 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Towards a Robust and Trustworthy Machine Learning System Development
Jan 08, 2021
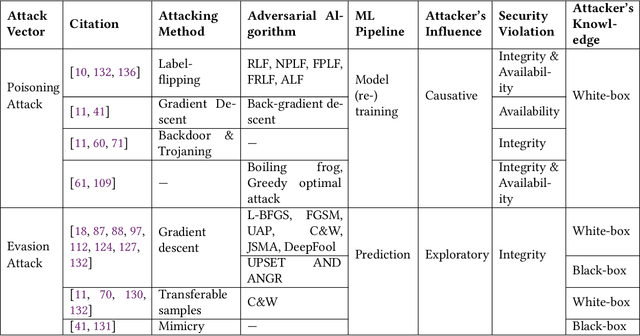
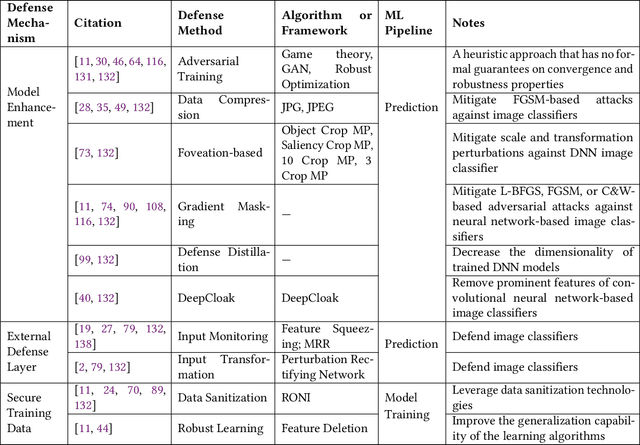
Machine Learning (ML) technologies have been widely adopted in many mission critical fields, such as cyber security, autonomous vehicle control, healthcare, etc. to support intelligent decision-making. While ML has demonstrated impressive performance over conventional methods in these applications, concerns arose with respect to system resilience against ML-specific security attacks and privacy breaches as well as the trust that users have in these systems. In this article, firstly we present our recent systematic and comprehensive survey on the state-of-the-art ML robustness and trustworthiness technologies from a security engineering perspective, which covers all aspects of secure ML system development including threat modeling, common offensive and defensive technologies, privacy-preserving machine learning, user trust in the context of machine learning, and empirical evaluation for ML model robustness. Secondly, we then push our studies forward above and beyond a survey by describing a metamodel we created that represents the body of knowledge in a standard and visualized way for ML practitioners. We further illustrate how to leverage the metamodel to guide a systematic threat analysis and security design process in a context of generic ML system development, which extends and scales up the classic process. Thirdly, we propose future research directions motivated by our findings to advance the development of robust and trustworthy ML systems. Our work differs from existing surveys in this area in that, to the best of our knowledge, it is the first of its kind of engineering effort to (i) explore the fundamental principles and best practices to support robust and trustworthy ML system development; and (ii) study the interplay of robustness and user trust in the context of ML systems.