 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdopting Trustworthy AI for Sleep Disorder Prediction: Deep Time Series Analysis with Temporal Attention Mechanism and Counterfactual Explanations
Dec 25, 2024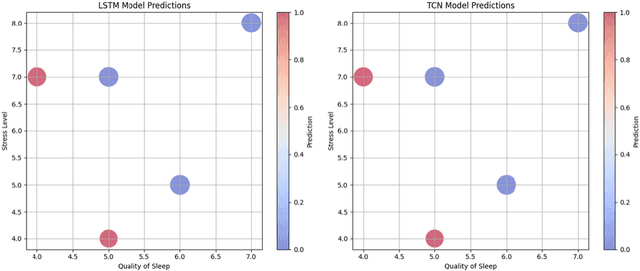
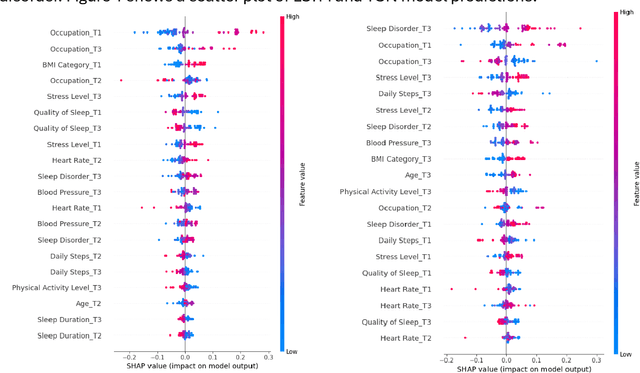

Sleep disorders have a major impact on both lifestyle and health. Effective sleep disorder prediction from lifestyle and physiological data can provide essential details for early intervention. This research utilizes three deep time series models and facilitates them with explainability approaches for sleep disorder prediction. Specifically, our approach adopts Temporal Convolutional Networks (TCN), Long Short-Term Memory (LSTM) for time series data analysis, and Temporal Fusion Transformer model (TFT). Meanwhile, the temporal attention mechanism and counterfactual explanation with SHapley Additive exPlanations (SHAP) approach are employed to ensure dependable, accurate, and interpretable predictions. Finally, using a large dataset of sleep health measures, our evaluation demonstrates the effect of our method in predicting sleep disorders.
MNIST-Fraction: Enhancing Math Education with AI-Driven Fraction Detection and Analysis
Dec 11, 2024Mathematics education, a crucial and basic field, significantly influences students' learning in related subjects and their future careers. Utilizing artificial intelligence to interpret and comprehend math problems in education is not yet fully explored. This is due to the scarcity of quality datasets and the intricacies of processing handwritten information. In this paper, we present a novel contribution to the field of mathematics education through the development of MNIST-Fraction, a dataset inspired by the renowned MNIST, specifically tailored for the recognition and understanding of handwritten math fractions. Our approach is the utilization of deep learning, specifically Convolutional Neural Networks (CNNs), for the recognition and understanding of handwritten math fractions to effectively detect and analyze fractions, along with their numerators and denominators. This capability is pivotal in calculating the value of fractions, a fundamental aspect of math learning. The MNIST-Fraction dataset is designed to closely mimic real-world scenarios, providing a reliable and relevant resource for AI-driven educational tools. Furthermore, we conduct a comprehensive comparison of our dataset with the original MNIST dataset using various classifiers, demonstrating the effectiveness and versatility of MNIST-Fraction in both detection and classification tasks. This comparative analysis not only validates the practical utility of our dataset but also offers insights into its potential applications in math education. To foster collaboration and further research within the computational and educational communities. Our work aims to bridge the gap in high-quality educational resources for math learning, offering a valuable tool for both educators and researchers in the field.
An adaptive network-based approach for advanced forecasting of cryptocurrency values
Jan 08, 2024This paper describes an architecture for predicting the price of cryptocurrencies for the next seven days using the Adaptive Network Based Fuzzy Inference System (ANFIS). Historical data of cryptocurrencies and indexes that are considered are Bitcoin (BTC), Ethereum (ETH), Bitcoin Dominance (BTC.D), and Ethereum Dominance (ETH.D) in a daily timeframe. The methods used to teach the data are hybrid and backpropagation algorithms, as well as grid partition, subtractive clustering, and Fuzzy C-means clustering (FCM) algorithms, which are used in data clustering. The architectural performance designed in this paper has been compared with different inputs and neural network models in terms of statistical evaluation criteria. Finally, the proposed method can predict the price of digital currencies in a short time.
