 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDSE-UNet: Enhancing COVID-19 CT Image Segmentation with Canny Edge Detection and Dual-Path SENet Feature Fusion
Mar 03, 2024Accurate segmentation of COVID-19 CT images is crucial for reducing the severity and mortality rates associated with COVID-19 infections. In response to blurred boundaries and high variability characteristic of lesion areas in COVID-19 CT images, we introduce CDSE-UNet: a novel UNet-based segmentation model that integrates Canny operator edge detection and a dual-path SENet feature fusion mechanism. This model enhances the standard UNet architecture by employing the Canny operator for edge detection in sample images, paralleling this with a similar network structure for semantic feature extraction. A key innovation is the Double SENet Feature Fusion Block, applied across corresponding network layers to effectively combine features from both image paths. Moreover, we have developed a Multiscale Convolution approach, replacing the standard Convolution in UNet, to adapt to the varied lesion sizes and shapes. This addition not only aids in accurately classifying lesion edge pixels but also significantly improves channel differentiation and expands the capacity of the model. Our evaluations on public datasets demonstrate CDSE-UNet's superior performance over other leading models, particularly in segmenting large and small lesion areas, accurately delineating lesion edges, and effectively suppressing noise
Prime-Aware Adaptive Distillation
Aug 04, 2020
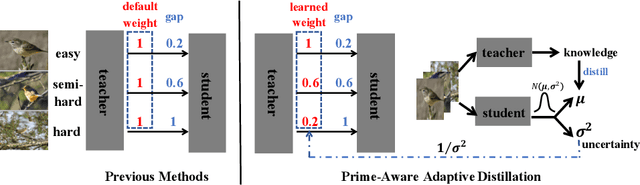
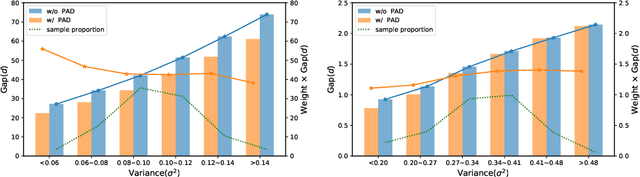

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.
Data Uncertainty Learning in Face Recognition
Mar 25, 2020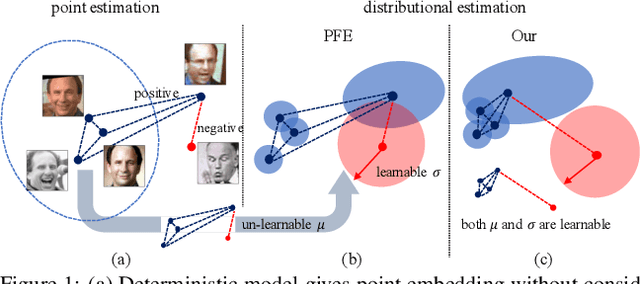
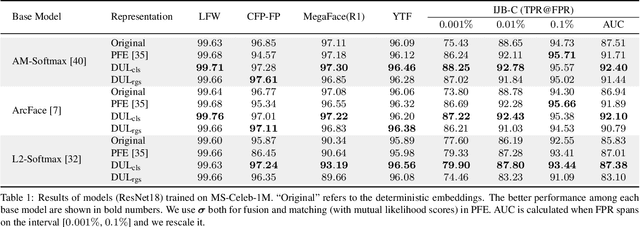

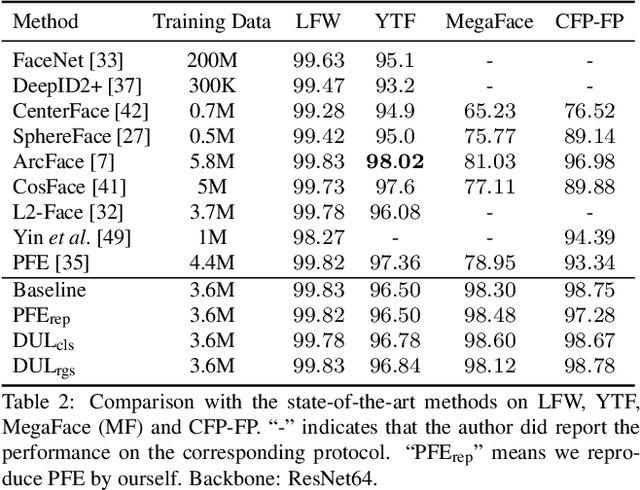
