 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Systems-Theoretic and Data-Driven Security Analysis in ML-enabled Medical Devices
Jun 18, 2025



The integration of AI/ML into medical devices is rapidly transforming healthcare by enhancing diagnostic and treatment facilities. However, this advancement also introduces serious cybersecurity risks due to the use of complex and often opaque models, extensive interconnectivity, interoperability with third-party peripheral devices, Internet connectivity, and vulnerabilities in the underlying technologies. These factors contribute to a broad attack surface and make threat prevention, detection, and mitigation challenging. Given the highly safety-critical nature of these devices, a cyberattack on these devices can cause the ML models to mispredict, thereby posing significant safety risks to patients. Therefore, ensuring the security of these devices from the time of design is essential. This paper underscores the urgency of addressing the cybersecurity challenges in ML-enabled medical devices at the pre-market phase. We begin by analyzing publicly available data on device recalls and adverse events, and known vulnerabilities, to understand the threat landscape of AI/ML-enabled medical devices and their repercussions on patient safety. Building on this analysis, we introduce a suite of tools and techniques designed by us to assist security analysts in conducting comprehensive premarket risk assessments. Our work aims to empower manufacturers to embed cybersecurity as a core design principle in AI/ML-enabled medical devices, thereby making them safe for patients.
Systematically Assessing the Security Risks of AI/ML-enabled Connected Healthcare Systems
Jan 30, 2024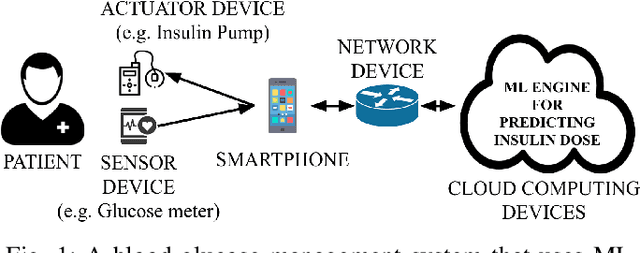
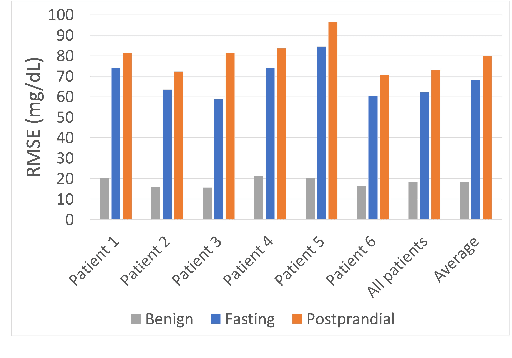
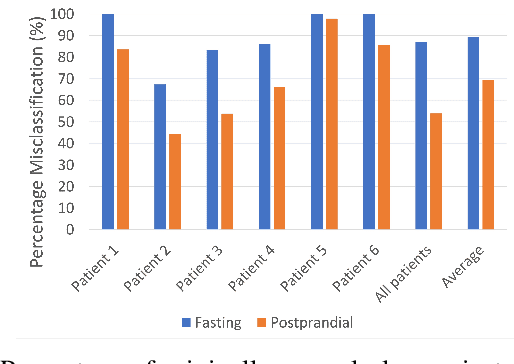
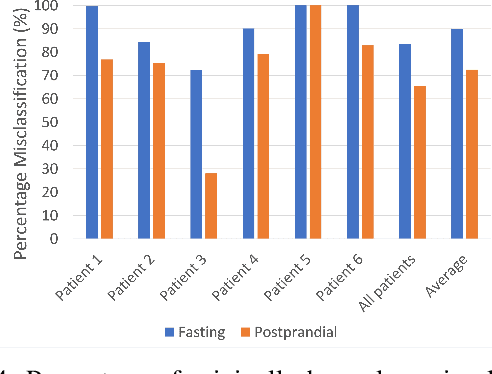
The adoption of machine-learning-enabled systems in the healthcare domain is on the rise. While the use of ML in healthcare has several benefits, it also expands the threat surface of medical systems. We show that the use of ML in medical systems, particularly connected systems that involve interfacing the ML engine with multiple peripheral devices, has security risks that might cause life-threatening damage to a patient's health in case of adversarial interventions. These new risks arise due to security vulnerabilities in the peripheral devices and communication channels. We present a case study where we demonstrate an attack on an ML-enabled blood glucose monitoring system by introducing adversarial data points during inference. We show that an adversary can achieve this by exploiting a known vulnerability in the Bluetooth communication channel connecting the glucose meter with the ML-enabled app. We further show that state-of-the-art risk assessment techniques are not adequate for identifying and assessing these new risks. Our study highlights the need for novel risk analysis methods for analyzing the security of AI-enabled connected health devices.
