 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHype: Hyperbolic Embeddings for Hierarchical Open-Vocabulary Radiance Fields
Oct 24, 2025Modeling the inherent hierarchical structure of 3D objects and 3D scenes is highly desirable, as it enables a more holistic understanding of environments for autonomous agents. Accomplishing this with implicit representations, such as Neural Radiance Fields, remains an unexplored challenge. Existing methods that explicitly model hierarchical structures often face significant limitations: they either require multiple rendering passes to capture embeddings at different levels of granularity, significantly increasing inference time, or rely on predefined, closed-set discrete hierarchies that generalize poorly to the diverse and nuanced structures encountered by agents in the real world. To address these challenges, we propose OpenHype, a novel approach that represents scene hierarchies using a continuous hyperbolic latent space. By leveraging the properties of hyperbolic geometry, OpenHype naturally encodes multi-scale relationships and enables smooth traversal of hierarchies through geodesic paths in latent space. Our method outperforms state-of-the-art approaches on standard benchmarks, demonstrating superior efficiency and adaptability in 3D scene understanding.
Efficient Continuous Group Convolutions for Local SE(3) Equivariance in 3D Point Clouds
Feb 11, 2025Extending the translation equivariance property of convolutional neural networks to larger symmetry groups has been shown to reduce sample complexity and enable more discriminative feature learning. Further, exploiting additional symmetries facilitates greater weight sharing than standard convolutions, leading to an enhanced network expressivity without an increase in parameter count. However, extending the equivariant properties of a convolution layer comes at a computational cost. In particular, for 3D data, expanding equivariance to the SE(3) group (rotation and translation) results in a 6D convolution operation, which is not tractable for larger data samples such as 3D scene scans. While efforts have been made to develop efficient SE(3) equivariant networks, existing approaches rely on discretization or only introduce global rotation equivariance. This limits their applicability to point clouds representing a scene composed of multiple objects. This work presents an efficient, continuous, and local SE(3) equivariant convolution layer for point cloud processing based on general group convolution and local reference frames. Our experiments show that our approach achieves competitive or superior performance across a range of datasets and tasks, including object classification and semantic segmentation, with negligible computational overhead.
On the importance of local and global feature learning for automated measurable residual disease detection in flow cytometry data
Nov 23, 2024This paper evaluates various deep learning methods for measurable residual disease (MRD) detection in flow cytometry (FCM) data, addressing questions regarding the benefits of modeling long-range dependencies, methods of obtaining global information, and the importance of learning local features. Based on our findings, we propose two adaptations to the current state-of-the-art (SOTA) model. Our contributions include an enhanced SOTA model, demonstrating superior performance on publicly available datasets and improved generalization across laboratories, as well as valuable insights for the FCM community, guiding future DL architecture designs for FCM data analysis. The code is available at \url{https://github.com/lisaweijler/flowNetworks}.
TTT-KD: Test-Time Training for 3D Semantic Segmentation through Knowledge Distillation from Foundation Models
Mar 18, 2024Test-Time Training (TTT) proposes to adapt a pre-trained network to changing data distributions on-the-fly. In this work, we propose the first TTT method for 3D semantic segmentation, TTT-KD, which models Knowledge Distillation (KD) from foundation models (e.g. DINOv2) as a self-supervised objective for adaptation to distribution shifts at test-time. Given access to paired image-pointcloud (2D-3D) data, we first optimize a 3D segmentation backbone for the main task of semantic segmentation using the pointclouds and the task of 2D $\to$ 3D KD by using an off-the-shelf 2D pre-trained foundation model. At test-time, our TTT-KD updates the 3D segmentation backbone for each test sample, by using the self-supervised task of knowledge distillation, before performing the final prediction. Extensive evaluations on multiple indoor and outdoor 3D segmentation benchmarks show the utility of TTT-KD, as it improves performance for both in-distribution (ID) and out-of-distribution (ODO) test datasets. We achieve a gain of up to 13% mIoU (7% on average) when the train and test distributions are similar and up to 45% (20% on average) when adapting to OOD test samples.
