 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClamNet: Using contrastive learning with variable depth Unets for medical image segmentation
Paper and Code
Jun 10, 2022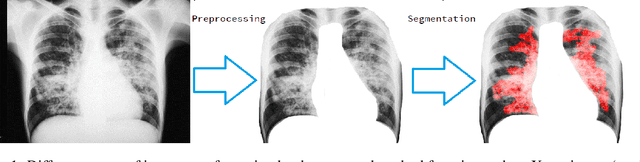
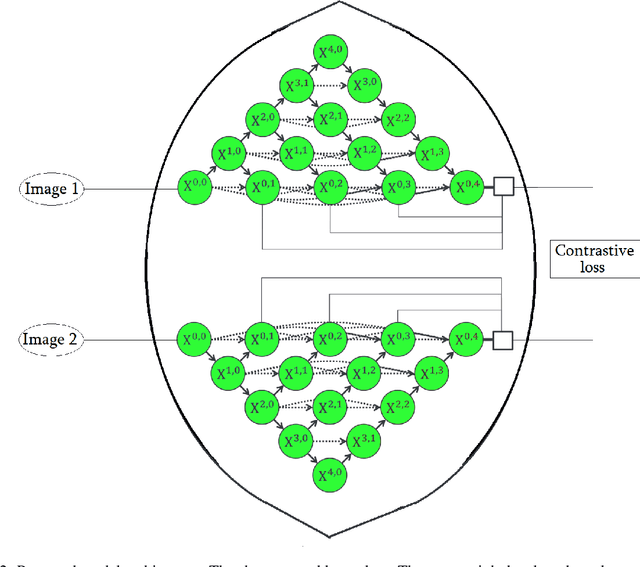
Unets have become the standard method for semantic segmentation of medical images, along with fully convolutional networks (FCN). Unet++ was introduced as a variant of Unet, in order to solve some of the problems facing Unet and FCNs. Unet++ provided networks with an ensemble of variable depth Unets, hence eliminating the need for professionals estimating the best suitable depth for a task. While Unet and all its variants, including Unet++ aimed at providing networks that were able to train well without requiring large quantities of annotated data, none of them attempted to eliminate the need for pixel-wise annotated data altogether. Obtaining such data for each disease to be diagnosed comes at a high cost. Hence such data is scarce. In this paper we use contrastive learning to train Unet++ for semantic segmentation of medical images using medical images from various sources including magnetic resonance imaging (MRI) and computed tomography (CT), without the need for pixel-wise annotations. Here we describe the architecture of the proposed model and the training method used. This is still a work in progress and so we abstain from including results in this paper. The results and the trained model would be made available upon publication or in subsequent versions of this paper on arxiv.