Modeling data uncertainty is important for noisy images, but seldom explored for face recognition. The pioneer work, PFE, considers uncertainty by modeling each face image embedding as a Gaussian distribution. It is quite effective. However, it uses fixed feature (mean of the Gaussian) from an existing model. It only estimates the variance and relies on an ad-hoc and costly metric. Thus, it is not easy to use. It is unclear how uncertainty affects feature learning. This work applies data uncertainty learning to face recognition, such that the feature (mean) and uncertainty (variance) are learnt simultaneously, for the first time. Two learning methods are proposed. They are easy to use and outperform existing deterministic methods as well as PFE on challenging unconstrained scenarios. We also provide insightful analysis on how incorporating uncertainty estimation helps reducing the adverse effects of noisy samples and affects the feature learning.
Handwritten Chinese Font Generation with Collaborative Stroke Refinement
May 06, 2019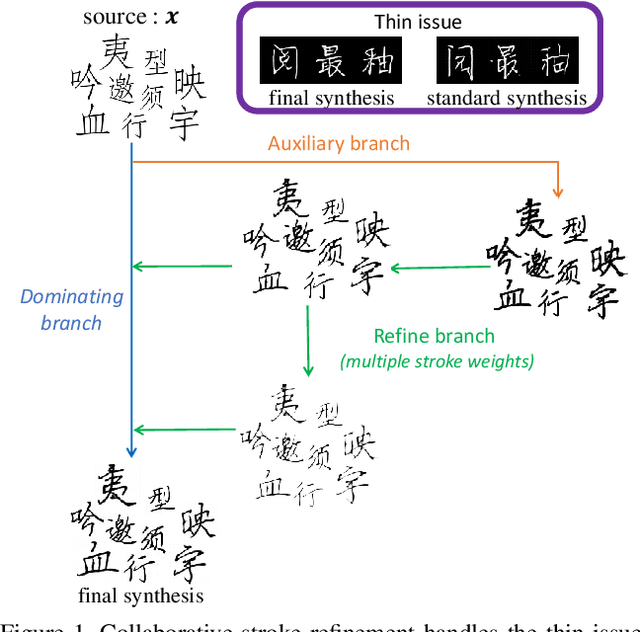
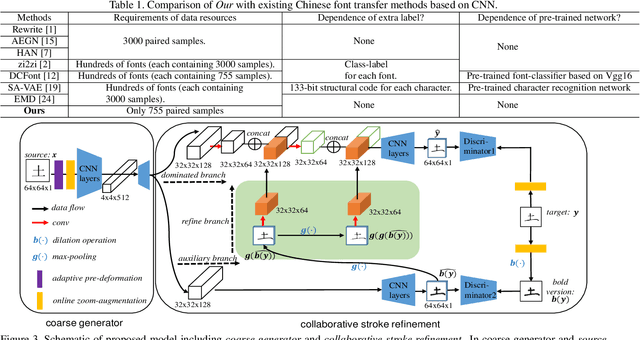
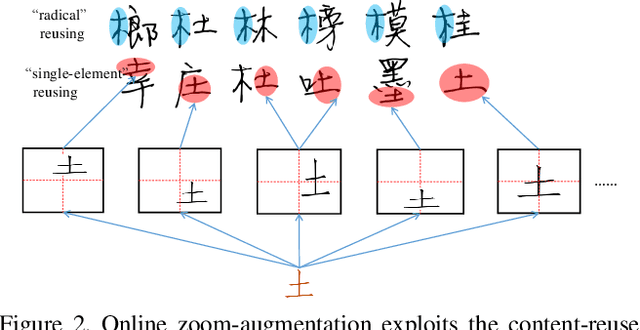

Automatic character generation is an appealing solution for new typeface design, especially for Chinese typefaces including over 3700 most commonly-used characters. This task has two main pain points: (i) handwritten characters are usually associated with thin strokes of few information and complex structure which are error prone during deformation; (ii) thousands of characters with various shapes are needed to synthesize based on a few manually designed characters. To solve those issues, we propose a novel convolutional-neural-network-based model with three main techniques: collaborative stroke refinement, using collaborative training strategy to recover the missing or broken strokes; online zoom-augmentation, taking the advantage of the content-reuse phenomenon to reduce the size of training set; and adaptive pre-deformation, standardizing and aligning the characters. The proposed model needs only 750 paired training samples; no pre-trained network, extra dataset resource or labels is needed. Experimental results show that the proposed method significantly outperforms the state-of-the-art methods under the practical restriction on handwritten font synthesis.
