 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProMap: Datasets for Product Mapping in E-commerce
Sep 13, 2023The goal of product mapping is to decide, whether two listings from two different e-shops describe the same products. Existing datasets of matching and non-matching pairs of products, however, often suffer from incomplete product information or contain only very distant non-matching products. Therefore, while predictive models trained on these datasets achieve good results on them, in practice, they are unusable as they cannot distinguish very similar but non-matching pairs of products. This paper introduces two new datasets for product mapping: ProMapCz consisting of 1,495 Czech product pairs and ProMapEn consisting of 1,555 English product pairs of matching and non-matching products manually scraped from two pairs of e-shops. The datasets contain both images and textual descriptions of the products, including their specifications, making them one of the most complete datasets for product mapping. Additionally, the non-matching products were selected in two phases, creating two types of non-matches -- close non-matches and medium non-matches. Even the medium non-matches are pairs of products that are much more similar than non-matches in other datasets -- for example, they still need to have the same brand and similar name and price. After simple data preprocessing, several machine learning algorithms were trained on these and two the other datasets to demonstrate the complexity and completeness of ProMap datasets. ProMap datasets are presented as a golden standard for further research of product mapping filling the gaps in existing ones.
Reading Comprehension in Czech via Machine Translation and Cross-lingual Transfer
Jul 03, 2020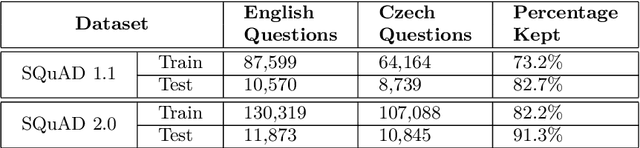
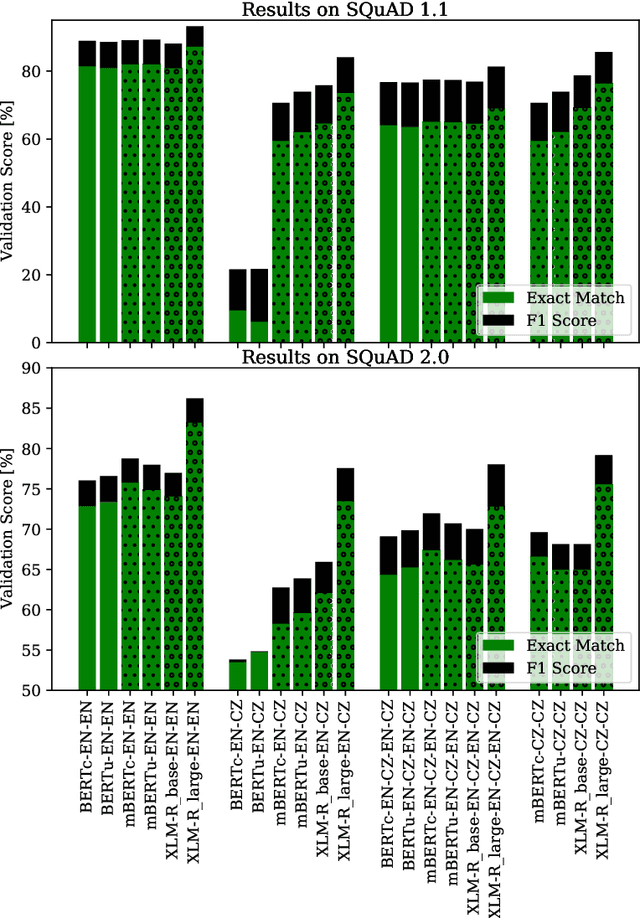
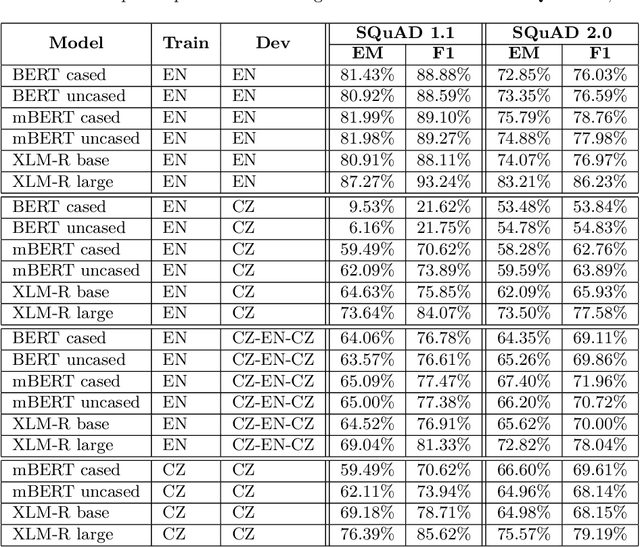
Reading comprehension is a well studied task, with huge training datasets in English. This work focuses on building reading comprehension systems for Czech, without requiring any manually annotated Czech training data. First of all, we automatically translated SQuAD 1.1 and SQuAD 2.0 datasets to Czech to create training and development data, which we release at http://hdl.handle.net/11234/1-3249. We then trained and evaluated several BERT and XLM-RoBERTa baseline models. However, our main focus lies in cross-lingual transfer models. We report that a XLM-RoBERTa model trained on English data and evaluated on Czech achieves very competitive performance, only approximately 2 percent points worse than a~model trained on the translated Czech data. This result is extremely good, considering the fact that the model has not seen any Czech data during training. The cross-lingual transfer approach is very flexible and provides a reading comprehension in any language, for which we have enough monolingual raw texts.