* 11 pages
Using Singular Value Decomposition in a Convolutional Neural Network to Improve Brain Tumor Segmentation Accuracy
Jan 04, 2024A brain tumor consists of cells showing abnormal brain growth. The area of the brain tumor significantly affects choosing the type of treatment and following the course of the disease during the treatment. At the same time, pictures of Brain MRIs are accompanied by noise. Eliminating existing noises can significantly impact the better segmentation and diagnosis of brain tumors. In this work, we have tried using the analysis of eigenvalues. We have used the MSVD algorithm, reducing the image noise and then using the deep neural network to segment the tumor in the images. The proposed method's accuracy was increased by 2.4% compared to using the original images. With Using the MSVD method, convergence speed has also increased, showing the proposed method's effectiveness
Malware Detection in IOT Systems Using Machine Learning Techniques
Dec 29, 2023Malware detection in IoT environments necessitates robust methodologies. This study introduces a CNN-LSTM hybrid model for IoT malware identification and evaluates its performance against established methods. Leveraging K-fold cross-validation, the proposed approach achieved 95.5% accuracy, surpassing existing methods. The CNN algorithm enabled superior learning model construction, and the LSTM classifier exhibited heightened accuracy in classification. Comparative analysis against prevalent techniques demonstrated the efficacy of the proposed model, highlighting its potential for enhancing IoT security. The study advocates for future exploration of SVMs as alternatives, emphasizes the need for distributed detection strategies, and underscores the importance of predictive analyses for a more powerful IOT security. This research serves as a platform for developing more resilient security measures in IoT ecosystems.
evaluating bert and parsbert for analyzing persian advertisement data
May 03, 2023This paper discusses the impact of the Internet on modern trading and the importance of data generated from these transactions for organizations to improve their marketing efforts. The paper uses the example of Divar, an online marketplace for buying and selling products and services in Iran, and presents a competition to predict the percentage of a car sales ad that would be published on the Divar website. Since the dataset provides a rich source of Persian text data, the authors use the Hazm library, a Python library designed for processing Persian text, and two state-of-the-art language models, mBERT and ParsBERT, to analyze it. The paper's primary objective is to compare the performance of mBERT and ParsBERT on the Divar dataset. The authors provide some background on data mining, Persian language, and the two language models, examine the dataset's composition and statistical features, and provide details on their fine-tuning and training configurations for both approaches. They present the results of their analysis and highlight the strengths and weaknesses of the two language models when applied to Persian text data. The paper offers valuable insights into the challenges and opportunities of working with low-resource languages such as Persian and the potential of advanced language models like BERT for analyzing such data. The paper also explains the data mining process, including steps such as data cleaning and normalization techniques. Finally, the paper discusses the types of machine learning problems, such as supervised, unsupervised, and reinforcement learning, and the pattern evaluation techniques, such as confusion matrix. Overall, the paper provides an informative overview of the use of language models and data mining techniques for analyzing text data in low-resource languages, using the example of the Divar dataset.
Multimodal Learning for Multi-Omics: A Survey
Dec 19, 2022With advanced imaging, sequencing, and profiling technologies, multiple omics data become increasingly available and hold promises for many healthcare applications such as cancer diagnosis and treatment. Multimodal learning for integrative multi-omics analysis can help researchers and practitioners gain deep insights into human diseases and improve clinical decisions. However, several challenges are hindering the development in this area, including the availability of easily accessible open-source tools. This survey aims to provide an up-to-date overview of the data challenges, fusion approaches, datasets, and software tools from several new perspectives. We identify and investigate various omics data challenges that can help us understand the field better. We categorize fusion approaches comprehensively to cover existing methods in this area. We collect existing open-source tools to facilitate their broader utilization and development. We explore a broad range of omics data modalities and a list of accessible datasets. Finally, we summarize future directions that can potentially address existing gaps and answer the pressing need to advance multimodal learning for multi-omics data analysis.