 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegime-Adaptive Continual Learning for Portfolio Management
May 29, 2026Financial markets are inherently non-stationary, exhibiting frequent regime shifts and structural changes that render traditional Portfolio Management (PM) approaches ineffective. Existing remedies, such as rolling-window retraining and naive online fine-tuning, are hindered by high computational costs and insufficient knowledge utilization, respectively, resulting in low returns and limited adaptability. Continual learning (CL) offers a promising paradigm by enabling trading agents to accumulate and transfer knowledge across sequential tasks. In this paper, we propose \textbf{Re}gime-aware \textbf{C}ontinual \textbf{A}daptive \textbf{P}ortfolio management (\textbf{ReCAP}), a novel framework that integrates CL into PM to address the challenges of dynamic financial environments. ReCAP employs an adaptive regime detection module to segment historical market data into variable-length regimes, enabling regime-specific learning of policy vectors and the construction of a policy library. During continual trading, a regime-gate module adaptively combines policy vectors from the library based on the current market state, facilitating rapid adaptation to newly detected regimes. Only the regime-gate and the current regime's policy vector are continually updated to preserve useful knowledge effectively. Extensive experiments on five real-world datasets demonstrate that ReCAP consistently outperforms popular baselines, achieving superior returns in long-term investment horizons and rapid adaptation to regime shifts.
Action-Adaptive Continual Learning: Enabling Policy Generalization under Dynamic Action Spaces
Jun 06, 2025Continual Learning (CL) is a powerful tool that enables agents to learn a sequence of tasks, accumulating knowledge learned in the past and using it for problem-solving or future task learning. However, existing CL methods often assume that the agent's capabilities remain static within dynamic environments, which doesn't reflect real-world scenarios where capabilities dynamically change. This paper introduces a new and realistic problem: Continual Learning with Dynamic Capabilities (CL-DC), posing a significant challenge for CL agents: How can policy generalization across different action spaces be achieved? Inspired by the cortical functions, we propose an Action-Adaptive Continual Learning framework (AACL) to address this challenge. Our framework decouples the agent's policy from the specific action space by building an action representation space. For a new action space, the encoder-decoder of action representations is adaptively fine-tuned to maintain a balance between stability and plasticity. Furthermore, we release a benchmark based on three environments to validate the effectiveness of methods for CL-DC. Experimental results demonstrate that our framework outperforms popular methods by generalizing the policy across action spaces.
Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
Dec 18, 2024



Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
* This paper has been Accepted on AAAI2025
Hierarchical Continual Reinforcement Learning via Large Language Model
Feb 01, 2024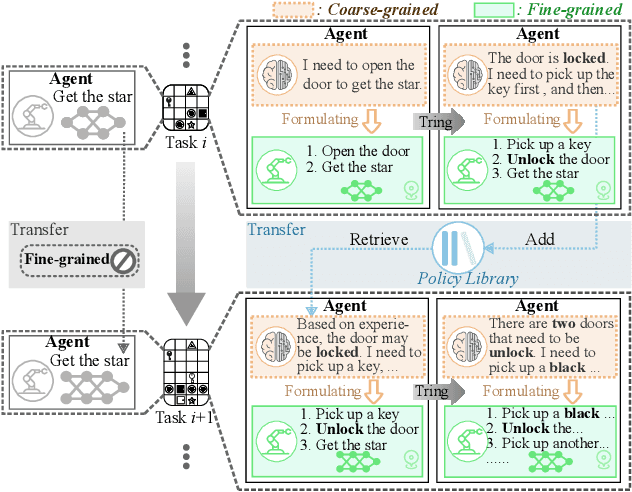

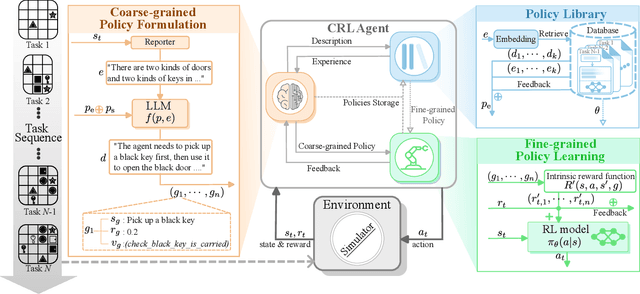
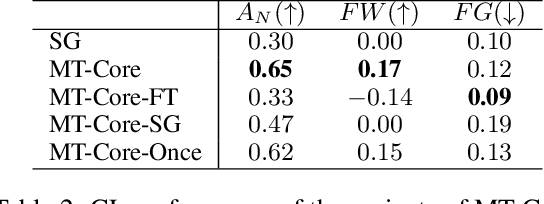
The ability to learn continuously in dynamic environments is a crucial requirement for reinforcement learning (RL) agents applying in the real world. Despite the progress in continual reinforcement learning (CRL), existing methods often suffer from insufficient knowledge transfer, particularly when the tasks are diverse. To address this challenge, we propose a new framework, Hierarchical Continual reinforcement learning via large language model (Hi-Core), designed to facilitate the transfer of high-level knowledge. Hi-Core orchestrates a twolayer structure: high-level policy formulation by a large language model (LLM), which represents agenerates a sequence of goals, and low-level policy learning that closely aligns with goal-oriented RL practices, producing the agent's actions in response to the goals set forth. The framework employs feedback to iteratively adjust and verify highlevel policies, storing them along with low-level policies within a skill library. When encountering a new task, Hi-Core retrieves relevant experience from this library to help to learning. Through experiments on Minigrid, Hi-Core has demonstrated its effectiveness in handling diverse CRL tasks, which outperforms popular baselines.