An Element Sensitive Saliency Model with Position Prior Learning for Web Pages
Nov 03, 2018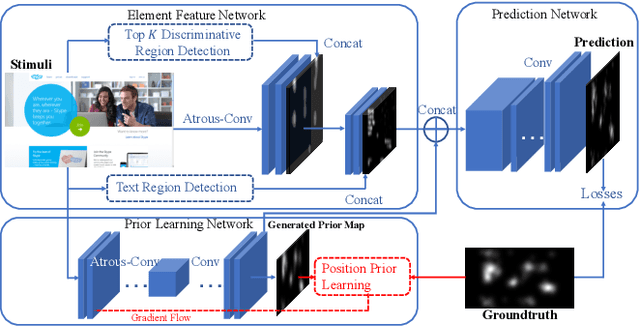
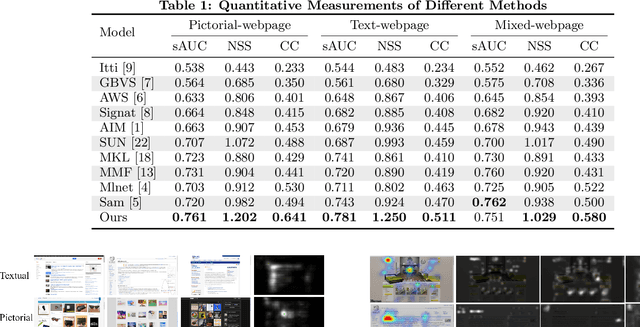
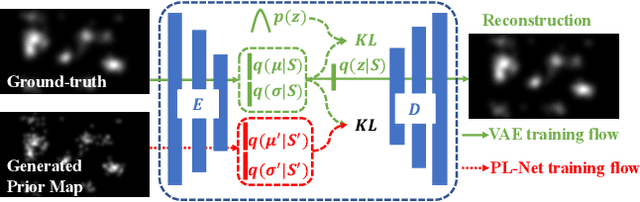

Understanding human visual attention is important for multimedia applications. Many studies have attempted to learn from eye-tracking data and build computational saliency prediction models. However, limited efforts have been devoted to saliency prediction for Web pages, which are characterized by more diverse content elements and spatial layouts. In this paper, we propose a novel end-to-end deep generative saliency model for Web pages. To capture position biases introduced by page layouts, a Position Prior Learning sub-network is proposed, which models position biases as multivariate Gaussian distribution using variational auto-encoder. To model different elements of a Web page, a Multi Discriminative Region Detection (MDRD) branch and a Text Region Detection(TRD) branch are introduced, which target to extract discriminative localizations and "prominent" text regions likely to correspond to human attention, respectively. We validate the proposed model with FiWI, a public Web-page dataset, and shows that the proposed model outperforms the state-of-art models for Web-page saliency prediction.