FATE: Feature-Agnostic Transformer-based Encoder for learning generalized embedding spaces in flow cytometry data
Nov 06, 2023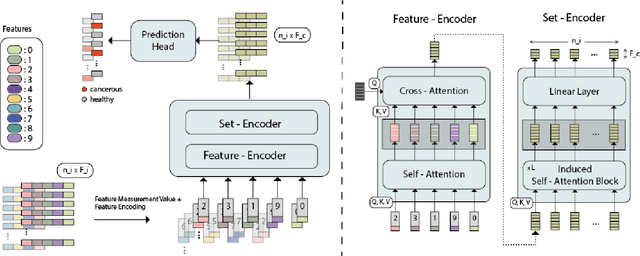
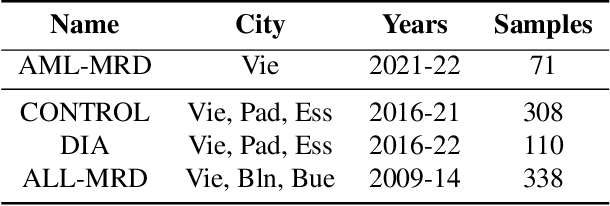
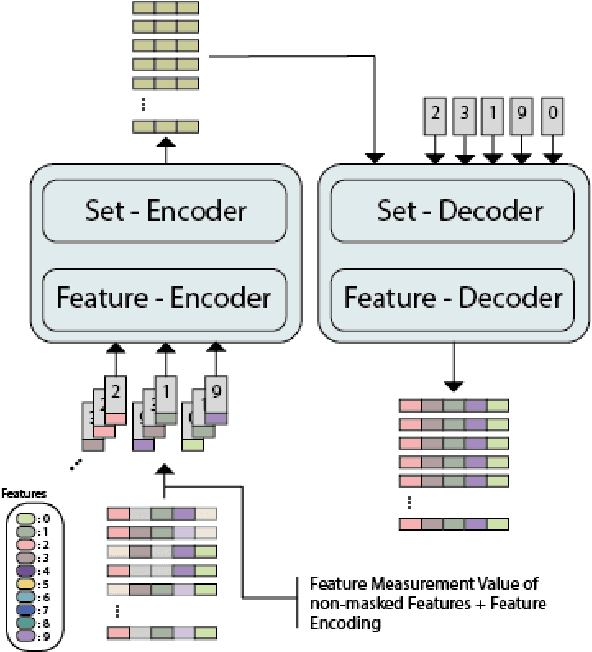
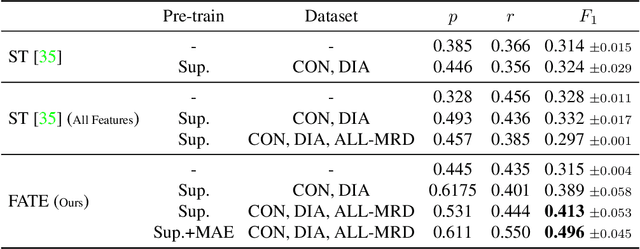
While model architectures and training strategies have become more generic and flexible with respect to different data modalities over the past years, a persistent limitation lies in the assumption of fixed quantities and arrangements of input features. This limitation becomes particularly relevant in scenarios where the attributes captured during data acquisition vary across different samples. In this work, we aim at effectively leveraging data with varying features, without the need to constrain the input space to the intersection of potential feature sets or to expand it to their union. We propose a novel architecture that can directly process data without the necessity of aligned feature modalities by learning a general embedding space that captures the relationship between features across data samples with varying sets of features. This is achieved via a set-transformer architecture augmented by feature-encoder layers, thereby enabling the learning of a shared latent feature space from data originating from heterogeneous feature spaces. The advantages of the model are demonstrated for automatic cancer cell detection in acute myeloid leukemia in flow cytometry data, where the features measured during acquisition often vary between samples. Our proposed architecture's capacity to operate seamlessly across incongruent feature spaces is particularly relevant in this context, where data scarcity arises from the low prevalence of the disease. The code is available for research purposes at https://github.com/lisaweijler/FATE.
