 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Fine-Grained Network Data using Autoencoder Architectures with Domain Knowledge Penalties
Apr 15, 2025



The ability to reconstruct fine-grained network session data, including individual packets, from coarse-grained feature vectors is crucial for improving network security models. However, the large-scale collection and storage of raw network traffic pose significant challenges, particularly for capturing rare cyberattack samples. These challenges hinder the ability to retain comprehensive datasets for model training and future threat detection. To address this, we propose a machine learning approach guided by formal methods to encode and reconstruct network data. Our method employs autoencoder models with domain-informed penalties to impute PCAP session headers from structured feature representations. Experimental results demonstrate that incorporating domain knowledge through constraint-based loss terms significantly improves reconstruction accuracy, particularly for categorical features with session-level encodings. By enabling efficient reconstruction of detailed network sessions, our approach facilitates data-efficient model training while preserving privacy and storage efficiency.
Learning and Planning in Feature Deception Games
May 13, 2019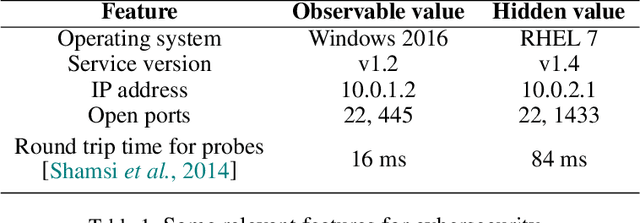
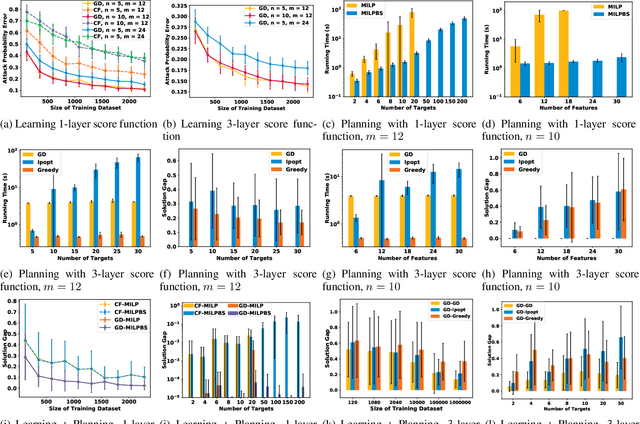
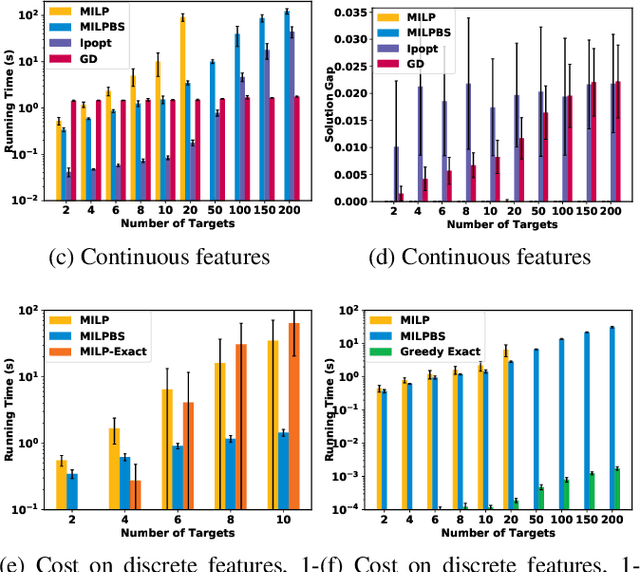

Today's high-stakes adversarial interactions feature attackers who constantly breach the ever-improving security measures. Deception mitigates the defender's loss by misleading the attacker to make suboptimal decisions. In order to formally reason about deception, we introduce the feature deception game (FDG), a domain-independent game-theoretic model and present a learning and planning framework. We make the following contributions. (1) We show that we can uniformly learn the adversary's preferences using data from a modest number of deception strategies. (2) We propose an approximation algorithm for finding the optimal deception strategy and show that the problem is NP-hard. (3) We perform extensive experiments to empirically validate our methods and results.