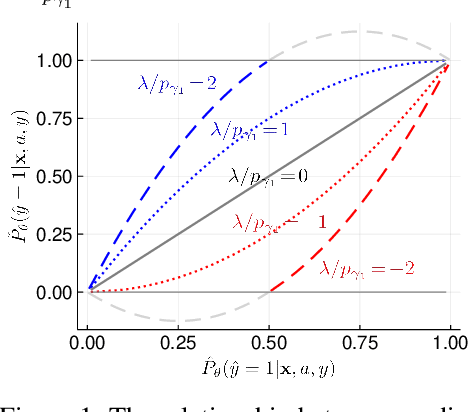
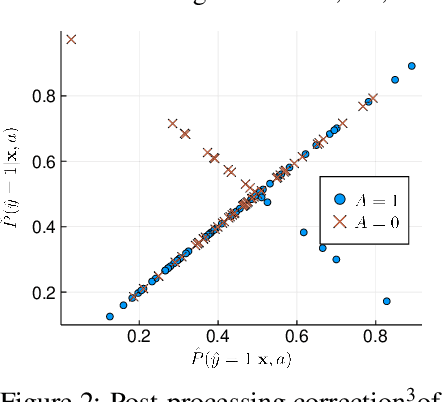
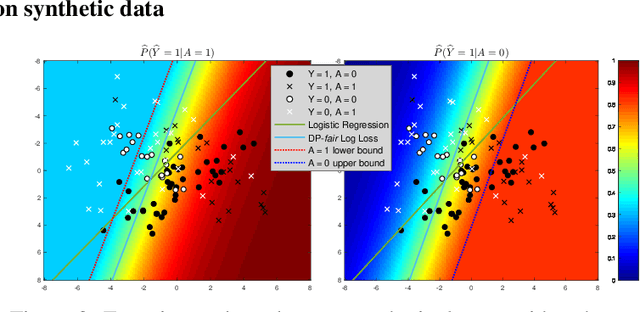
Fair prediction methods have primarily been built around existing classification techniques using pre-processing methods, post-hoc adjustments, reduction-based constructions, or deep learning procedures. We investigate a new approach to fair data-driven decision making by designing predictors with fairness requirements integrated into their core formulations. We augment a game-theoretic construction of the logistic regression model with fairness constraints, producing a novel prediction model that robustly and fairly minimizes the logarithmic loss. We demonstrate the advantages of our approach on a range of benchmark datasets for fairness.