 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnreflected Use of Tabular Data Repositories Can Undermine Research Quality
Mar 12, 2025


Data repositories have accumulated a large number of tabular datasets from various domains. Machine Learning researchers are actively using these datasets to evaluate novel approaches. Consequently, data repositories have an important standing in tabular data research. They not only host datasets but also provide information on how to use them in supervised learning tasks. In this paper, we argue that, despite great achievements in usability, the unreflected usage of datasets from data repositories may have led to reduced research quality and scientific rigor. We present examples from prominent recent studies that illustrate the problematic use of datasets from OpenML, a large data repository for tabular data. Our illustrations help users of data repositories avoid falling into the traps of (1) using suboptimal model selection strategies, (2) overlooking strong baselines, and (3) inappropriate preprocessing. In response, we discuss possible solutions for how data repositories can prevent the inappropriate use of datasets and become the cornerstones for improved overall quality of empirical research studies.
A Data-Centric Perspective on Evaluating Machine Learning Models for Tabular Data
Jul 02, 2024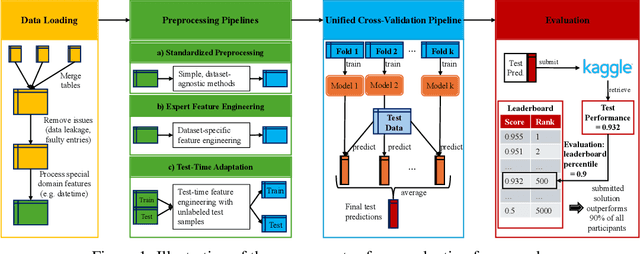
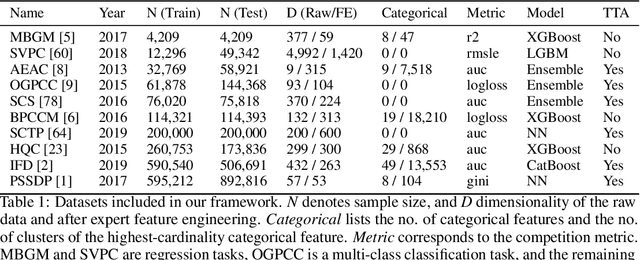

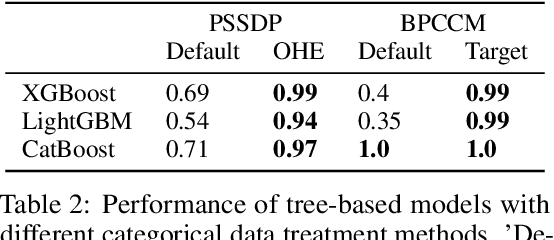
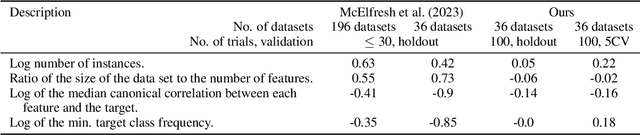
Tabular data is prevalent in real-world machine learning applications, and new models for supervised learning of tabular data are frequently proposed. Comparative studies assessing the performance of models typically consist of model-centric evaluation setups with overly standardized data preprocessing. This paper demonstrates that such model-centric evaluations are biased, as real-world modeling pipelines often require dataset-specific preprocessing and feature engineering. Therefore, we propose a data-centric evaluation framework. We select 10 relevant datasets from Kaggle competitions and implement expert-level preprocessing pipelines for each dataset. We conduct experiments with different preprocessing pipelines and hyperparameter optimization (HPO) regimes to quantify the impact of model selection, HPO, feature engineering, and test-time adaptation. Our main findings are: 1. After dataset-specific feature engineering, model rankings change considerably, performance differences decrease, and the importance of model selection reduces. 2. Recent models, despite their measurable progress, still significantly benefit from manual feature engineering. This holds true for both tree-based models and neural networks. 3. While tabular data is typically considered static, samples are often collected over time, and adapting to distribution shifts can be important even in supposedly static data. These insights suggest that research efforts should be directed toward a data-centric perspective, acknowledging that tabular data requires feature engineering and often exhibits temporal characteristics.
Enabling Mixed Effects Neural Networks for Diverse, Clustered Data Using Monte Carlo Methods
Jul 01, 2024



Neural networks often assume independence among input data samples, disregarding correlations arising from inherent clustering patterns in real-world datasets (e.g., due to different sites or repeated measurements). Recently, mixed effects neural networks (MENNs) which separate cluster-specific 'random effects' from cluster-invariant 'fixed effects' have been proposed to improve generalization and interpretability for clustered data. However, existing methods only allow for approximate quantification of cluster effects and are limited to regression and binary targets with only one clustering feature. We present MC-GMENN, a novel approach employing Monte Carlo methods to train Generalized Mixed Effects Neural Networks. We empirically demonstrate that MC-GMENN outperforms existing mixed effects deep learning models in terms of generalization performance, time complexity, and quantification of inter-cluster variance. Additionally, MC-GMENN is applicable to a wide range of datasets, including multi-class classification tasks with multiple high-cardinality categorical features. For these datasets, we show that MC-GMENN outperforms conventional encoding and embedding methods, simultaneously offering a principled methodology for interpreting the effects of clustering patterns.
Explaining Neural Networks without Access to Training Data
Jun 10, 2022We consider generating explanations for neural networks in cases where the network's training data is not accessible, for instance due to privacy or safety issues. Recently, $\mathcal{I}$-Nets have been proposed as a sample-free approach to post-hoc, global model interpretability that does not require access to training data. They formulate interpretation as a machine learning task that maps network representations (parameters) to a representation of an interpretable function. In this paper, we extend the $\mathcal{I}$-Net framework to the cases of standard and soft decision trees as surrogate models. We propose a suitable decision tree representation and design of the corresponding $\mathcal{I}$-Net output layers. Furthermore, we make $\mathcal{I}$-Nets applicable to real-world tasks by considering more realistic distributions when generating the $\mathcal{I}$-Net's training data. We empirically evaluate our approach against traditional global, post-hoc interpretability approaches and show that it achieves superior results when the training data is not accessible.