 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Label Encodings for Deep Regression
Mar 04, 2023



Deep regression networks are widely used to tackle the problem of predicting a continuous value for a given input. Task-specialized approaches for training regression networks have shown significant improvement over generic approaches, such as direct regression. More recently, a generic approach based on regression by binary classification using binary-encoded labels has shown significant improvement over direct regression. The space of label encodings for regression is large. Lacking heretofore have been automated approaches to find a good label encoding for a given application. This paper introduces Regularized Label Encoding Learning (RLEL) for end-to-end training of an entire network and its label encoding. RLEL provides a generic approach for tackling regression. Underlying RLEL is our observation that the search space of label encodings can be constrained and efficiently explored by using a continuous search space of real-valued label encodings combined with a regularization function designed to encourage encodings with certain properties. These properties balance the probability of classification error in individual bits against error correction capability. Label encodings found by RLEL result in lower or comparable errors to manually designed label encodings. Applying RLEL results in 10.9% and 12.4% improvement in Mean Absolute Error (MAE) over direct regression and multiclass classification, respectively. Our evaluation demonstrates that RLEL can be combined with off-the-shelf feature extractors and is suitable across different architectures, datasets, and tasks. Code is available at https://github.com/ubc-aamodt-group/RLEL_regression.
* Published at ICLR 2023 (Notable top-25%)
Label Encoding for Regression Networks
Dec 04, 2022



Deep neural networks are used for a wide range of regression problems. However, there exists a significant gap in accuracy between specialized approaches and generic direct regression in which a network is trained by minimizing the squared or absolute error of output labels. Prior work has shown that solving a regression problem with a set of binary classifiers can improve accuracy by utilizing well-studied binary classification algorithms. We introduce binary-encoded labels (BEL), which generalizes the application of binary classification to regression by providing a framework for considering arbitrary multi-bit values when encoding target values. We identify desirable properties of suitable encoding and decoding functions used for the conversion between real-valued and binary-encoded labels based on theoretical and empirical study. These properties highlight a tradeoff between classification error probability and error-correction capabilities of label encodings. BEL can be combined with off-the-shelf task-specific feature extractors and trained end-to-end. We propose a series of sample encoding, decoding, and training loss functions for BEL and demonstrate they result in lower error than direct regression and specialized approaches while being suitable for a diverse set of regression problems, network architectures, and evaluation metrics. BEL achieves state-of-the-art accuracies for several regression benchmarks. Code is available at https://github.com/ubc-aamodt-group/BEL_regression.
* Published at ICLR 2022
Characterizing and Improving the Resilience of Accelerators in Autonomous Robots
Oct 17, 2021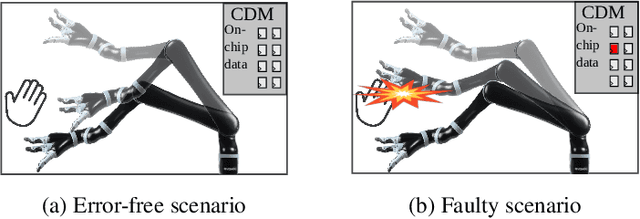
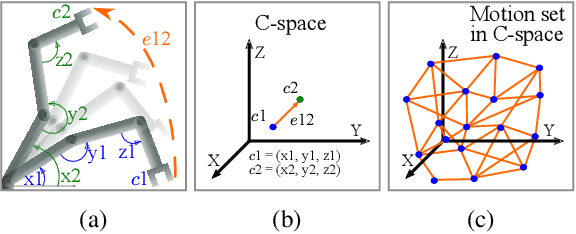

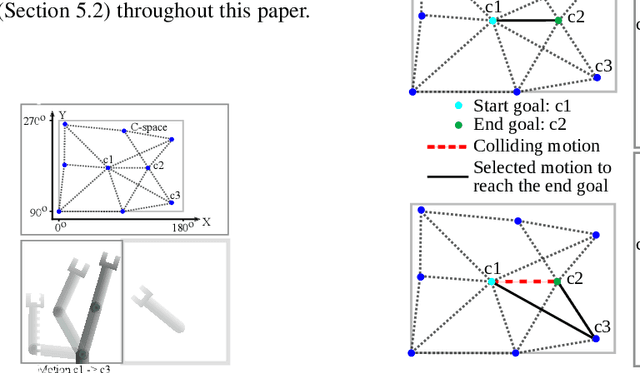
Motion planning is a computationally intensive and well-studied problem in autonomous robots. However, motion planning hardware accelerators (MPA) must be soft-error resilient for deployment in safety-critical applications, and blanket application of traditional mitigation techniques is ill-suited due to cost, power, and performance overheads. We propose Collision Exposure Factor (CEF), a novel metric to assess the failure vulnerability of circuits processing spatial relationships, including motion planning. CEF is based on the insight that the safety violation probability increases with the surface area of the physical space exposed by a bit-flip. We evaluate CEF on four MPAs. We demonstrate empirically that CEF is correlated with safety violation probability, and that CEF-aware selective error mitigation provides 12.3x, 9.6x, and 4.2x lower Failures-In-Time (FIT) rate on average for the same amount of protected memory compared to uniform, bit-position, and access-frequency-aware selection of critical data. Furthermore, we show how to employ CEF to enable fault characterization using 23,000x fewer fault injection (FI) experiments than exhaustive FI, and evaluate our FI approach on different robots and MPAs. We demonstrate that CEF-aware FI can provide insights on vulnerable bits in an MPA while taking the same amount of time as uniform statistical FI. Finally, we use the CEF to formulate guidelines for designing soft-error resilient MPAs.
Sparse Weight Activation Training
Jan 07, 2020



Training convolutional neural networks (CNNs) is time-consuming. Prior work has explored how to reduce the computational demands of training by eliminating gradients with relatively small magnitude. We show that eliminating small magnitude components has limited impact on the direction of high-dimensional vectors. However, in the context of training a CNN, we find that eliminating small magnitude components of weight and activation vectors allows us to train deeper networks on more complex datasets versus eliminating small magnitude components of gradients. We propose Sparse Weight Activation Training (SWAT), an algorithm that embodies these observations. SWAT reduces computations by 50% to 80% with better accuracy at a given level of sparsity versus the Dynamic Sparse Graph algorithm. SWAT also reduces memory footprint by 23% to 37% for activations and 50% to 80% for weights.