 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Element Sensitive Saliency Model with Position Prior Learning for Web Pages
Nov 03, 2018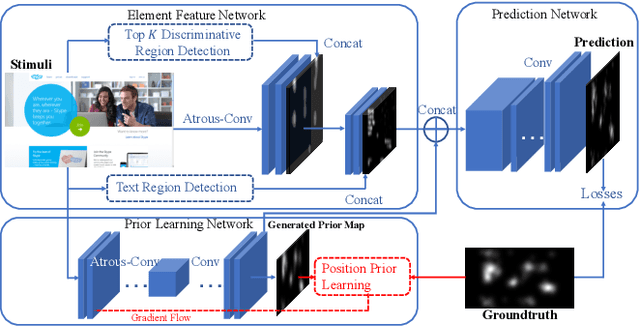
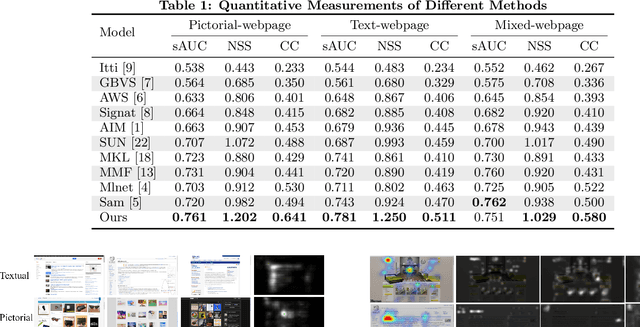
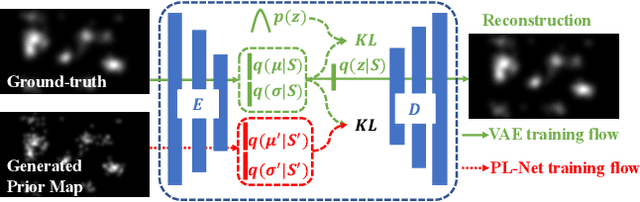

Understanding human visual attention is important for multimedia applications. Many studies have attempted to learn from eye-tracking data and build computational saliency prediction models. However, limited efforts have been devoted to saliency prediction for Web pages, which are characterized by more diverse content elements and spatial layouts. In this paper, we propose a novel end-to-end deep generative saliency model for Web pages. To capture position biases introduced by page layouts, a Position Prior Learning sub-network is proposed, which models position biases as multivariate Gaussian distribution using variational auto-encoder. To model different elements of a Web page, a Multi Discriminative Region Detection (MDRD) branch and a Text Region Detection(TRD) branch are introduced, which target to extract discriminative localizations and "prominent" text regions likely to correspond to human attention, respectively. We validate the proposed model with FiWI, a public Web-page dataset, and shows that the proposed model outperforms the state-of-art models for Web-page saliency prediction.
Chinese Typeface Transformation with Hierarchical Adversarial Network
Nov 17, 2017