Separating Style and Content for Generalized Style Transfer
Sep 23, 2018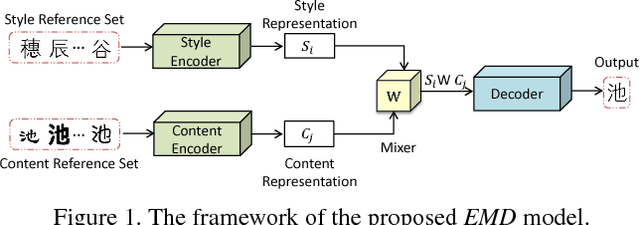
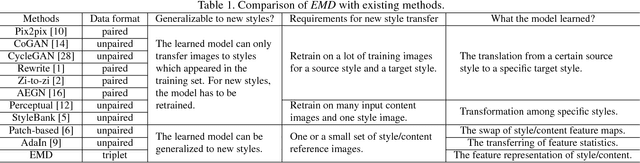
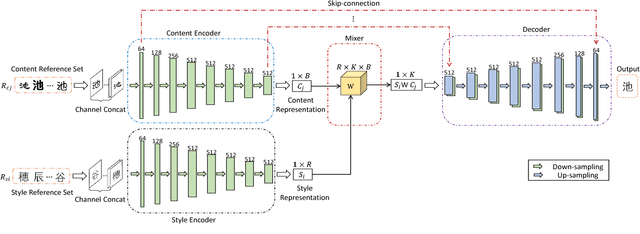
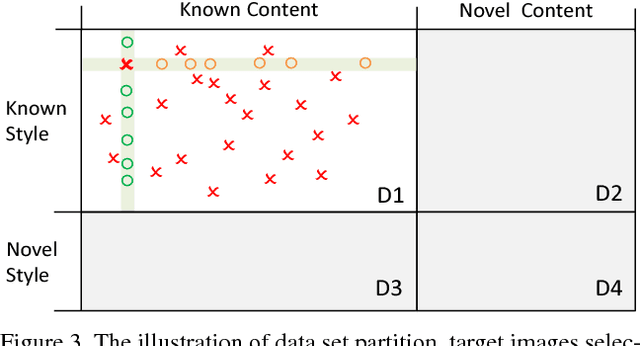
Neural style transfer has drawn broad attention in recent years. However, most existing methods aim to explicitly model the transformation between different styles, and the learned model is thus not generalizable to new styles. We here attempt to separate the representations for styles and contents, and propose a generalized style transfer network consisting of style encoder, content encoder, mixer and decoder. The style encoder and content encoder are used to extract the style and content factors from the style reference images and content reference images, respectively. The mixer employs a bilinear model to integrate the above two factors and finally feeds it into a decoder to generate images with target style and content. To separate the style features and content features, we leverage the conditional dependence of styles and contents given an image. During training, the encoder network learns to extract styles and contents from two sets of reference images in limited size, one with shared style and the other with shared content. This learning framework allows simultaneous style transfer among multiple styles and can be deemed as a special `multi-task' learning scenario. The encoders are expected to capture the underlying features for different styles and contents which is generalizable to new styles and contents. For validation, we applied the proposed algorithm to the Chinese Typeface transfer problem. Extensive experiment results on character generation have demonstrated the effectiveness and robustness of our method.
