 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Collaborative Bandits with Thompson Sampling for Improved Outreach in Maternal Health Program
Oct 28, 2024



Mobile health (mHealth) programs face a critical challenge in optimizing the timing of automated health information calls to beneficiaries. This challenge has been formulated as a collaborative multi-armed bandit problem, requiring online learning of a low-rank reward matrix. Existing solutions often rely on heuristic combinations of offline matrix completion and exploration strategies. In this work, we propose a principled Bayesian approach using Thompson Sampling for this collaborative bandit problem. Our method leverages prior information through efficient Gibbs sampling for posterior inference over the low-rank matrix factors, enabling faster convergence. We demonstrate significant improvements over state-of-the-art baselines on a real-world dataset from the world's largest maternal mHealth program. Our approach achieves a $16\%$ reduction in the number of calls compared to existing methods and a $47$\% reduction compared to the deployed random policy. This efficiency gain translates to a potential increase in program capacity by $0.5-1.4$ million beneficiaries, granting them access to vital ante-natal and post-natal care information. Furthermore, we observe a $7\%$ and $29\%$ improvement in beneficiary retention (an extremely hard metric to impact) compared to state-of-the-art and deployed baselines, respectively. Synthetic simulations further demonstrate the superiority of our approach, particularly in low-data regimes and in effectively utilizing prior information. We also provide a theoretical analysis of our algorithm in a special setting using Eluder dimension.
Mixture of Nested Experts: Adaptive Processing of Visual Tokens
Jul 29, 2024

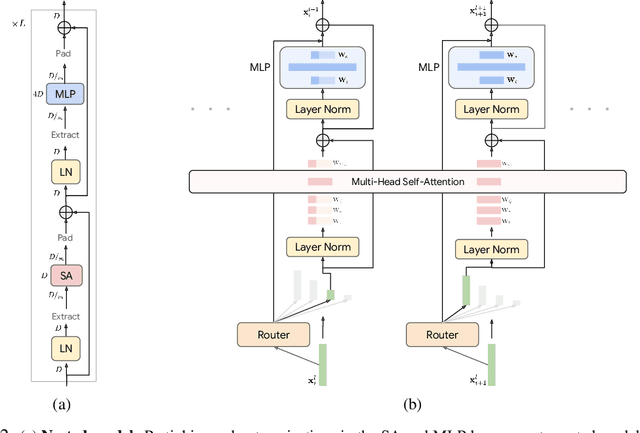
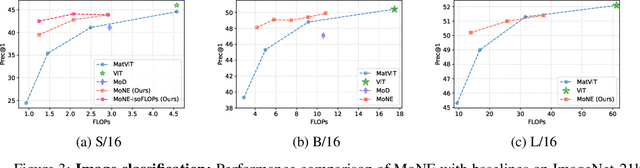
The visual medium (images and videos) naturally contains a large amount of information redundancy, thereby providing a great opportunity for leveraging efficiency in processing. While Vision Transformer (ViT) based models scale effectively to large data regimes, they fail to capitalize on this inherent redundancy, leading to higher computational costs. Mixture of Experts (MoE) networks demonstrate scalability while maintaining same inference-time costs, but they come with a larger parameter footprint. We present Mixture of Nested Experts (MoNE), which utilizes a nested structure for experts, wherein individual experts fall on an increasing compute-accuracy curve. Given a compute budget, MoNE learns to dynamically choose tokens in a priority order, and thus redundant tokens are processed through cheaper nested experts. Using this framework, we achieve equivalent performance as the baseline models, while reducing inference time compute by over two-fold. We validate our approach on standard image and video datasets - ImageNet-21K, Kinetics400, and Something-Something-v2. We further highlight MoNE$'$s adaptability by showcasing its ability to maintain strong performance across different inference-time compute budgets on videos, using only a single trained model.
LookupViT: Compressing visual information to a limited number of tokens
Jul 17, 2024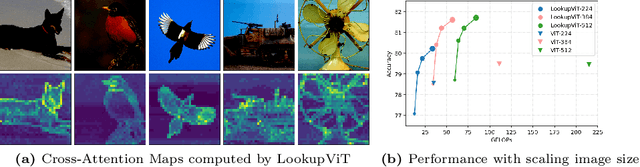
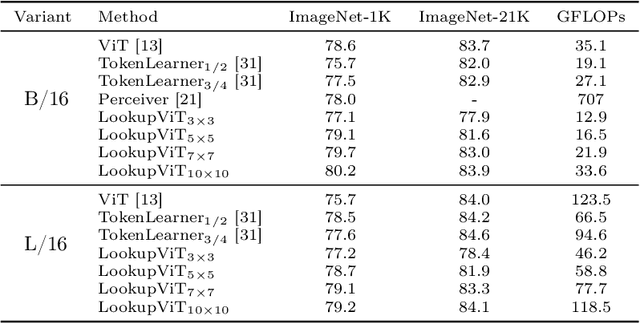
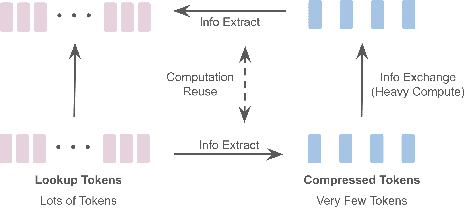
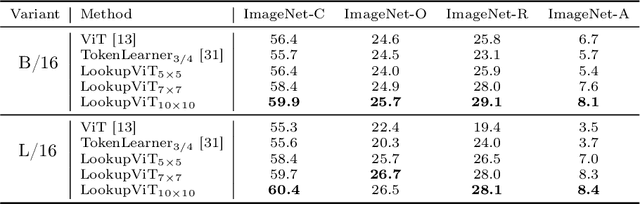
Vision Transformers (ViT) have emerged as the de-facto choice for numerous industry grade vision solutions. But their inference cost can be prohibitive for many settings, as they compute self-attention in each layer which suffers from quadratic computational complexity in the number of tokens. On the other hand, spatial information in images and spatio-temporal information in videos is usually sparse and redundant. In this work, we introduce LookupViT, that aims to exploit this information sparsity to reduce ViT inference cost. LookupViT provides a novel general purpose vision transformer block that operates by compressing information from higher resolution tokens to a fixed number of tokens. These few compressed tokens undergo meticulous processing, while the higher-resolution tokens are passed through computationally cheaper layers. Information sharing between these two token sets is enabled through a bidirectional cross-attention mechanism. The approach offers multiple advantages - (a) easy to implement on standard ML accelerators (GPUs/TPUs) via standard high-level operators, (b) applicable to standard ViT and its variants, thus generalizes to various tasks, (c) can handle different tokenization and attention approaches. LookupViT also offers flexibility for the compressed tokens, enabling performance-computation trade-offs in a single trained model. We show LookupViT's effectiveness on multiple domains - (a) for image-classification (ImageNet-1K and ImageNet-21K), (b) video classification (Kinetics400 and Something-Something V2), (c) image captioning (COCO-Captions) with a frozen encoder. LookupViT provides $2\times$ reduction in FLOPs while upholding or improving accuracy across these domains. In addition, LookupViT also demonstrates out-of-the-box robustness and generalization on image classification (ImageNet-C,R,A,O), improving by up to $4\%$ over ViT.