 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClamNet: Using contrastive learning with variable depth Unets for medical image segmentation
Jun 10, 2022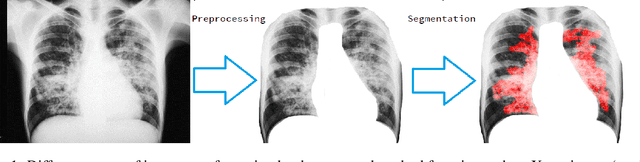
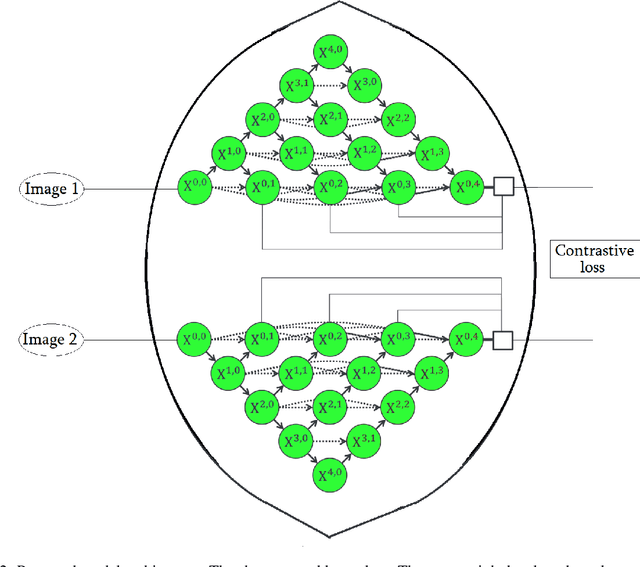
Unets have become the standard method for semantic segmentation of medical images, along with fully convolutional networks (FCN). Unet++ was introduced as a variant of Unet, in order to solve some of the problems facing Unet and FCNs. Unet++ provided networks with an ensemble of variable depth Unets, hence eliminating the need for professionals estimating the best suitable depth for a task. While Unet and all its variants, including Unet++ aimed at providing networks that were able to train well without requiring large quantities of annotated data, none of them attempted to eliminate the need for pixel-wise annotated data altogether. Obtaining such data for each disease to be diagnosed comes at a high cost. Hence such data is scarce. In this paper we use contrastive learning to train Unet++ for semantic segmentation of medical images using medical images from various sources including magnetic resonance imaging (MRI) and computed tomography (CT), without the need for pixel-wise annotations. Here we describe the architecture of the proposed model and the training method used. This is still a work in progress and so we abstain from including results in this paper. The results and the trained model would be made available upon publication or in subsequent versions of this paper on arxiv.
Using Machine Learning to Predict Air Quality Index in New Delhi
Dec 10, 2021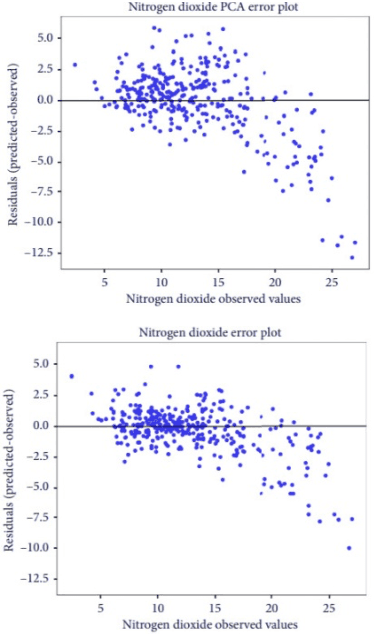
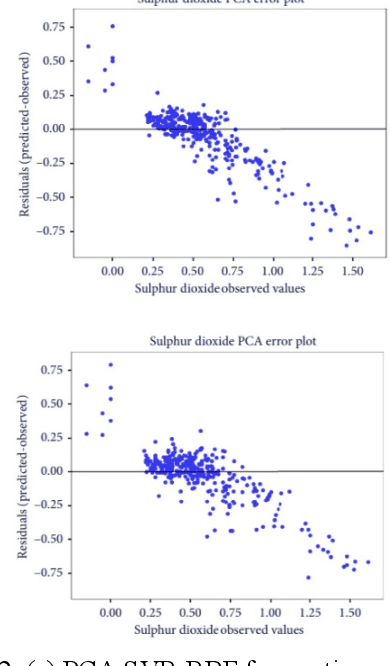
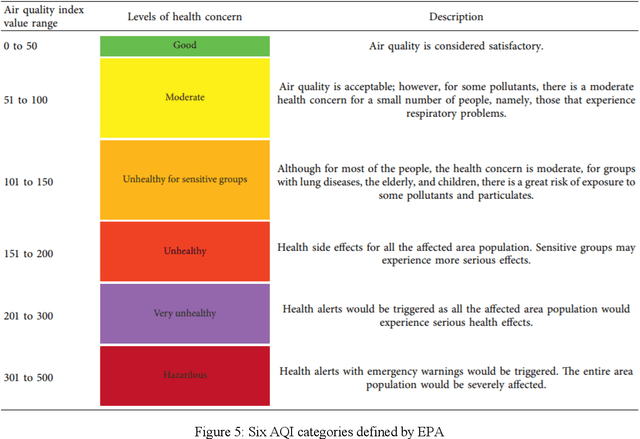
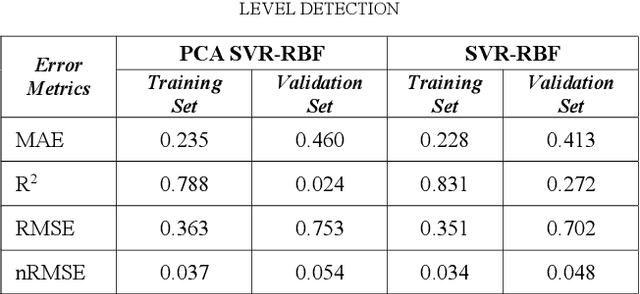
Air quality has a significant impact on human health. Degradation in air quality leads to a wide range of health issues, especially in children. The ability to predict air quality enables the government and other concerned organizations to take necessary steps to shield the most vulnerable, from being exposed to the air with hazardous quality. Traditional approaches to this task have very limited success because of a lack of access of such methods to sufficient longitudinal data. In this paper, we use a Support Vector Regression (SVR) model to forecast the levels of various pollutants and the air quality index, using archive pollution data made publicly available by Central Pollution Control Board and the US Embassy in New Delhi. Among the tested