LogShield: A Transformer-based APT Detection System Leveraging Self-Attention
Nov 09, 2023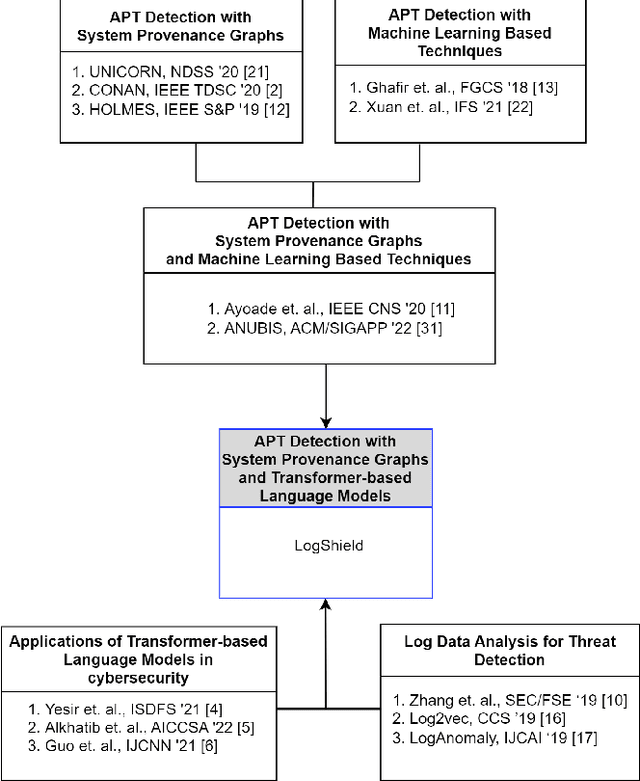
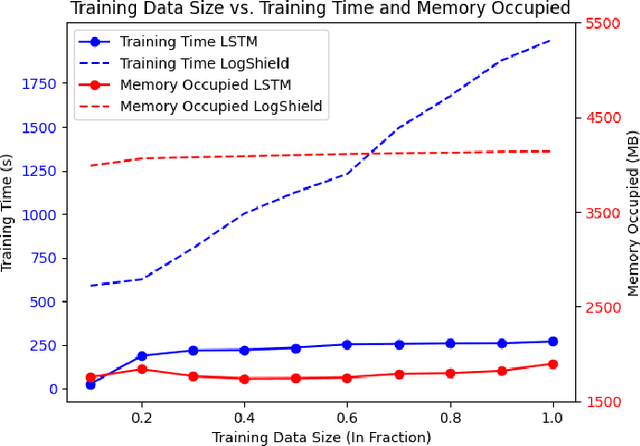
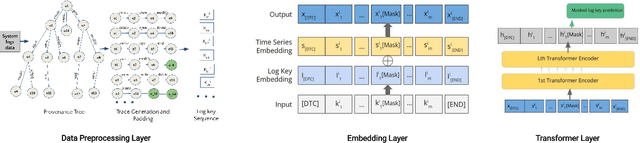
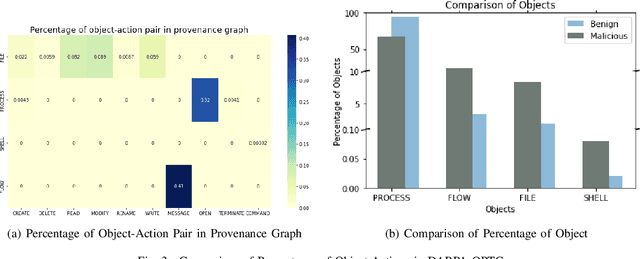
Cyber attacks are often identified using system and network logs. There have been significant prior works that utilize provenance graphs and ML techniques to detect attacks, specifically advanced persistent threats, which are very difficult to detect. Lately, there have been studies where transformer-based language models are being used to detect various types of attacks from system logs. However, no such attempts have been made in the case of APTs. In addition, existing state-of-the-art techniques that use system provenance graphs, lack a data processing framework generalized across datasets for optimal performance. For mitigating this limitation as well as exploring the effectiveness of transformer-based language models, this paper proposes LogShield, a framework designed to detect APT attack patterns leveraging the power of self-attention in transformers. We incorporate customized embedding layers to effectively capture the context of event sequences derived from provenance graphs. While acknowledging the computational overhead associated with training transformer networks, our framework surpasses existing LSTM and Language models regarding APT detection. We integrated the model parameters and training procedure from the RoBERTa model and conducted extensive experiments on well-known APT datasets (DARPA OpTC and DARPA TC E3). Our framework achieved superior F1 scores of 98% and 95% on the two datasets respectively, surpassing the F1 scores of 96% and 94% obtained by LSTM models. Our findings suggest that LogShield's performance benefits from larger datasets and demonstrates its potential for generalization across diverse domains. These findings contribute to the advancement of APT attack detection methods and underscore the significance of transformer-based architectures in addressing security challenges in computer systems.