Explainable Techniques for Analyzing Flow Cytometry Cell Transformers
Jul 27, 2023



Explainability for Deep Learning Models is especially important for clinical applications, where decisions of automated systems have far-reaching consequences. While various post-hoc explainable methods, such as attention visualization and saliency maps, already exist for common data modalities, including natural language and images, little work has been done to adapt them to the modality of Flow CytoMetry (FCM) data. In this work, we evaluate the usage of a transformer architecture called ReluFormer that ease attention visualization as well as we propose a gradient- and an attention-based visualization technique tailored for FCM. We qualitatively evaluate the visualization techniques for cell classification and polygon regression on pediatric Acute Lymphoblastic Leukemia (ALL) FCM samples. The results outline the model's decision process and demonstrate how to utilize the proposed techniques to inspect the trained model. The gradient-based visualization not only identifies cells that are most significant for a particular prediction but also indicates the directions in the FCM feature space in which changes have the most impact on the prediction. The attention visualization provides insights on the transformer's decision process when handling FCM data. We show that different attention heads specialize by attending to different biologically meaningful sub-populations in the data, even though the model retrieved solely supervised binary classification signals during training.
Automated Identification of Cell Populations in Flow Cytometry Data with Transformers
Aug 23, 2021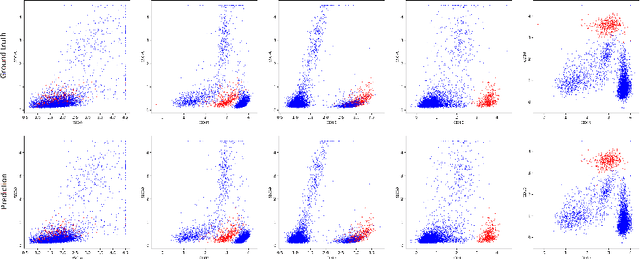
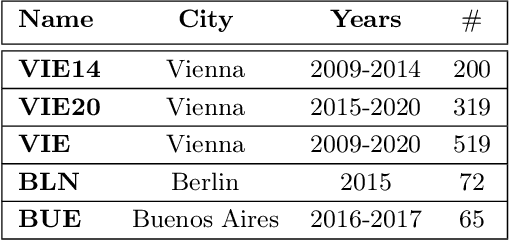
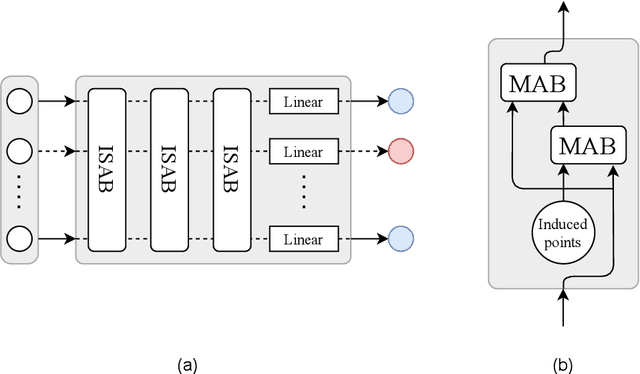
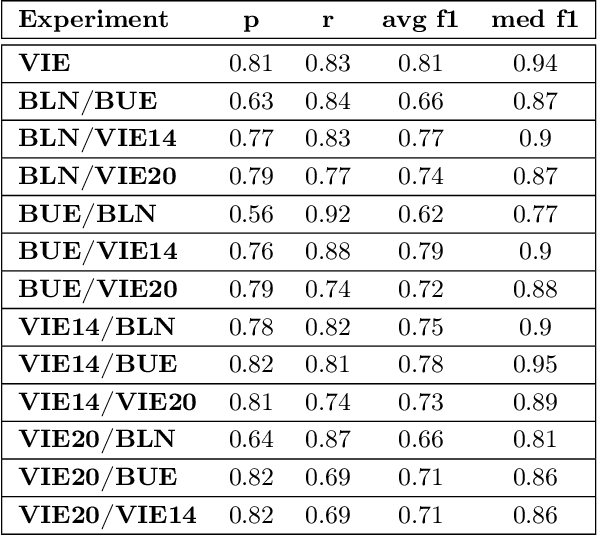
Acute Lymphoblastic Leukemia (ALL) is the most frequent hematologic malignancy in children and adolescents. A strong prognostic factor in ALL is given by the Minimal Residual Disease (MRD), which is a measure for the number of leukemic cells persistent in a patient. Manual MRD assessment from Multiparameter Flow Cytometry (FCM) data after treatment is time-consuming and subjective. In this work, we present an automated method to compute the MRD value directly from FCM data. We present a novel neural network approach based on the transformer architecture that learns to directly identify blast cells in a sample. We train our method in a supervised manner and evaluate it on publicly available ALL FCM data from three different clinical centers. Our method reaches a median f1 score of ~0.93 when tested on 200 B-ALL samples.