methods, a Radial Basis Function (RBF) kernel produced the best results with SVR. According to our experiments, using the whole range of available variables produced better results than using features selected by principal component analysis. The model predicts levels of various pollutants, like, sulfur dioxide, carbon monoxide, nitrogen dioxide, particulate matter 2.5, and ground-level ozone, as well as the Air Quality Index (AQI), at an accuracy of 93.4 percent.
Pose Recognition in the Wild: Animal pose estimation using Agglomerative Clustering and Contrastive Learning
Nov 16, 2021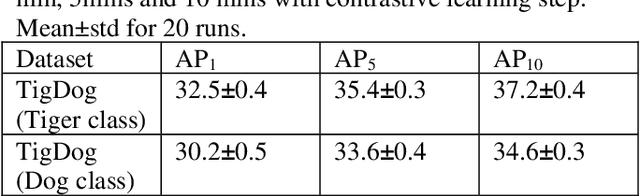
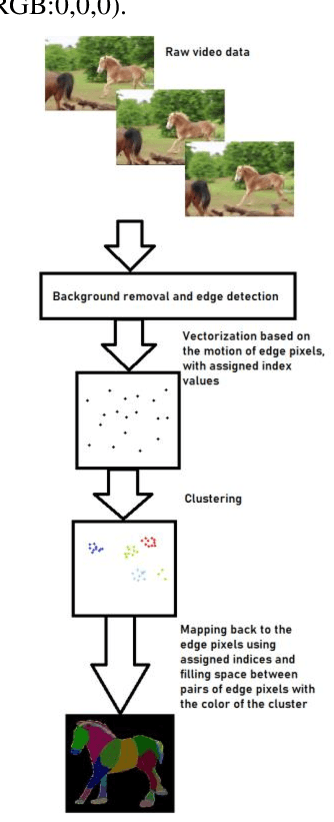

Animal pose estimation has recently come into the limelight due to its application in biology, zoology, and aquaculture. Deep learning methods have effectively been applied to human pose estimation. However, the major bottleneck to the application of these methods to animal pose estimation is the unavailability of sufficient quantities of labeled data. Though there are ample quantities of unlabelled data publicly available, it is economically impractical to label large quantities of data for each animal. In addition, due to the wide variety of body shapes in the animal kingdom, the transfer of knowledge across domains is ineffective. Given the fact that the human brain is able to recognize animal pose without requiring large amounts of labeled data, it is only reasonable that we exploit unsupervised learning to tackle the problem of animal pose recognition from the available, unlabelled data. In this paper, we introduce a novel architecture that is able to recognize the pose of multiple animals fromunlabelled data. We do this by (1) removing background information from each image and employing an edge detection algorithm on the body of the animal, (2) Tracking motion of the edge pixels and performing agglomerative clustering to segment body parts, (3) employing contrastive learning to discourage grouping of distant body parts together. Hence we are able to distinguish between body parts of the animal, based on their visual behavior, instead of the underlying anatomy. Thus, we are able to achieve a more effective classification of the data than their human-labeled counterparts. We test our model on the TigDog and WLD (WildLife Documentary) datasets, where we outperform state-of-the-art approaches by a significant margin. We also study the performance of our model on other public data to demonstrate the generalization ability of our model.
