 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Nov 07, 2024
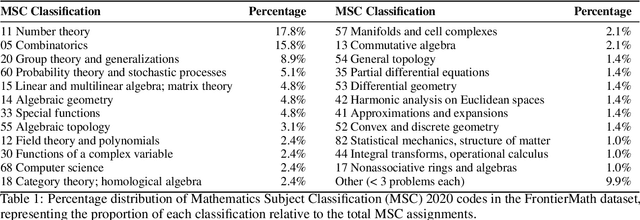
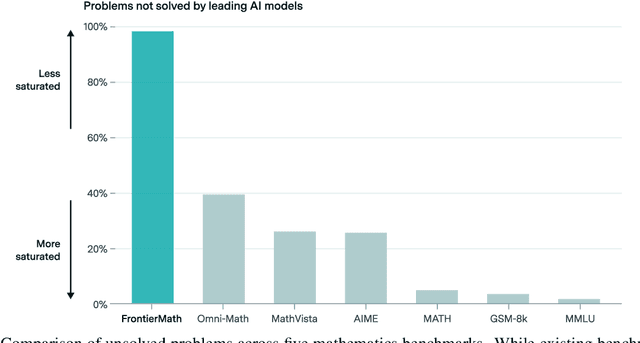
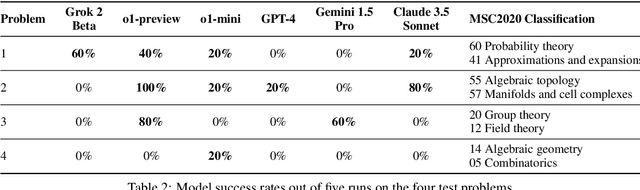
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
Intention-Aware Planner for Robust and Safe Aerial Tracking
Sep 16, 2023



The intention of the target can help us to estimate its future motion state more accurately. This paper proposes an intention-aware planner to enhance safety and robustness in aerial tracking applications. Firstly, we utilize the Mediapipe framework to estimate target's pose. A risk assessment function and a state observation function are designed to predict the target intention. Afterwards, an intention-driven hybrid A* method is proposed for target motion prediction, ensuring that the target's future positions align with its intention. Finally, an intention-aware optimization approach, in conjunction with particular penalty formulations, is designed to generate a spatial-temporal optimal trajectory. Benchmark comparisons validate the superior performance of our proposed methodology across diverse scenarios. This is attributed to the integration of the target intention into the planner through coupled formulations.
Large-Scale Unsupervised Person Re-Identification with Contrastive Learning
May 17, 2021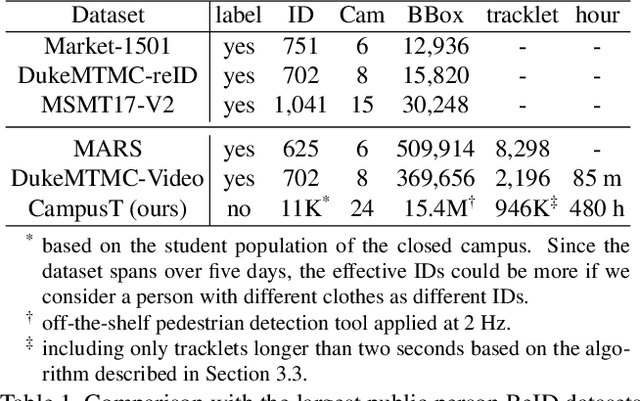
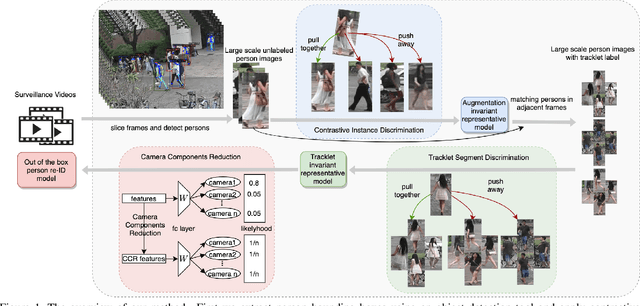

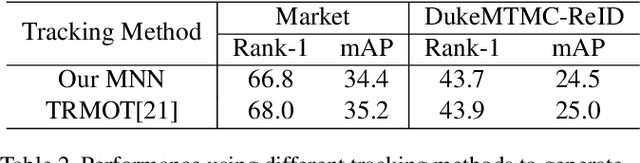
Existing public person Re-Identification~(ReID) datasets are small in modern terms because of labeling difficulty. Although unlabeled surveillance video is abundant and relatively easy to obtain, it is unclear how to leverage these footage to learn meaningful ReID representations. In particular, most existing unsupervised and domain adaptation ReID methods utilize only the public datasets in their experiments, with labels removed. In addition, due to small data sizes, these methods usually rely on fine tuning by the unlabeled training data in the testing domain to achieve good performance. Inspired by the recent progress of large-scale self-supervised image classification using contrastive learning, we propose to learn ReID representation from large-scale unlabeled surveillance video alone. Assisted by off-the-shelf pedestrian detection tools, we apply the contrastive loss at both the image and the tracklet levels. Together with a principal component analysis step using camera labels freely available, our evaluation using a large-scale unlabeled dataset shows far superior performance among unsupervised methods that do not use any training data in the testing domain. Furthermore, the accuracy improves with the data size and therefore our method has great potential with even larger and more diversified datasets.