ANUBIS: A Provenance Graph-Based Framework for Advanced Persistent Threat Detection
Dec 21, 2021
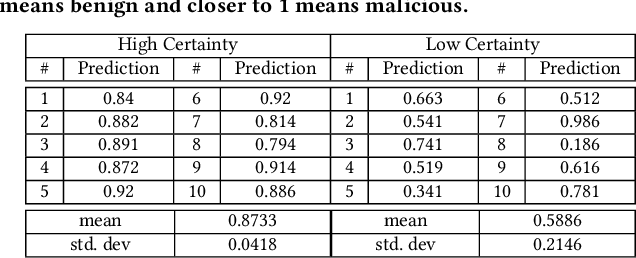


We present ANUBIS, a highly effective machine learning-based APT detection system. Our design philosophy for ANUBIS involves two principal components. Firstly, we intend ANUBIS to be effectively utilized by cyber-response teams. Therefore, prediction explainability is one of the main focuses of ANUBIS design. Secondly, ANUBIS uses system provenance graphs to capture causality and thereby achieve high detection performance. At the core of the predictive capability of ANUBIS, there is a Bayesian Neural Network that can tell how confident it is in its predictions. We evaluate ANUBIS against a recent APT dataset (DARPA OpTC) and show that ANUBIS can detect malicious activity akin to APT campaigns with high accuracy. Moreover, ANUBIS learns about high-level patterns that allow it to explain its predictions to threat analysts. The high predictive performance with explainable attack story reconstruction makes ANUBIS an effective tool to use for enterprise cyber defense.
Towards a Robust and Trustworthy Machine Learning System Development
Jan 08, 2021
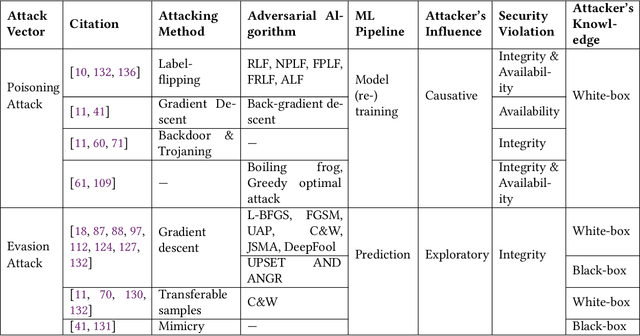
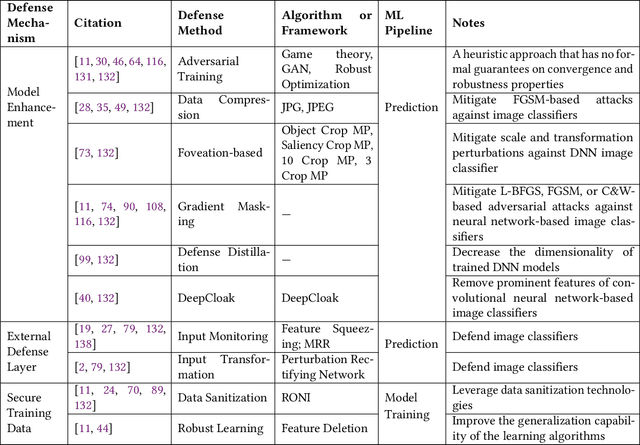
Machine Learning (ML) technologies have been widely adopted in many mission critical fields, such as cyber security, autonomous vehicle control, healthcare, etc. to support intelligent decision-making. While ML has demonstrated impressive performance over conventional methods in these applications, concerns arose with respect to system resilience against ML-specific security attacks and privacy breaches as well as the trust that users have in these systems. In this article, firstly we present our recent systematic and comprehensive survey on the state-of-the-art ML robustness and trustworthiness technologies from a security engineering perspective, which covers all aspects of secure ML system development including threat modeling, common offensive and defensive technologies, privacy-preserving machine learning, user trust in the context of machine learning, and empirical evaluation for ML model robustness. Secondly, we then push our studies forward above and beyond a survey by describing a metamodel we created that represents the body of knowledge in a standard and visualized way for ML practitioners. We further illustrate how to leverage the metamodel to guide a systematic threat analysis and security design process in a context of generic ML system development, which extends and scales up the classic process. Thirdly, we propose future research directions motivated by our findings to advance the development of robust and trustworthy ML systems. Our work differs from existing surveys in this area in that, to the best of our knowledge, it is the first of its kind of engineering effort to (i) explore the fundamental principles and best practices to support robust and trustworthy ML system development; and (ii) study the interplay of robustness and user trust in the context of ML systems.