Animal inspired Application of a Variant of Mel Spectrogram for Seismic Data Processing
Sep 22, 2021

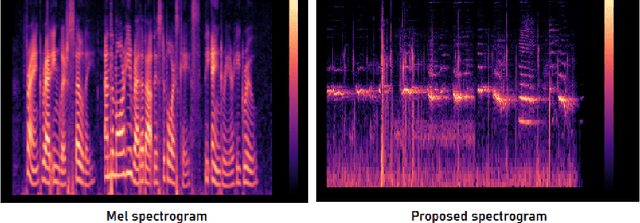
Predicting disaster events from seismic data is of paramount importance and can save thousands of lives, especially in earthquake-prone areas and habitations around volcanic craters. The drastic rise in the number of seismic monitoring stations in recent years has allowed the collection of a huge quantity of data, outpacing the capacity of seismologists. Due to the complex nature of the seismological data, it is often difficult for seismologists to detect subtle patterns with major implications. Machine learning algorithms have been demonstrated to be effective in classification and prediction tasks for seismic data. It has been widely known that some animals can sense disasters like earthquakes from seismic signals well before the disaster strikes. Mel spectrogram has been widely used for speech recognition as it scales the actual frequencies according to human hearing. In this paper, we propose a variant of the Mel spectrogram to scale the raw frequencies of seismic data to the hearing of such animals that can sense disasters from seismic signals. We are using a Computer vision algorithm along with clustering that allows for the classification of unlabelled seismic data.
Atrial Fibrillation: A Medical and Technological Review
Sep 18, 2021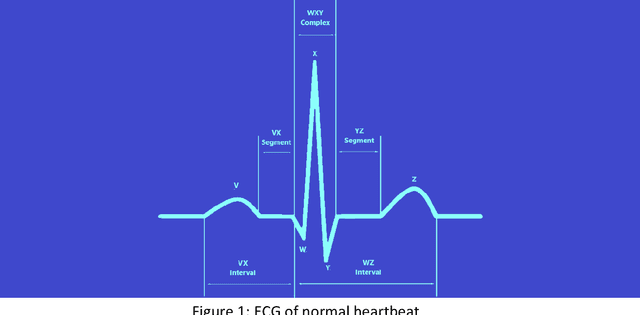
Atrial Fibrillation (AF) is the most common type of arrhythmia (Greek a-, loss + rhythmos, rhythm = loss of rhythm) leading to hospitalization in the United States. Though sometimes AF is asymptomatic, it increases the risk of stroke and heart failure in patients, in addition to lowering the health-related quality of life (HRQOL). AF-related care costs the healthcare system between $6.0 to $26 billion each year. Early detection of AF and clinical attention can help improve symptoms and HRQOL of the patient, as well as bring down the cost of care. However, the prevalent paradigm of AF detection depends on electrocardiogram (ECG) recorded at a single point in time and does not shed light on the relation of the symptoms with heart rhythm or AF. In the recent decade, due to the democratization of health monitors and the advent of high-performing computers, Machine Learning algorithms have been proven effective in identifying AF, from the ECG of patients. This paper provides an overview of the symptoms of AF, its diagnosis, and future prospects for research in the field.