 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Data-driven Optimization: AI for Social Good and Beyond
Paper and Code

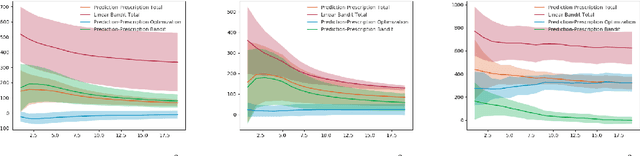
The use of machine learning (ML) systems in real-world applications entails more than just a prediction algorithm. AI for social good applications, and many real-world ML tasks in general, feature an iterative process which joins prediction, optimization, and data acquisition happen in a loop. We introduce bandit data-driven optimization, the first iterative prediction-prescription framework to formally analyze this practical routine. Bandit data-driven optimization combines the advantages of online bandit learning and offline predictive analytics in an integrated framework. It offers a flexible setup to reason about unmodeled policy objectives and unforeseen consequences. We propose PROOF, the first algorithm for this framework and show that it achieves no-regret. Using numerical simulations, we show that PROOF achieves superior performance over existing baseline.