 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Memory-Efficient Deep Learning Training Framework via Error-Bounded Lossy Compression
Paper and Code
Nov 18, 2020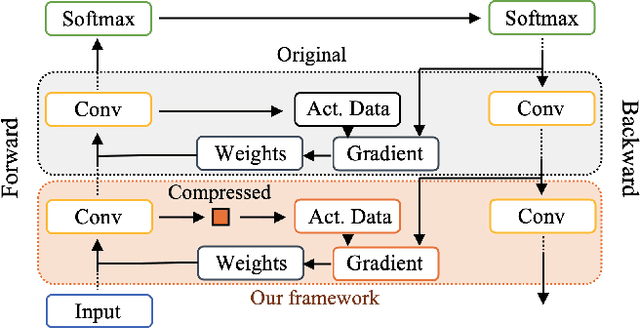
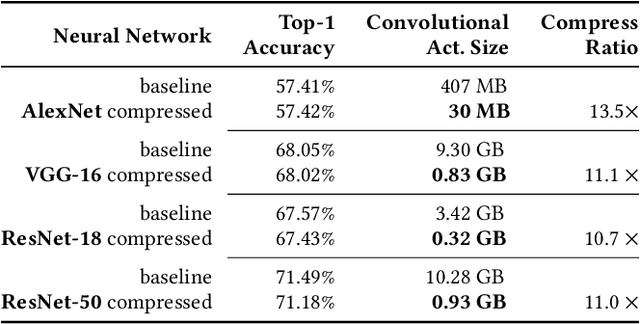
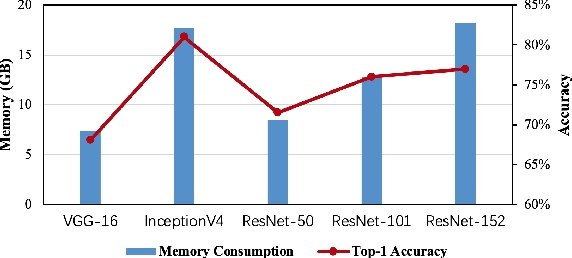
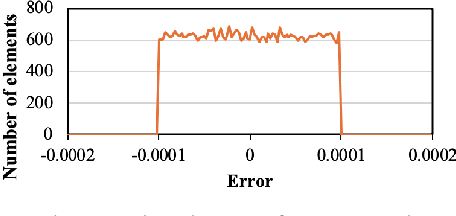
Deep neural networks (DNNs) are becoming increasingly deeper, wider, and non-linear due to the growing demands on prediction accuracy and analysis quality. When training a DNN model, the intermediate activation data must be saved in the memory during forward propagation and then restored for backward propagation. However, state-of-the-art accelerators such as GPUs are only equipped with very limited memory capacities due to hardware design constraints, which significantly limits the maximum batch size and hence performance speedup when training large-scale DNNs. In this paper, we propose a novel memory-driven high performance DNN training framework that leverages error-bounded lossy compression to significantly reduce the memory requirement for training in order to allow training larger networks. Different from the state-of-the-art solutions that adopt image-based lossy compressors such as JPEG to compress the activation data, our framework purposely designs error-bounded lossy compression with a strict error-controlling mechanism. Specifically, we provide theoretical analysis on the compression error propagation from the altered activation data to the gradients, and then empirically investigate the impact of altered gradients over the entire training process. Based on these analyses, we then propose an improved lossy compressor and an adaptive scheme to dynamically configure the lossy compression error-bound and adjust the training batch size to further utilize the saved memory space for additional speedup. We evaluate our design against state-of-the-art solutions with four popular DNNs and the ImageNet dataset. Results demonstrate that our proposed framework can significantly reduce the training memory consumption by up to 13.5x and 1.8x over the baseline training and state-of-the-art framework with compression, respectively, with little or no accuracy loss.