 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Adversarial Learning for Unsupervised Domain Adaption
Nov 30, 2018



Unsupervised domain adaption aims to learn a powerful classifier for the target domain given a labeled source data set and an unlabeled target data set. To alleviate the effect of `domain shift', the major challenge in domain adaptation, studies have attempted to align the distributions of the two domains. Recent research has suggested that generative adversarial network (GAN) has the capability of implicitly capturing data distribution. In this paper, we thus propose a simple but effective model for unsupervised domain adaption leveraging adversarial learning. The same encoder is shared between the source and target domains which is expected to extract domain-invariant representations with the help of an adversarial discriminator. With the labeled source data, we introduce the center loss to increase the discriminative power of feature learned. We further align the conditional distribution of the two domains to enforce the discrimination of the features in the target domain. Unlike previous studies where the source features are extracted with a fixed pre-trained encoder, our method jointly learns feature representations of two domains. Moreover, by sharing the encoder, the model does not need to know the source of images during testing and hence is more widely applicable. We evaluate the proposed method on several unsupervised domain adaption benchmarks and achieve superior or comparable performance to state-of-the-art results.
Separating Style and Content for Generalized Style Transfer
Sep 23, 2018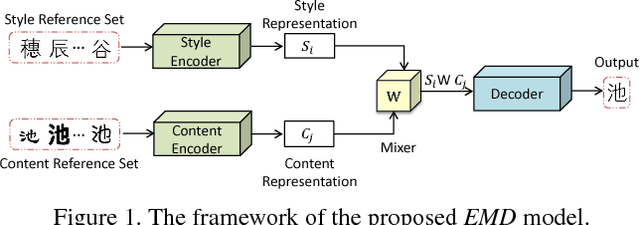
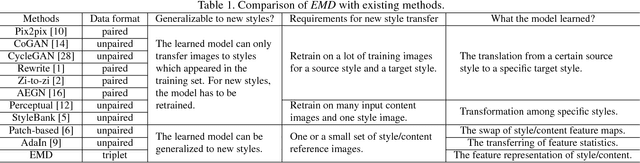
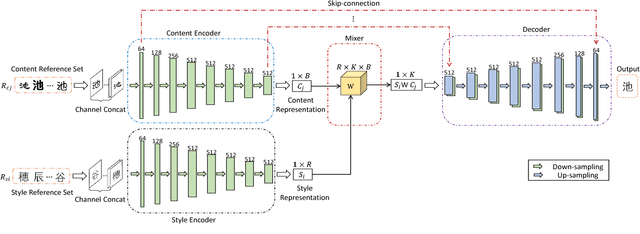
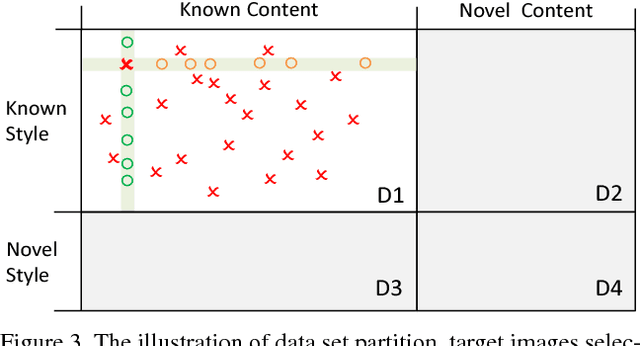
Neural style transfer has drawn broad attention in recent years. However, most existing methods aim to explicitly model the transformation between different styles, and the learned model is thus not generalizable to new styles. We here attempt to separate the representations for styles and contents, and propose a generalized style transfer network consisting of style encoder, content encoder, mixer and decoder. The style encoder and content encoder are used to extract the style and content factors from the style reference images and content reference images, respectively. The mixer employs a bilinear model to integrate the above two factors and finally feeds it into a decoder to generate images with target style and content. To separate the style features and content features, we leverage the conditional dependence of styles and contents given an image. During training, the encoder network learns to extract styles and contents from two sets of reference images in limited size, one with shared style and the other with shared content. This learning framework allows simultaneous style transfer among multiple styles and can be deemed as a special `multi-task' learning scenario. The encoders are expected to capture the underlying features for different styles and contents which is generalizable to new styles and contents. For validation, we applied the proposed algorithm to the Chinese Typeface transfer problem. Extensive experiment results on character generation have demonstrated the effectiveness and robustness of our method.
A Unified Framework for Generalizable Style Transfer: Style and Content Separation
Jun 13, 2018



Image style transfer has drawn broad attention in recent years. However, most existing methods aim to explicitly model the transformation between different styles, and the learned model is thus not generalizable to new styles. We here propose a unified style transfer framework for both character typeface transfer and neural style transfer tasks leveraging style and content separation. A key merit of such framework is its generalizability to new styles and contents. The overall framework consists of style encoder, content encoder, mixer and decoder. The style encoder and content encoder are used to extract the style and content representations from the corresponding reference images. The mixer integrates the above two representations and feeds it into the decoder to generate images with the target style and content. During training, the encoder networks learn to extract styles and contents from limited size of style/content reference images. This learning framework allows simultaneous style transfer among multiple styles and can be deemed as a special `multi-task' learning scenario. The encoders are expected to capture the underlying features for different styles and contents which is generalizable to new styles and contents. Under this framework, we design two individual networks for character typeface transfer and neural style transfer, respectively. For character typeface transfer, to separate the style features and content features, we leverage the conditional dependence of styles and contents given an image. For neural style transfer, we leverage the statistical information of feature maps in certain layers to represent style. Extensive experimental results have demonstrated the effectiveness and robustness of the proposed methods.