 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePithTrain: A Compact and Agent-Native MoE Training System
May 29, 2026Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have built optimized MoE training stacks over years of engineering effort. Yet evolving these stacks for new architectures and system optimizations remains expensive. With the rise of AI coding agents, they could automate parts of training-framework development and accelerate this evolution. But applying them to these existing frameworks carries hidden costs, invisible to today's throughput-only evaluations. We name this missing dimension agent-task efficiency (ATE): the cost of using coding agents to understand, operate, and extend a framework. Grounded in four agent-native design principles, we build PithTrain, a compact, agent-native MoE training framework. We further introduce ATE-Bench, covering real-world training-framework tasks. Our evaluation shows PithTrain matches the throughput of production frameworks, and on ATE-Bench, PithTrain enables higher agent-task efficiency, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
Bi-Manual Joint Camera Calibration and Scene Representation
May 30, 2025



Robot manipulation, especially bimanual manipulation, often requires setting up multiple cameras on multiple robot manipulators. Before robot manipulators can generate motion or even build representations of their environments, the cameras rigidly mounted to the robot need to be calibrated. Camera calibration is a cumbersome process involving collecting a set of images, with each capturing a pre-determined marker. In this work, we introduce the Bi-Manual Joint Calibration and Representation Framework (Bi-JCR). Bi-JCR enables multiple robot manipulators, each with cameras mounted, to circumvent taking images of calibration markers. By leveraging 3D foundation models for dense, marker-free multi-view correspondence, Bi-JCR jointly estimates: (i) the extrinsic transformation from each camera to its end-effector, (ii) the inter-arm relative poses between manipulators, and (iii) a unified, scale-consistent 3D representation of the shared workspace, all from the same captured RGB image sets. The representation, jointly constructed from images captured by cameras on both manipulators, lives in a common coordinate frame and supports collision checking and semantic segmentation to facilitate downstream bimanual coordination tasks. We empirically evaluate the robustness of Bi-JCR on a variety of tabletop environments, and demonstrate its applicability on a variety of downstream tasks.
GraphSeg: Segmented 3D Representations via Graph Edge Addition and Contraction
Apr 04, 2025Robots operating in unstructured environments often require accurate and consistent object-level representations. This typically requires segmenting individual objects from the robot's surroundings. While recent large models such as Segment Anything (SAM) offer strong performance in 2D image segmentation. These advances do not translate directly to performance in the physical 3D world, where they often over-segment objects and fail to produce consistent mask correspondences across views. In this paper, we present GraphSeg, a framework for generating consistent 3D object segmentations from a sparse set of 2D images of the environment without any depth information. GraphSeg adds edges to graphs and constructs dual correspondence graphs: one from 2D pixel-level similarities and one from inferred 3D structure. We formulate segmentation as a problem of edge addition, then subsequent graph contraction, which merges multiple 2D masks into unified object-level segmentations. We can then leverage \emph{3D foundation models} to produce segmented 3D representations. GraphSeg achieves robust segmentation with significantly fewer images and greater accuracy than prior methods. We demonstrate state-of-the-art performance on tabletop scenes and show that GraphSeg enables improved performance on downstream robotic manipulation tasks. Code available at https://github.com/tomtang502/graphseg.git.
3D Foundation Models Enable Simultaneous Geometry and Pose Estimation of Grasped Objects
Jul 14, 2024


Humans have the remarkable ability to use held objects as tools to interact with their environment. For this to occur, humans internally estimate how hand movements affect the object's movement. We wish to endow robots with this capability. We contribute methodology to jointly estimate the geometry and pose of objects grasped by a robot, from RGB images captured by an external camera. Notably, our method transforms the estimated geometry into the robot's coordinate frame, while not requiring the extrinsic parameters of the external camera to be calibrated. Our approach leverages 3D foundation models, large models pre-trained on huge datasets for 3D vision tasks, to produce initial estimates of the in-hand object. These initial estimations do not have physically correct scales and are in the camera's frame. Then, we formulate, and efficiently solve, a coordinate-alignment problem to recover accurate scales, along with a transformation of the objects to the coordinate frame of the robot. Forward kinematics mappings can subsequently be defined from the manipulator's joint angles to specified points on the object. These mappings enable the estimation of points on the held object at arbitrary configurations, enabling robot motion to be designed with respect to coordinates on the grasped objects. We empirically evaluate our approach on a robot manipulator holding a diverse set of real-world objects.
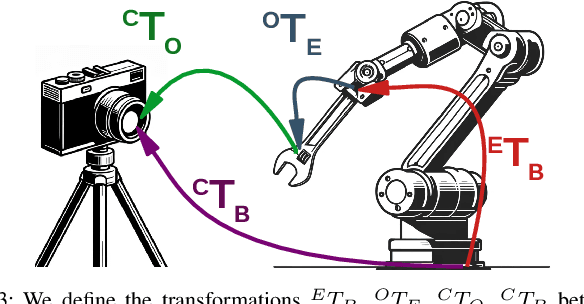
Unifying Scene Representation and Hand-Eye Calibration with 3D Foundation Models
Apr 17, 2024Representing the environment is a central challenge in robotics, and is essential for effective decision-making. Traditionally, before capturing images with a manipulator-mounted camera, users need to calibrate the camera using a specific external marker, such as a checkerboard or AprilTag. However, recent advances in computer vision have led to the development of \emph{3D foundation models}. These are large, pre-trained neural networks that can establish fast and accurate multi-view correspondences with very few images, even in the absence of rich visual features. This paper advocates for the integration of 3D foundation models into scene representation approaches for robotic systems equipped with manipulator-mounted RGB cameras. Specifically, we propose the Joint Calibration and Representation (JCR) method. JCR uses RGB images, captured by a manipulator-mounted camera, to simultaneously construct an environmental representation and calibrate the camera relative to the robot's end-effector, in the absence of specific calibration markers. The resulting 3D environment representation is aligned with the robot's coordinate frame and maintains physically accurate scales. We demonstrate that JCR can build effective scene representations using a low-cost RGB camera attached to a manipulator, without prior calibration.