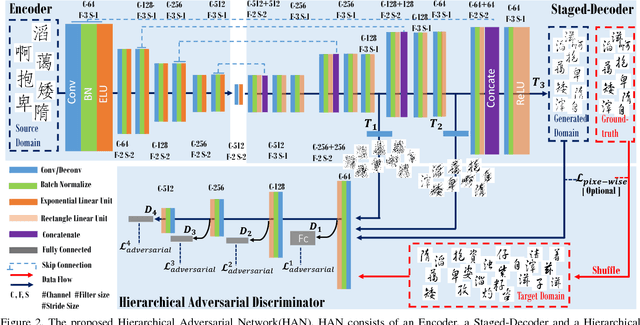
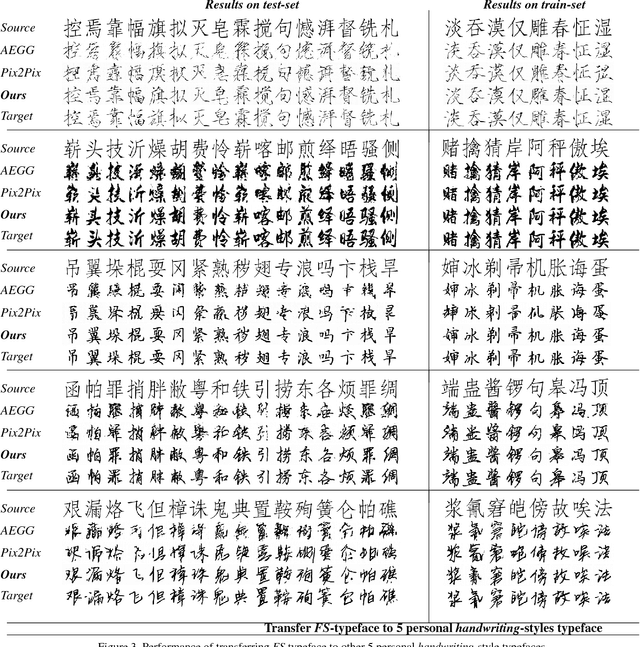
In this paper, we explore automated typeface generation through image style transfer which has shown great promise in natural image generation. Existing style transfer methods for natural images generally assume that the source and target images share similar high-frequency features. However, this assumption is no longer true in typeface transformation. Inspired by the recent advancement in Generative Adversarial Networks (GANs), we propose a Hierarchical Adversarial Network (HAN) for typeface transformation. The proposed HAN consists of two sub-networks: a transfer network and a hierarchical adversarial discriminator. The transfer network maps characters from one typeface to another. A unique characteristic of typefaces is that the same radicals may have quite different appearances in different characters even under the same typeface. Hence, a stage-decoder is employed by the transfer network to leverage multiple feature layers, aiming to capture both the global and local features. The hierarchical adversarial discriminator implicitly measures data discrepancy between the generated domain and the target domain. To leverage the complementary discriminating capability of different feature layers, a hierarchical structure is proposed for the discriminator. We have experimentally demonstrated that HAN is an effective framework for typeface transfer and characters restoration.
Clothing Retrieval with Visual Attention Model
Oct 31, 2017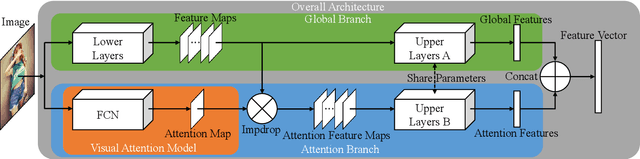



Clothing retrieval is a challenging problem in computer vision. With the advance of Convolutional Neural Networks (CNNs), the accuracy of clothing retrieval has been significantly improved. FashionNet[1], a recent study, proposes to employ a set of artificial features in the form of landmarks for clothing retrieval, which are shown to be helpful for retrieval. However, the landmark detection module is trained with strong supervision which requires considerable efforts to obtain. In this paper, we propose a self-learning Visual Attention Model (VAM) to extract attention maps from clothing images. The VAM is further connected to a global network to form an end-to-end network structure through Impdrop connection which randomly Dropout on the feature maps with the probabilities given by the attention map. Extensive experiments on several widely used benchmark clothing retrieval data sets have demonstrated the promise of the proposed method. We also show that compared to the trivial Product connection, the Impdrop connection makes the network structure more robust when training sets of limited size are used.
Chinese Typography Transfer
Aug 02, 2017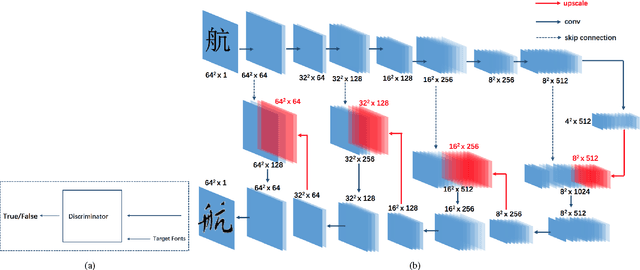



In this paper, we propose a new network architecture for Chinese typography transformation based on deep learning. The architecture consists of two sub-networks: (1)a fully convolutional network(FCN) aiming at transferring specified typography style to another in condition of preserving structure information; (2)an adversarial network aiming at generating more realistic strokes in some details. Unlike models proposed before 2012 relying on the complex segmentation of Chinese components or strokes, our model treats every Chinese character as an inseparable image, so pre-processing or post-preprocessing are abandoned. Besides, our model adopts end-to-end training without pre-trained used in other deep models. The experiments demonstrates that our model can synthesize realistic-looking target typography from any source typography both on printed style and handwriting style.