 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Unsupervised Person Re-Identification with Contrastive Learning
Paper and Code
May 17, 2021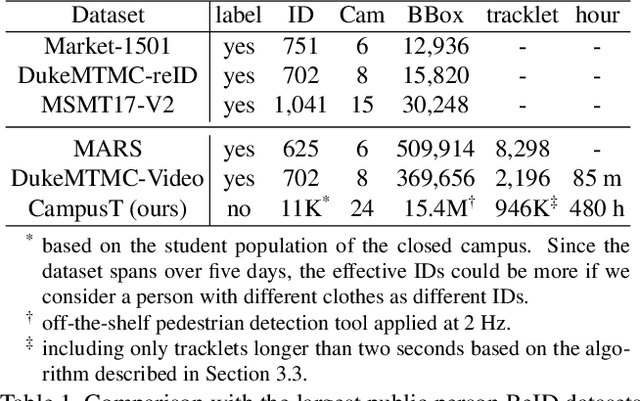
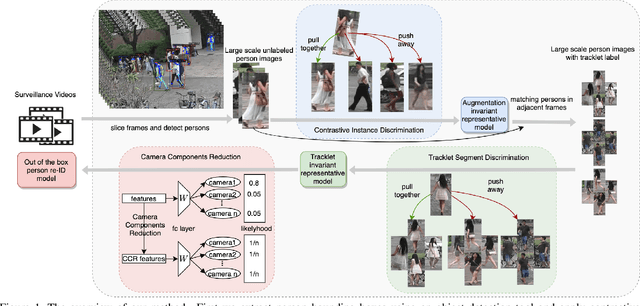

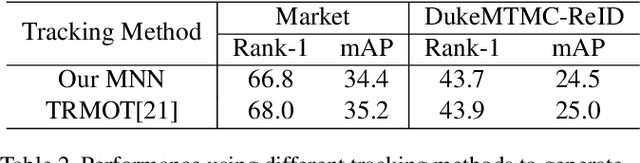
Existing public person Re-Identification~(ReID) datasets are small in modern terms because of labeling difficulty. Although unlabeled surveillance video is abundant and relatively easy to obtain, it is unclear how to leverage these footage to learn meaningful ReID representations. In particular, most existing unsupervised and domain adaptation ReID methods utilize only the public datasets in their experiments, with labels removed. In addition, due to small data sizes, these methods usually rely on fine tuning by the unlabeled training data in the testing domain to achieve good performance. Inspired by the recent progress of large-scale self-supervised image classification using contrastive learning, we propose to learn ReID representation from large-scale unlabeled surveillance video alone. Assisted by off-the-shelf pedestrian detection tools, we apply the contrastive loss at both the image and the tracklet levels. Together with a principal component analysis step using camera labels freely available, our evaluation using a large-scale unlabeled dataset shows far superior performance among unsupervised methods that do not use any training data in the testing domain. Furthermore, the accuracy improves with the data size and therefore our method has great potential with even larger and more diversified datasets.