 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Continual Reinforcement Learning via Large Language Model
Paper and Code
Feb 01, 2024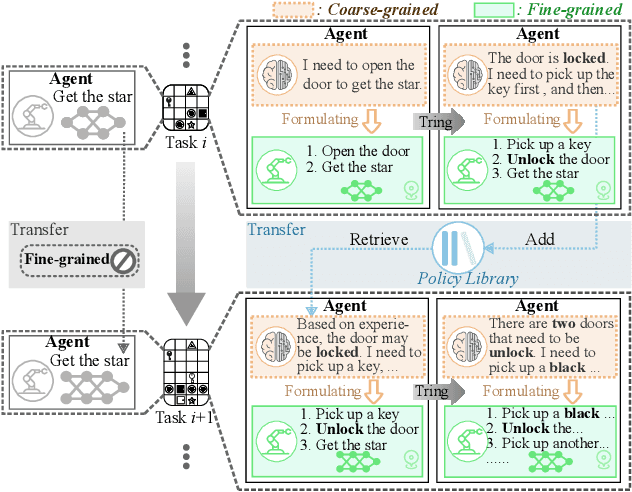

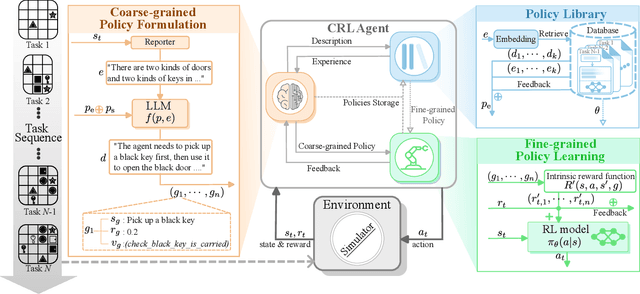
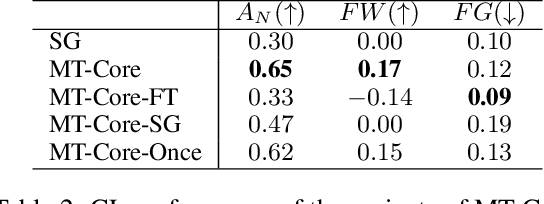
The ability to learn continuously in dynamic environments is a crucial requirement for reinforcement learning (RL) agents applying in the real world. Despite the progress in continual reinforcement learning (CRL), existing methods often suffer from insufficient knowledge transfer, particularly when the tasks are diverse. To address this challenge, we propose a new framework, Hierarchical Continual reinforcement learning via large language model (Hi-Core), designed to facilitate the transfer of high-level knowledge. Hi-Core orchestrates a twolayer structure: high-level policy formulation by a large language model (LLM), which represents agenerates a sequence of goals, and low-level policy learning that closely aligns with goal-oriented RL practices, producing the agent's actions in response to the goals set forth. The framework employs feedback to iteratively adjust and verify highlevel policies, storing them along with low-level policies within a skill library. When encountering a new task, Hi-Core retrieves relevant experience from this library to help to learning. Through experiments on Minigrid, Hi-Core has demonstrated its effectiveness in handling diverse CRL tasks, which outperforms popular baselines.