Chinese Typeface Transformation with Hierarchical Adversarial Network
Nov 17, 2017

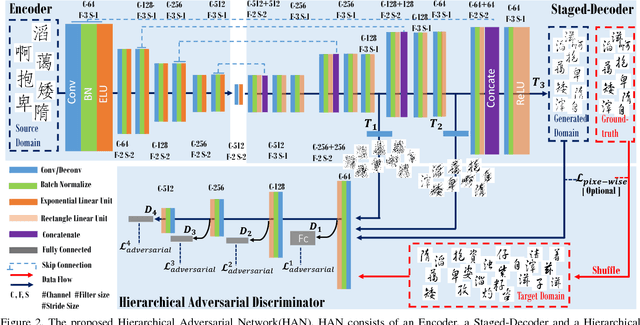
In this paper, we explore automated typeface generation through image style transfer which has shown great promise in natural image generation. Existing style transfer methods for natural images generally assume that the source and target images share similar high-frequency features. However, this assumption is no longer true in typeface transformation. Inspired by the recent advancement in Generative Adversarial Networks (GANs), we propose a Hierarchical Adversarial Network (HAN) for typeface transformation. The proposed HAN consists of two sub-networks: a transfer network and a hierarchical adversarial discriminator. The transfer network maps characters from one typeface to another. A unique characteristic of typefaces is that the same radicals may have quite different appearances in different characters even under the same typeface. Hence, a stage-decoder is employed by the transfer network to leverage multiple feature layers, aiming to capture both the global and local features. The hierarchical adversarial discriminator implicitly measures data discrepancy between the generated domain and the target domain. To leverage the complementary discriminating capability of different feature layers, a hierarchical structure is proposed for the discriminator. We have experimentally demonstrated that HAN is an effective framework for typeface transfer and characters restoration.
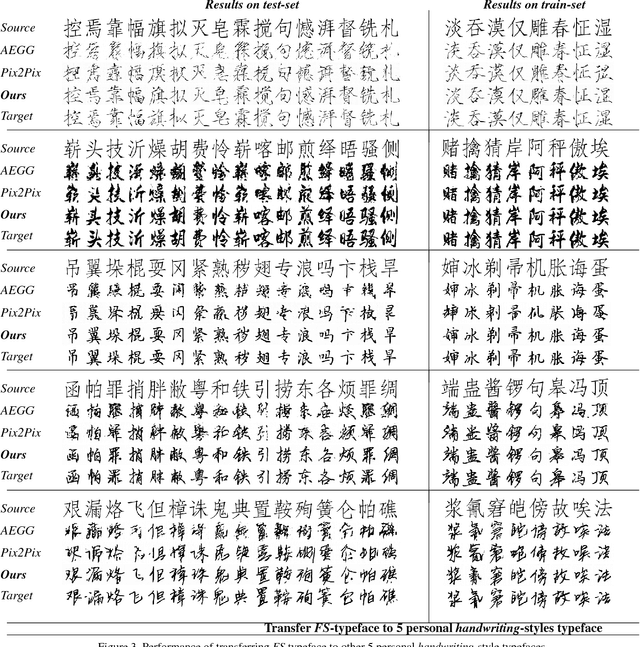
Chinese Typography Transfer
Aug 02, 2017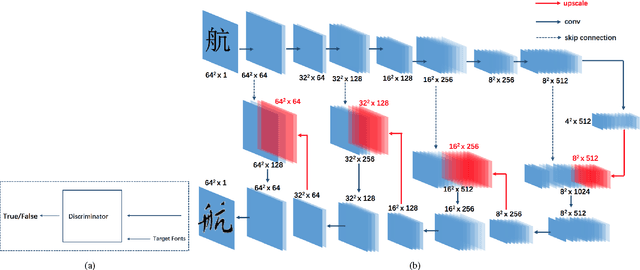



In this paper, we propose a new network architecture for Chinese typography transformation based on deep learning. The architecture consists of two sub-networks: (1)a fully convolutional network(FCN) aiming at transferring specified typography style to another in condition of preserving structure information; (2)an adversarial network aiming at generating more realistic strokes in some details. Unlike models proposed before 2012 relying on the complex segmentation of Chinese components or strokes, our model treats every Chinese character as an inseparable image, so pre-processing or post-preprocessing are abandoned. Besides, our model adopts end-to-end training without pre-trained used in other deep models. The experiments demonstrates that our model can synthesize realistic-looking target typography from any source typography both on printed style and handwriting style.