 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Uncertainty Learning in Face Recognition
Mar 25, 2020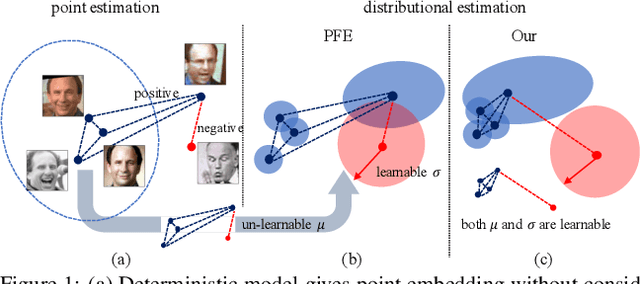
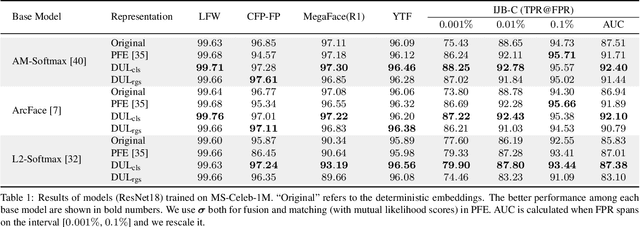

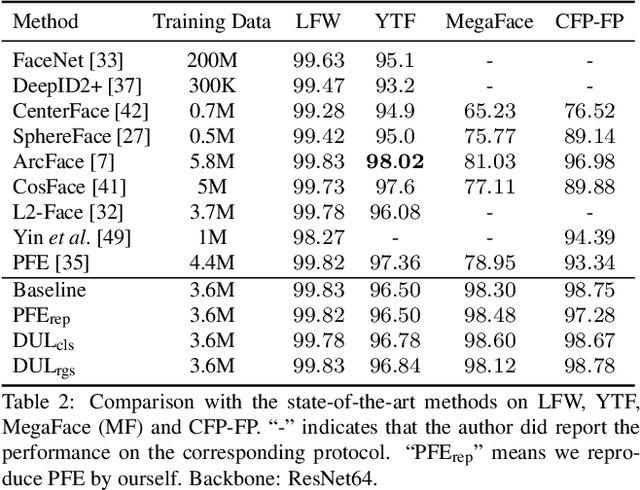
Modeling data uncertainty is important for noisy images, but seldom explored for face recognition. The pioneer work, PFE, considers uncertainty by modeling each face image embedding as a Gaussian distribution. It is quite effective. However, it uses fixed feature (mean of the Gaussian) from an existing model. It only estimates the variance and relies on an ad-hoc and costly metric. Thus, it is not easy to use. It is unclear how uncertainty affects feature learning. This work applies data uncertainty learning to face recognition, such that the feature (mean) and uncertainty (variance) are learnt simultaneously, for the first time. Two learning methods are proposed. They are easy to use and outperform existing deterministic methods as well as PFE on challenging unconstrained scenarios. We also provide insightful analysis on how incorporating uncertainty estimation helps reducing the adverse effects of noisy samples and affects the feature learning.
Circle Loss: A Unified Perspective of Pair Similarity Optimization
Feb 25, 2020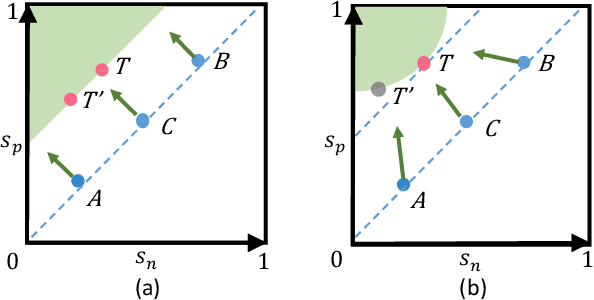
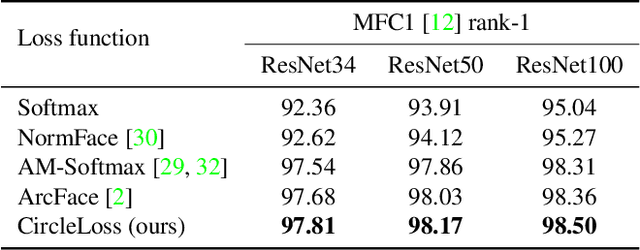

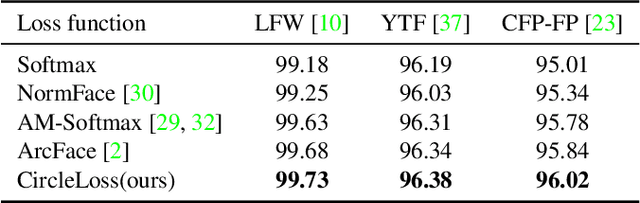
This paper provides a pair similarity optimization viewpoint on deep feature learning, aiming to maximize the within-class similarity $s_p$ and minimize the between-class similarity $s_n$. We find a majority of loss functions, including the triplet loss and the softmax plus cross-entropy loss, embed $s_n$ and $s_p$ into similarity pairs and seek to reduce $(s_n-s_p)$. Such an optimization manner is inflexible, because the penalty strength on every single similarity score is restricted to be equal. Our intuition is that if a similarity score deviates far from the optimum, it should be emphasized. To this end, we simply re-weight each similarity to highlight the less-optimized similarity scores. It results in a Circle loss, which is named due to its circular decision boundary. The Circle loss has a unified formula for two elemental deep feature learning approaches, i.e. learning with class-level labels and pair-wise labels. Analytically, we show that the Circle loss offers a more flexible optimization approach towards a more definite convergence target, compared with the loss functions optimizing $(s_n-s_p)$. Experimentally, we demonstrate the superiority of the Circle loss on a variety of deep feature learning tasks. On face recognition, person re-identification, as well as several fine-grained image retrieval datasets, the achieved performance is on par with the state of the art.
Dual Skipping Networks
May 27, 2018


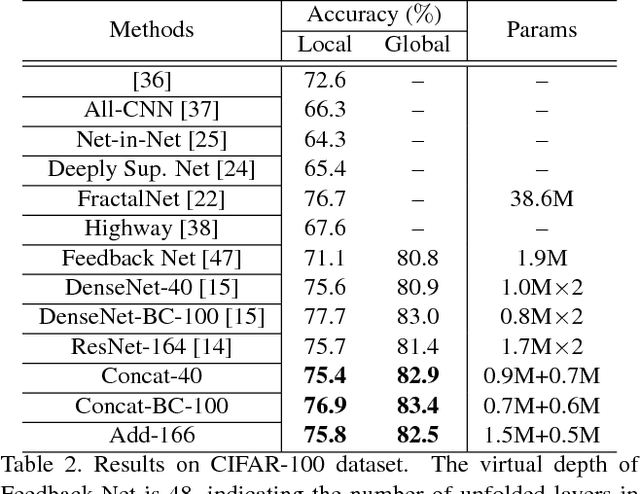
Inspired by the recent neuroscience studies on the left-right asymmetry of the human brain in processing low and high spatial frequency information, this paper introduces a dual skipping network which carries out coarse-to-fine object categorization. Such a network has two branches to simultaneously deal with both coarse and fine-grained classification tasks. Specifically, we propose a layer-skipping mechanism that learns a gating network to predict which layers to skip in the testing stage. This layer-skipping mechanism endows the network with good flexibility and capability in practice. Evaluations are conducted on several widely used coarse-to-fine object categorization benchmarks, and promising results are achieved by our proposed network model.